How to Build AI Agents That Pass Enterprise Security and Trust Reviews
Getting an AI agent through an enterprise security and trust review is fundamentally different from getting a traditional application approved. Security teams and model risk organizations (MROs) aren't just evaluating whether your agent works…they're evaluating whether it's controllable, observable, and auditable when it inevitably behaves in ways you didn't expect.
Most rejections happen because teams can't answer basic questions: What exactly does this agent do at each step? What happens when the agent gets something wrong? How do you know it's not leaking sensitive data? Who owns the data, and what model is running underneath?
This guide walks through the practical engineering and governance practices that answer those questions. It's based on lessons from Arthur's Forward Deployed Engineering team, drawn from real-world deployments of production agents across industries, from airlines to financial services to healthcare. Each section links to a deeper technical resource so you can go further on the topics that matter most to your team
.1. Start with End-to-End Observability and Tracing
The single most important thing you can do to prepare an agent for enterprise security review is to instrument it with tracing from day one. Without it, you're asking a security team to trust a black box.
Tracing gives you full visibility into what your agent does at every step: which LLM it called, what prompt it sent, which tools it invoked, what data it retrieved, and what it returned to the user. This isn't just useful for debugging. It's the foundation for every other practice in this guide: evaluations, guardrails, prompt management, and governance all depend on having a detailed record of agent behavior.
OpenTelemetry has emerged as the standard for vendor-neutral observability. Its biggest advantage is portability: you emit traces once and choose any compatible backend without re-instrumenting your code. This matters because agents rarely live in isolation; they span services, APIs, databases, and often other agents. OpenTelemetry's distributed tracing model lets you follow an agent execution end to end, even as it crosses system boundaries.
Within OpenTelemetry, there are two competing semantic conventions for encoding agent behavior into spans: the OTEL-community GenAI semantic conventions and the open-source OpenInference standard. When building the Arthur platform, we chose OpenInference because it offers richer semantic detail for production agent workloads including first-class support for retrieval and re-ranking spans, explicit types for messages, documents, tools, and tool calls, and better distinctions between different span types (LLM, TOOL, AGENT, CHAIN, RETRIEVER, and more).
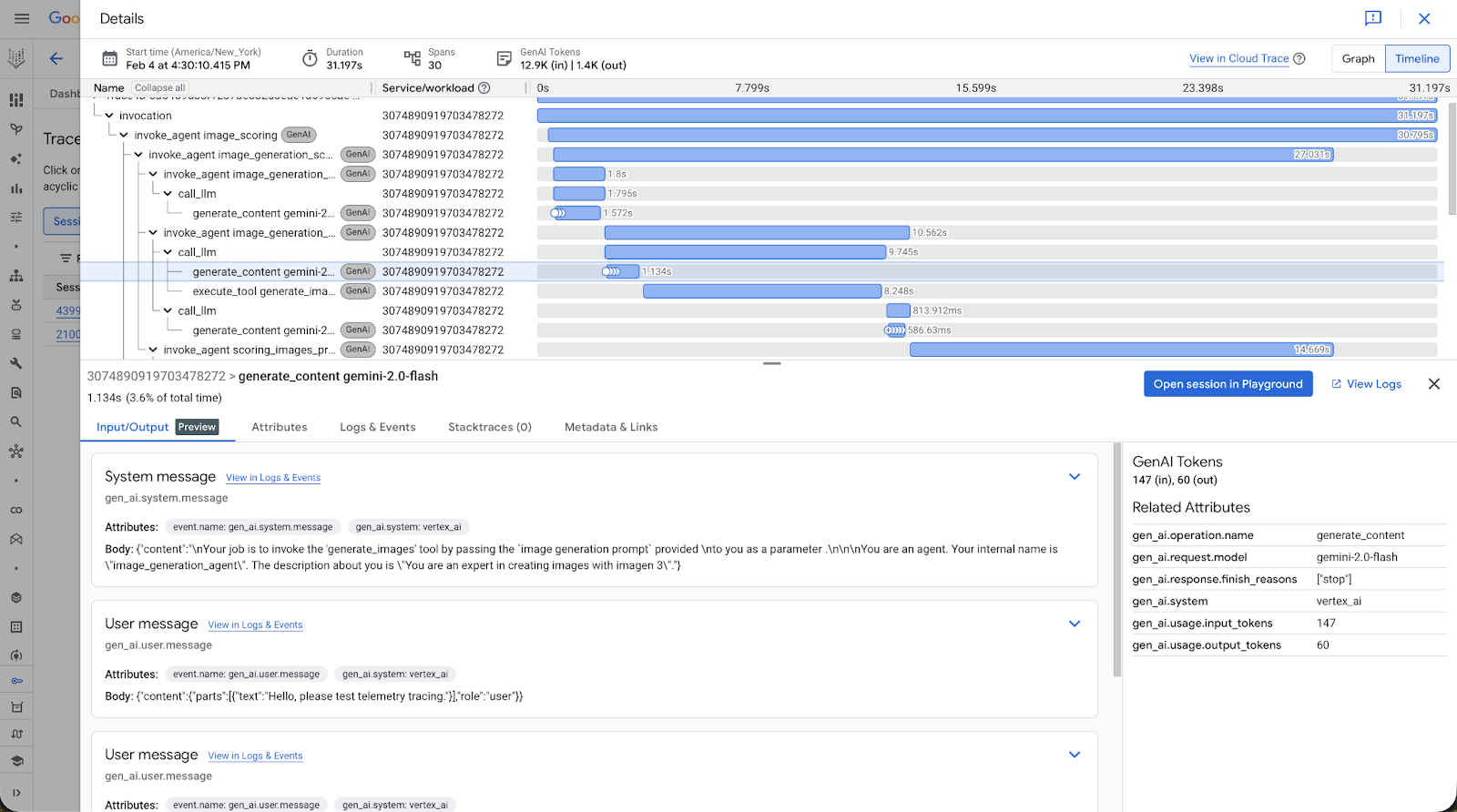
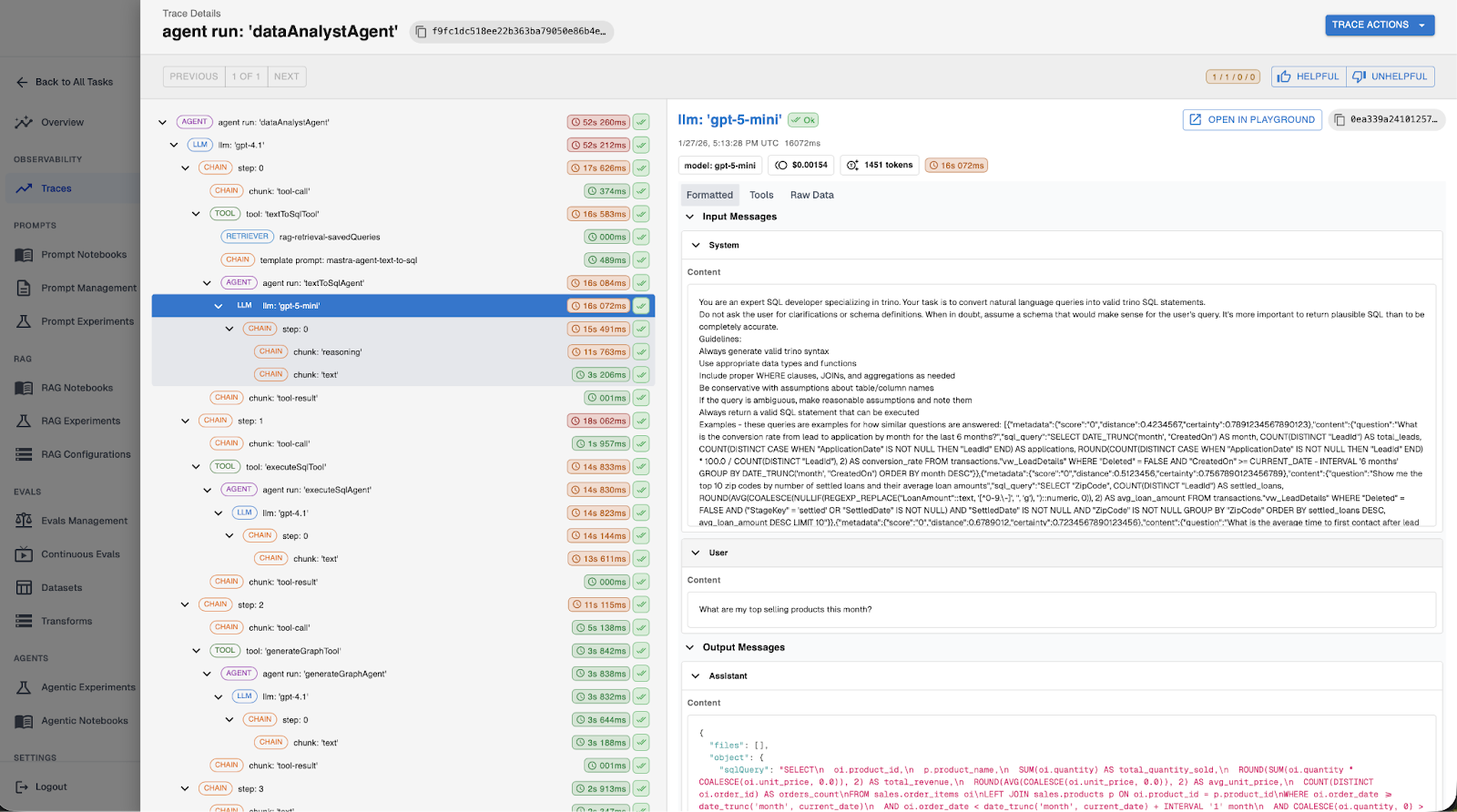
What to trace. At minimum, instrument these five areas:
- LLM calls: Every interaction with full context - prompts, completions, model configuration, token counts, and cost. Without this, debugging unexpected outputs or reasoning about performance tradeoffs is nearly impossible.
- Tool invocations: When an agent calls an API, queries a database, or executes code, capture inputs, outputs, and latency. Many performance issues come down to inefficient tool usage that only becomes obvious when laid out in a trace.
- RAG calls: Agents often take wrong actions because they had bad context. Tracing retrieval calls lets you see exactly which documents were pulled - and often more importantly, which documents were not and why the model acted on them.
- Application metadata: User IDs, session IDs, and domain identifiers connect agent behavior back to real user experiences. When a customer reports an issue, pulling up the exact traces for their session dramatically shortens time to resolution.
- Key decision points: Make sure spans include key decision points or context important for the agent to function correctly. These logged decision points become the basis for building test datasets and continuous evals that validate behavior in production.
Most common agent frameworks have great auto-instrumentation packages for OpenTelemetry. Adding OpenInference tracing to Google's ADK, for example, takes just a few lines of code. Mastra, AWS Strands, and CrewAI all provide strong out-of-the-box support as well.
Deep Dive: Best Practices for Building Agents | Part 1: Observability and Tracing
2. Implement Pre-LLM and Post-LLM Guardrails
Security reviewers want to know two things about your agent's data flow: What goes into the model, and what comes out? Guardrails are the runtime controls that answer both questions: they intercept agent behavior in real time, before a bad input reaches your LLM or a bad output reaches your user.
There are two types, and production agents typically need both.
Pre-LLM guardrails run before the user's input and assembled context is sent to the model. They handle:
- PII detection and redaction: Strip sensitive personal and company information before it leaves your environment and is transmitted to an external model provider.
- Sensitive data blocking: Prevent credit card numbers, credentials, or proprietary internal data from being included in LLM context.
- Prompt injection detection: Identify malicious input designed to override the agent's system prompt or hijack its behavior before it reaches the model.
A major transportation company we work with uses pre-LLM guardrails to redact PII from customer support conversations before they ever leave the corporate environment. Every conversation passes through PII detection before anything is sent to the model. Identified PII is automatically redacted, ensuring sensitive customer data never reaches an external model provider. For their compliance team, this guardrail was non-negotiable before the agent could go to production.
Post-LLM guardrails run after the model returns a response, before that response is acted on or returned to the user. They handle hallucination detection, toxicity filtering, tool and action validation, and output format compliance.
The most powerful pattern for post-LLM guardrails is using them as a self-correction loop. Instead of simply blocking a bad response, the system feeds the flagged issues back to the LLM with a targeted correction prompt: here is what you said, here is what was unsupported, revise your response. The agent retries, and the corrected output goes through the guardrail again. This repeats until the response passes or a retry limit is hit.
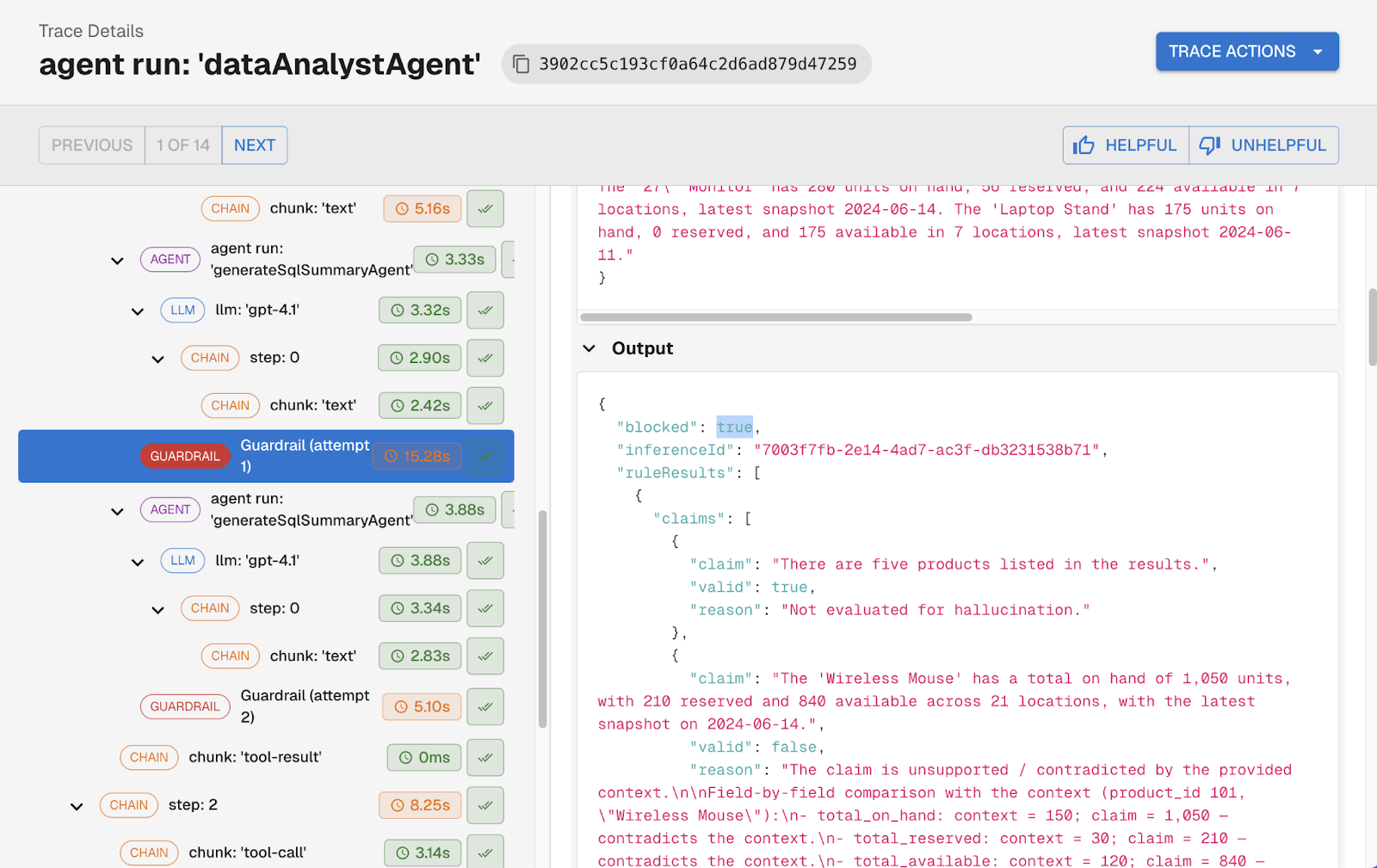
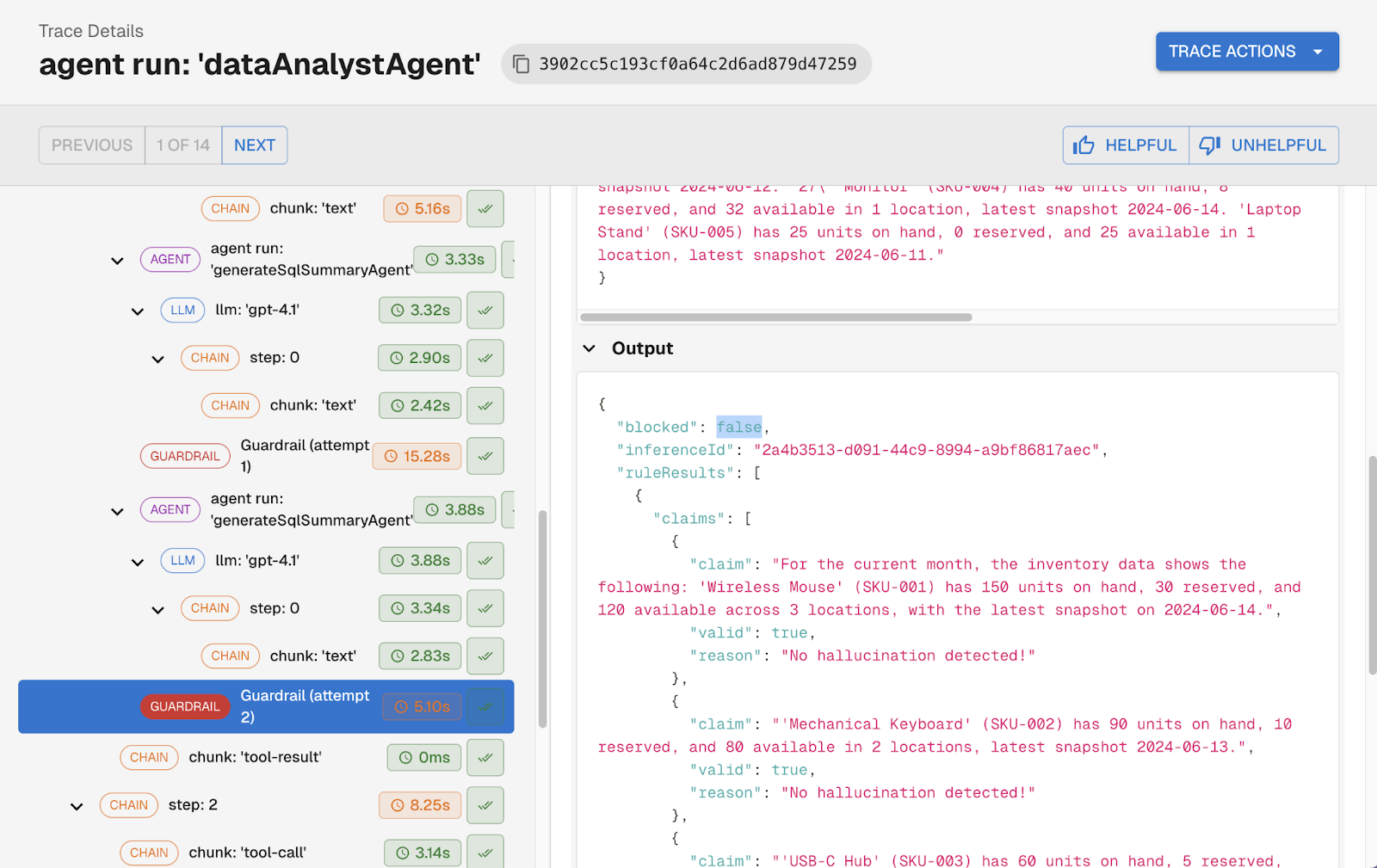
Another customer puts this pattern to work by checking every response for claims that aren't explicitly supported by the agent's context. When the guardrail finds an unsupported claim, it isolates that specific statement, sends it back to the LLM with a correction request, and runs the check again. The user only receives a response where every factual claim is grounded in what the agent actually knew.
Best practices for guardrails:
- Treat guardrails as first-class execution logic - they belong in the agent loop, not as an afterthought.
- Keep pre-LLM guardrails fast and deterministic. Regex-based PII detection and rule-based injection checks add minimal latency.
- Be deliberate about post-LLM guardrail cost. Hallucination and toxicity checks that use a model to assess output add latency and cost per request. Scope them to what actually requires that level of judgment.
- Emit guardrail interventions as telemetry. Every guardrail trigger should produce a trace event, letting you see how often each guardrail fires and what it catches.
- Monitor guardrail pass/fail rates over time. A sudden spike in PII detections or hallucination failures is a signal worth investigating before users report it.
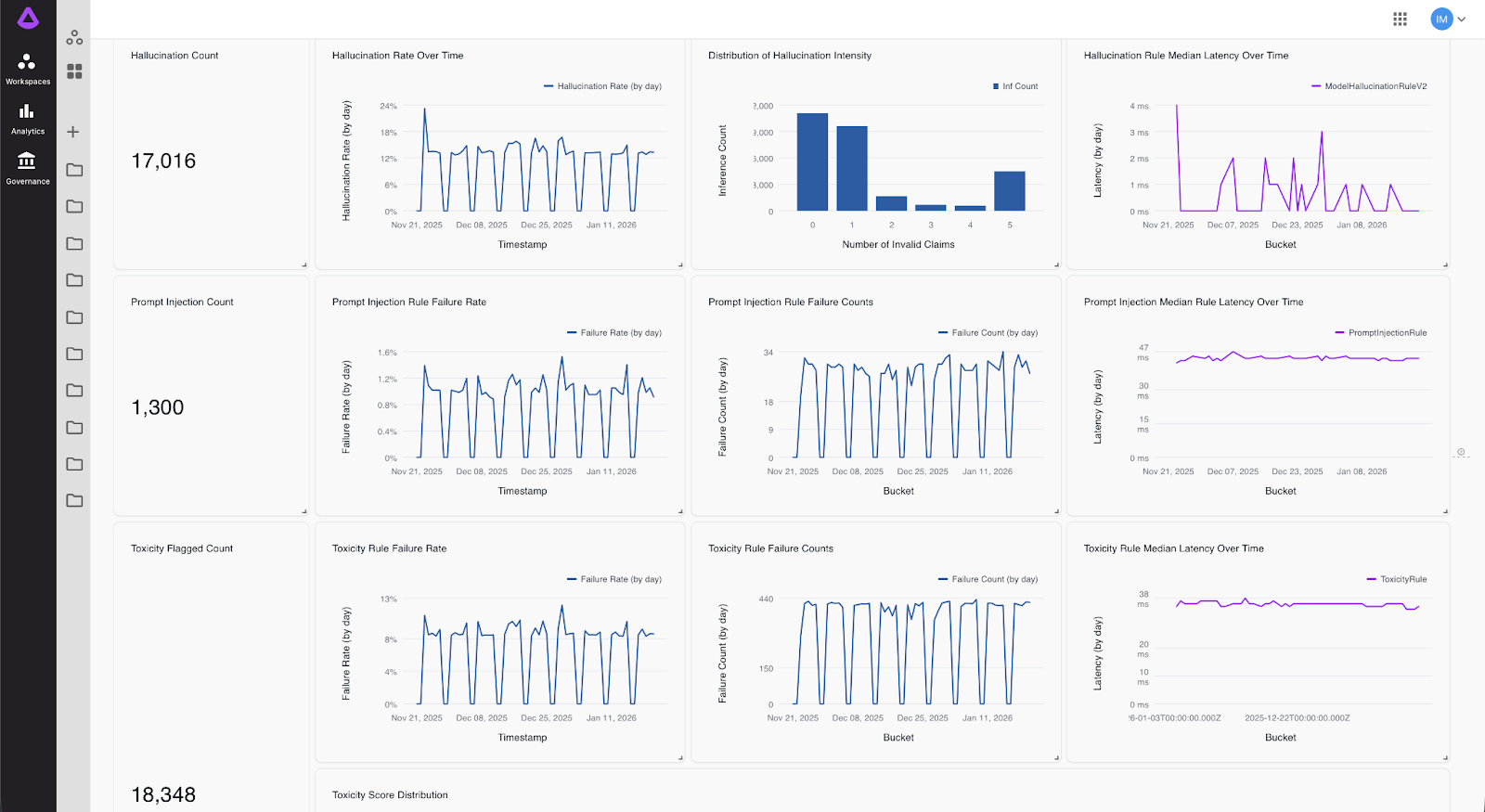
Deep dive: Best Practices for Building Agents | Part 5: Guardrails
3. Run Continuous Evaluations Against Production Traffic
Unit tests are necessary but not sufficient for agentic applications. Agents are non-deterministic — an agent that passes a test suite today may fail the same cases tomorrow. And the domain of inputs in production is far more diverse than any handwritten test set can cover. Enterprise security reviewers want to see that you have ongoing quality monitoring, not just pre-deployment checks.
Continuous evaluations are automated checks that run against your agent's production interactions to detect behavioral issues before your users do. They are the difference between finding out about a problem from a user complaint and catching it the moment it emerges.
The key distinction is between supervised and unsupervised evals. Supervised evals require knowing the correct answer ahead of time, which makes them useful for pre-production testing but impossible to run continuously in production where inputs change with every interaction. Unsupervised evals assess behavior using only the information available in the agent's own context, no expected output required. That means they can run against every production interaction.
Common unsupervised evals include:
- Hallucination: Did the agent state facts not supported by the context it had access to?
- Answer completeness: Did the agent address all aspects of the user's question?
- Topic adherence: Did the agent respond to questions outside the topics defined by its system prompt?
- Goal accuracy: Did the agent call the right tools to fulfill the user's intent?
Best practices for building evals:
- Score binary pass/fail, not on a range. Ranges like 1–10 push the judgment burden onto a human, and LLMs are inconsistent scorers…the same interaction might return a 4 on one run and a 6 on another. Binary evals are reliable enough to make the judgment call on their own.
- Provide examples in eval prompts, specifically examples that capture edge-cases or decision boundaries. This dramatically improves eval consistency.
- Choose the right model for cost vs. accuracy. Not every eval needs your most expensive model.
Two approaches to handling eval failures in production: one customer surfaces eval results directly to their end users as a transparency feature, giving their enterprise buyers confidence that agents are performing reliably. Another customer built evals targeting specific failure modes their users had reported, so regressions get caught before anyone files a complaint. Earlier-stage teams often use eval failures as a triage mechanism - queuing interactions for human review rather than alerting immediately.
Deep dive: Best Practices for Building Agents | Part 3: Continuous Evaluations
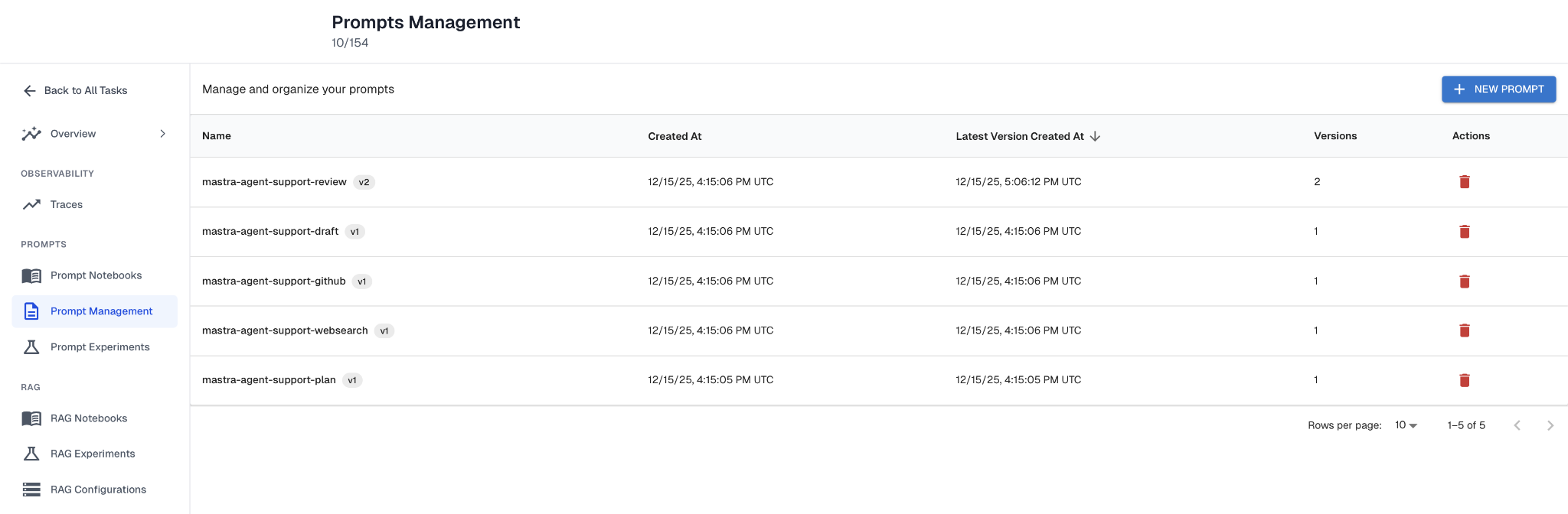
4. Treat Prompts as Managed, Versioned Artifacts
Enterprise security reviews ask about change management. Who can change the agent's behavior? How are changes tracked? Can you roll back if something goes wrong?
If your prompts are hardcoded in application code, the honest answer to those questions is uncomfortable. Most teams start by embedding prompts directly in code. That works for demos. It breaks at scale for several reasons: small edits silently alter behavior with no clear history, updating a prompt requires a full application redeploy, dev/staging/prod prompts diverge with no clean promotion path, and prompts can't be tested independently.
Mature prompt management treats prompts as first-class operational artifacts with four requirements:
External storage. Prompts should live outside your application code. This separates behavioral iteration from application release cycles. Teams can refine prompts without modifying the core agent runtime, and it broadens who can contribute to agent improvement — product managers and customer success teams can safely adjust prompts through a management UI instead of relying entirely on engineering.
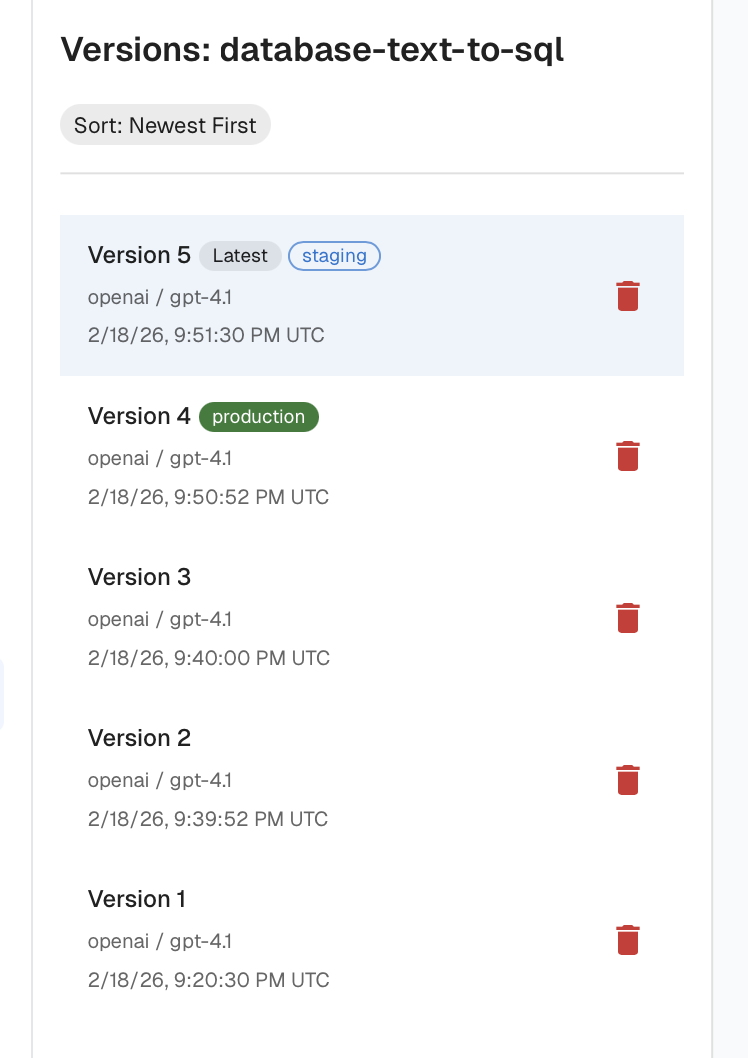
Versioning and rollback. Every prompt should have explicit versions, clear change history, and environment tagging (dev, staging, prod). Tagging lets teams develop new prompt versions in isolation, promote them to production without modifying the codebase, and quickly roll back if performance declines.
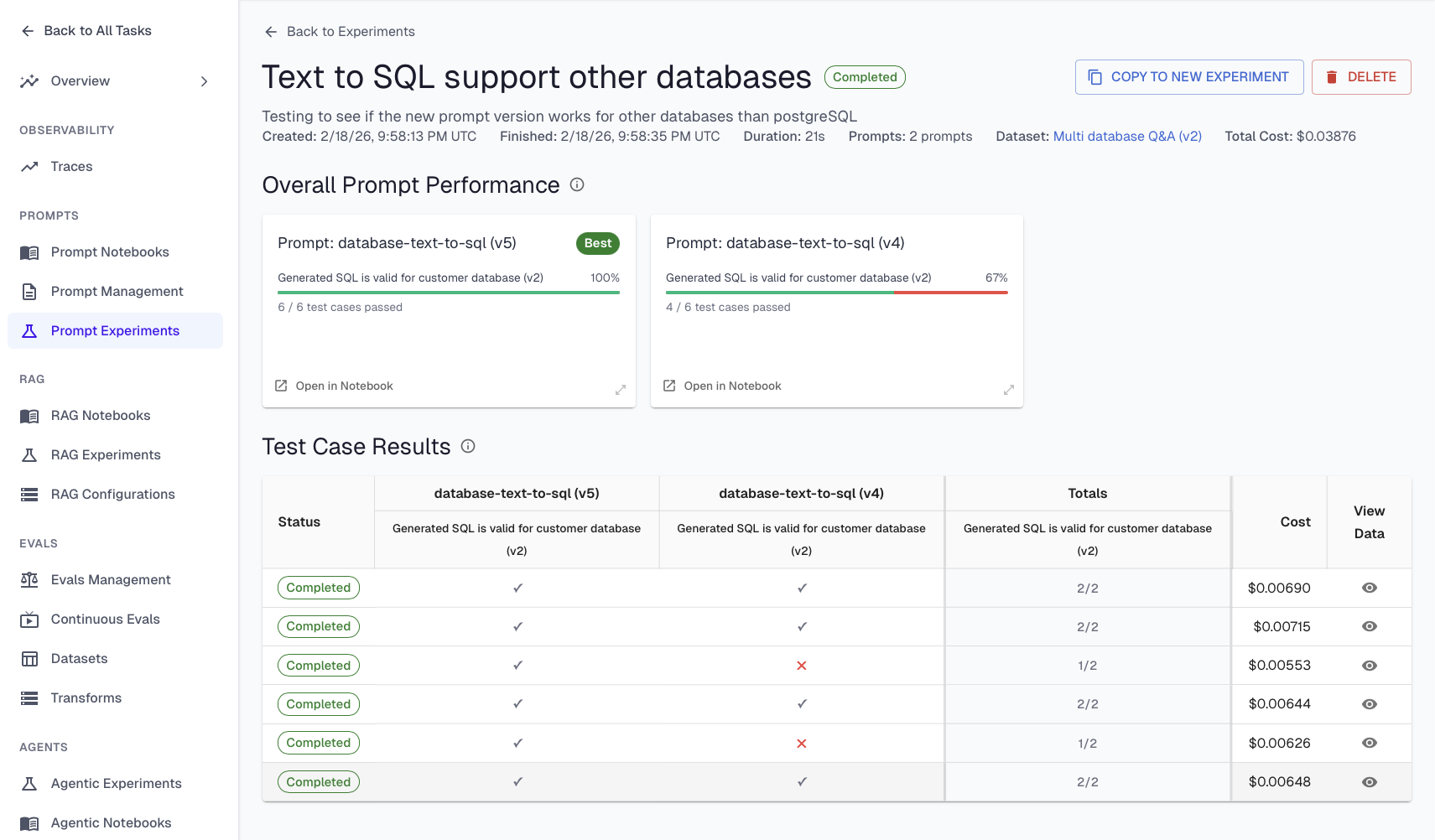
Templating. Static prompts don't scale to production agents. A mature templating system supports variables and conditional logic so prompts can be dynamically assembled based on user context, available tools, and data sources. One customer building a SQL-generating agent supports dozens of database types. Instead of embedding instructions for every SQL dialect into one monolithic prompt, they dynamically include only the instructions relevant to the customer's database — resulting in smaller prompts, more precise output, and lower cost per request.
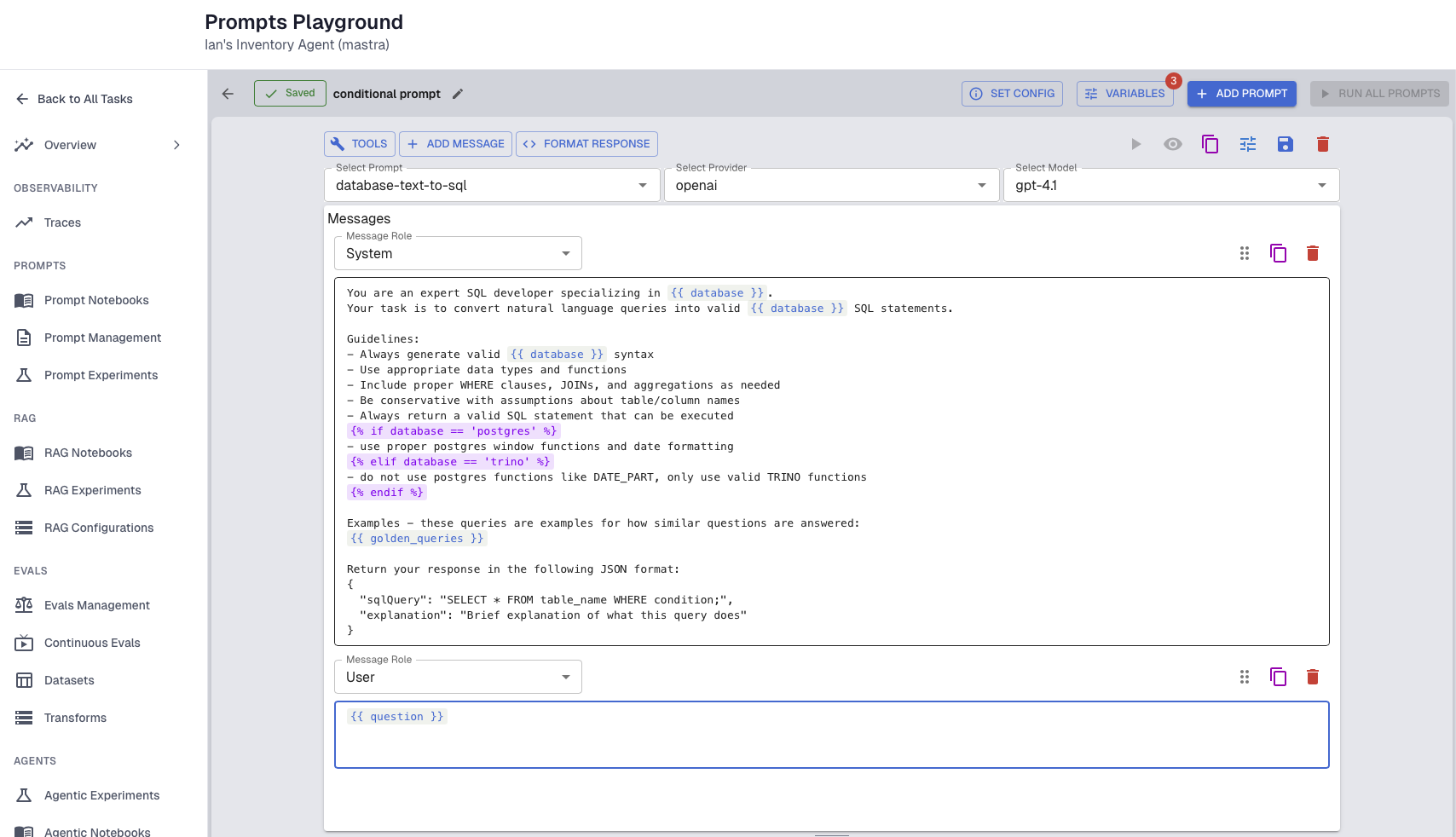
Experimentation and regression testing. Prompt changes should never be pushed to production blindly. With proper observability, teams can build datasets from real customer interactions and replay them against new prompt versions — enabling both regression testing (does the new version break existing behavior?) and failure case improvement (does it fix known failures?).
Deep dive: Best Practices for Building Agents | Part 2: Prompt Management
5. Test Changes with Experiments Before They Reach Production
Security reviewers want evidence that changes are validated before they reach users. Experiments combine three things: a dataset of known inputs and expected outputs, supervised evals to score results, and a variable to test (a new prompt version, a different retrieval strategy, a model swap).
There are three levels of experimentation, each with different cost and scope tradeoffs:
Prompt experiments run a prompt in isolation against a dataset. This is the fastest iteration loop. You can test dozens of prompt variations without spinning up the full agent stack. If you're using templated prompts with external storage, this is especially powerful: swap in a new prompt version, run it against your dataset, and compare results before touching the production agent.
RAG experiments test retrieval configurations - different chunking strategies, embedding models, or retrieval parameters - while keeping the prompt and agent logic constant.
Agent-level experiments run the full agent end-to-end against a test dataset. These are the most expensive but provide the most realistic assessment of behavior changes.
The general guidance: start narrow. Use prompt and RAG experiments to iterate quickly on individual components, then validate with agent-level experiments before promoting changes to production.
Experiments also serve a trust-building function for enterprise buyers. One company we work with uses experiments during customer onboarding: the buyer provides a set of questions they expect the agent to answer correctly, along with expected answers. The team loads these into a test dataset and runs the agent experiment end-to-end, producing a scorecard showing exactly how well the agent performs on the customer's own questions. This gives buyers concrete evidence to bring back to their stakeholders.
The most powerful pattern connects experiments to the rest of your development workflow. Monitor continuous eval failures to identify underperforming scenarios. Add those failure cases to a behavior dataset. Run experiments against that dataset, iterating until the failures pass. The same dataset that drove the improvement then serves as a regression test: before every deployment, re-run experiments to ensure new changes don't break previously fixed behaviors.
Deep dive: Best Practices for Building Agents | Part 4: Experiments & Supervised Evals
6. Enforce Least Privilege and Scoped Execution
Enterprise security teams consistently flag one concern above all others with AI agents: what can this thing do if it goes wrong?
AI agents expand the attack surface because they take actions (calling APIs, executing workflows), access sensitive data, and chain decisions over time. A compromised or malfunctioning agent with broad permissions can cause far more damage than a traditional application failure.
The core principle is to treat agents as privileged automation systems, not just models. That means:
Dedicated agent identities. Every agent should have its own service identity — not a shared account, not a developer's credentials. This makes every action attributable and auditable.
Per-tool permission scoping. Grant each agent only the minimum permissions needed for the specific tools it uses. A customer service agent that reads order history should not have write access to the orders database. Scope permissions at the tool level, not the agent level.
Short-lived tokens and approval gates. Use short-lived credentials rather than long-lived API keys. For sensitive actions — financial transactions, production system changes, sending communications on behalf of users — require explicit approval before execution, either from a human or from a policy engine.
Separate reasoning from execution. Don't let the LLM directly call tools. Instead, have the LLM propose actions (a plan), then route those proposed actions through a policy or execution layer that validates them before executing. This protects against prompt injection, indirect instruction hijacking, and hallucinated actions. This separation is increasingly seen as mandatory in enterprise architectures.
Human-in-the-loop for high-risk decisions. Define which decisions require human review or approval. For high-risk use cases — automated employment decisions, medical recommendations, financial transactions — having a clear human-in-the-loop policy is a requirement for most security reviews, and increasingly for regulatory compliance under frameworks like the EU AI Act.
7. Know What's Running: Discover Every Agent, Tool, and Model in Your Environment
You can't govern what you can't see. And in 2026, the visibility problem has gotten significantly worse.
The new problem is shadow agents: AI agents that have been brought into the enterprise through multiple avenues without going through proper governance channels. Engineering teams build them on frameworks like LangChain, CrewAI, or cloud-native platforms. Vendors push them into existing products through routine software updates. Individual teams spin up agents in sandbox environments that quietly touch production data.
The result is that enterprises are suddenly realizing they have agents running across their environment without clear ownership or oversight — and critically, without knowing what models, tools, and frameworks are running underneath.
When a security reviewer asks "what models are being used across your AI systems?" and the answer requires polling every team in the organization via spreadsheet, that's a governance gap that will block production approvals.
Manual inventory doesn't scale. Trying to track AI systems through spreadsheets and surveys is a losing game when new agents can appear daily. You need automated, continuous discovery.
Effective discovery requires a multi-layered strategy combining several techniques: telemetry scanning (implementing scanners in your cloud logging infrastructure to detect agent framework signatures), MCP monitoring (detecting Model Context Protocol servers running in your environment), network layer analysis (monitoring HTTP traffic for LLM signatures), and API-driven discovery (using the APIs of AI platforms like AWS Bedrock, GCP Vertex AI, or agent-building frameworks to query what's running). No single technique catches everything — a minimum of all four is recommended for comprehensive coverage.
Arthur's Agent Discovery & Governance (ADG) platform automates this process. It continuously scans compute environments across AWS, GCP, and other infrastructure to discover and catalog agents as they appear. Unregistered agents are flagged, and teams can quickly assign them to an application, designate an accountable owner, and apply the appropriate guardrails. The platform's federated architecture allows monitoring across different cloud environments from a single pane of glass — whether agents are running traditional ML, generative AI, or agentic workflows.
Customize governance per agent. One-size-fits-all policies fail for agentic AI. The governance policies for a customer service agent at an airline are fundamentally different from those for an inventory management agent in a warehouse or a healthcare EHR agent for patient intake. A customer service agent needs guardrails around PII, toxicity, and hallucination, plus evaluators for friendly tone and brand guideline adherence. A warehouse agent needs prompt injection defense and SQL accuracy evaluators. A healthcare agent needs HIPAA-compliant data handling, clinical accuracy evaluators, and highly customizable sensitive data filters — because medical terminology that's appropriate in a hospital context would be flagged as harmful in a customer service context. Your governance platform needs to accommodate these differences while maintaining a unified view across the enterprise.
The Agent Development Flywheel
The practices in this guide aren't a checklist you complete once, they form a continuous cycle that makes your agents more reliable over time:
- Instrument your agent with tracing from day one so you have visibility into what it's actually doing.
- Evaluate production behavior with continuous evals that catch issues before your users do.
- Iterate on prompts, retrieval, and agent logic through controlled experiments validated against real failure cases.
- Ship with guardrails that intercept problems in real time, governance that ensures every agent has an owner, and the evidence security teams need to approve production rollouts.
The bottleneck for enterprise AI adoption in 2026 isn't the technology itself — it's trust. Organizations that build these practices into their agent development lifecycle move faster, not slower, because they have the visibility and control needed to push AI from pilot to production with confidence.
The era of ungoverned AI agents is ending. The organizations that thrive will be the ones that treat security and trust not as a tax on innovation, but as the foundation that makes innovation sustainable.