
Welcome to the fifth installment of our series on building reliable AI agents. In Part 1, we covered observability and tracing. In Part 2, we covered prompt management. In Part 3, we covered continuous evaluations. In Part 4, we covered experiments and supervised evals. This series distills lessons from our Forward Deployed Engineering team, based on real-world deployments of production agents across industries.
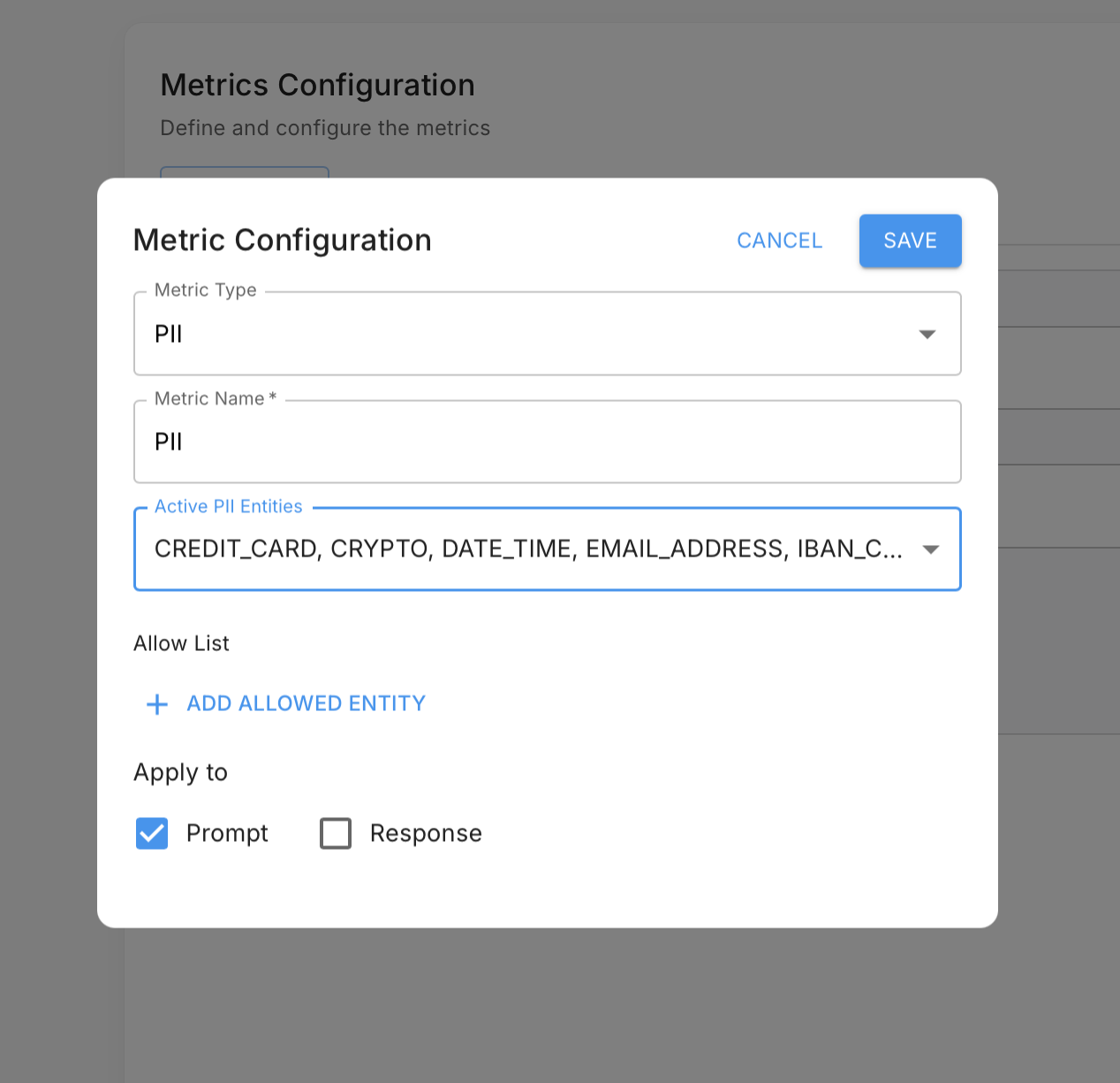
The first four posts focused on tools that give you visibility, control, and detection: seeing what your agent does, improving how it behaves, and catching regressions in production. All three are retrospective. Guardrails are different. They intercept agent behavior in real time, before a bad input reaches your LLM or a bad output reaches your user. A major airline we work with uses pre-LLM guardrails to redact PII from customer support conversations before they ever leave the corporate environment. Another customer uses a post-LLM hallucination guardrail that catches unsupported claims and automatically feeds them back to the agent for correction before the user ever sees the response. This post explains how both patterns work and how to apply them.
Two Types of Guardrails
Guardrails intercept data at two points in the agent execution loop.
Pre-LLM guardrails run before the user's input and assembled context is sent to the model. Common uses include:
- PII detection and redaction: Strip sensitive personal and company information before it leaves your environment and is transmitted to an external model provider.
- Sensitive data blocking: Prevent credit card numbers, credentials, or proprietary internal data from being included in LLM context.
- Prompt injection detection: Identify malicious input designed to override the agent's system prompt or hijack its behavior before it reaches the model.
For the airline, operating a customer-facing support agent that handles flight bookings, payment disputes, and account details, a pre-LLM guardrail was non-negotiable from a compliance standpoint. Every conversation passes through PII detection before anything is sent to the model. Identified PII is automatically redacted, ensuring sensitive customer data never reaches an external model provider. The guardrail gave their team confidence to ship the agent to production without exposing the company to data handling risk.
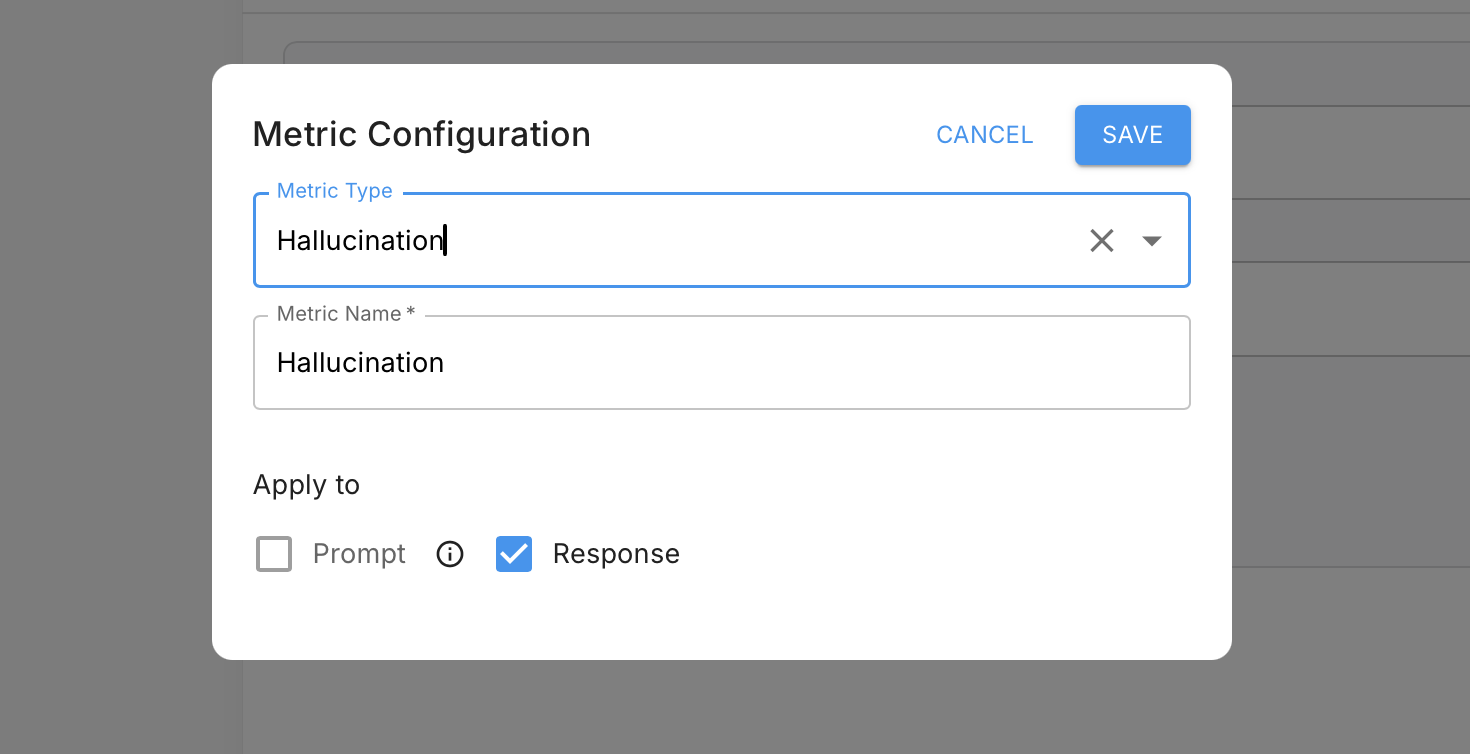
Post-LLM guardrails run after the model returns a response, before that response is acted on or returned to the user. Common uses include:
- Hallucination detection: Check whether the model's claims are explicitly supported by the context it had access to.
- Toxicity detection: Flag harmful or inappropriate content before it's surfaced to users.
- Tool and action validation: Verify the agent selected the right tools or took the right actions given the user's request.
- Output format compliance: Ensure responses conform to the expected structure before they're passed downstream.
Guardrails as a Feedback Mechanism
Most teams think of guardrails as filters: something either passes or gets blocked. The more powerful pattern is using post-LLM guardrail failures as input for a self-correction loop.
When a guardrail detects a problem with a response, instead of surfacing a failure to the user, the system feeds the flagged issues back to the LLM with a targeted correction prompt: here is what you said, here is what was unsupported, revise your response. The agent retries, and the corrected output goes through the guardrail again. This repeats until the response passes, or a retry limit is hit.
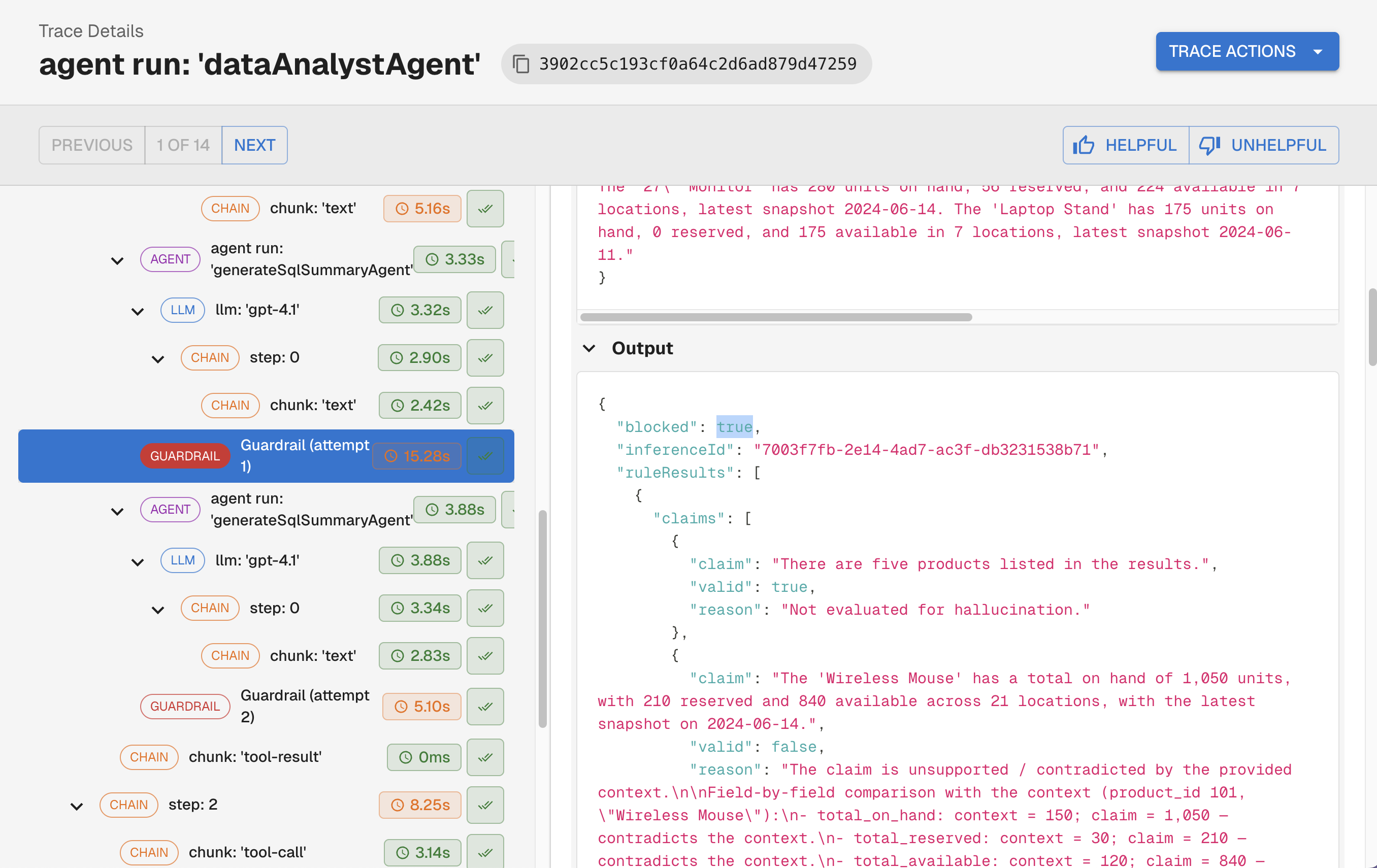
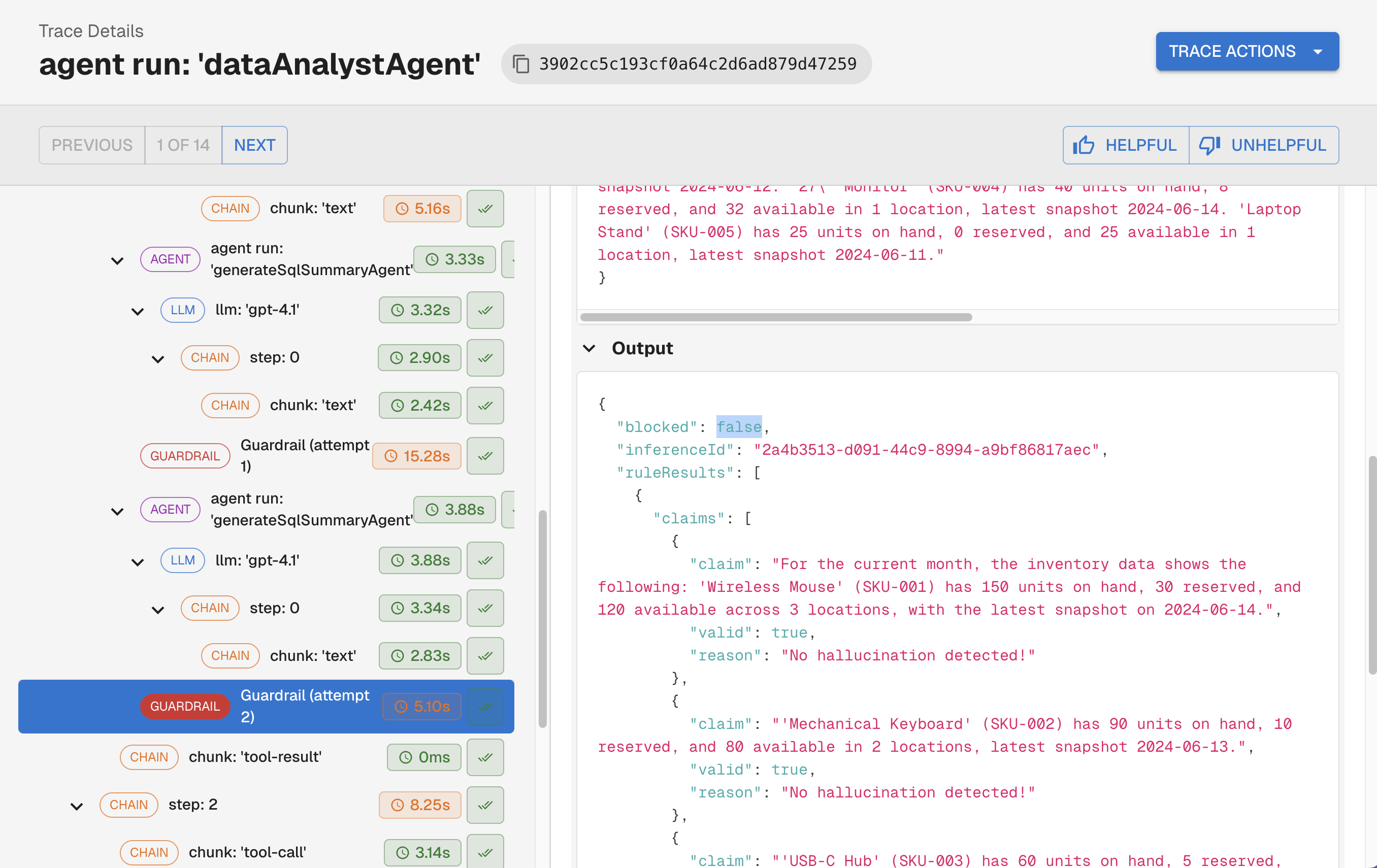
This is exactly how the second customer puts hallucination detection to work. Their guardrail checks every response for claims that aren't explicitly supported by the agent's context. When it finds one, it isolates that specific statement, sends it back to the LLM with a correction request, and runs the check again. The user only receives a response where every factual claim is grounded in what the agent actually knew, with no manual review required. What would otherwise be a source of user-facing errors became a quality guarantee baked into the execution loop.
This is also distinct from continuous evals, which detect patterns across production traffic after the fact. Guardrails operate within a single execution, correcting the agent before any response is ever returned.
Best Practices
- Treat guardrails as first-class execution logic. They belong in the agent loop, not as an afterthought. A guardrail that only runs sometimes, or that can be bypassed, provides false confidence.
- Keep pre-LLM guardrails fast and deterministic. They run in the hot path before every LLM call. Regex-based PII detection and rule-based injection checks add minimal latency. Avoid LLM-based checks here unless absolutely necessary.
- Be deliberate about post-LLM guardrail cost. Hallucination and toxicity checks that use a model to assess output add latency and cost per request. Scope them to what actually requires that level of judgment and factor that into your architecture.
- Emit guardrail interventions as telemetry. Every guardrail trigger should produce a trace event, just like any other span in your agent. This lets you see how often each guardrail fires, what it catches, and whether self-correction attempts succeed.
- Monitor guardrail pass/fail rates over time. A sudden spike in PII detections or hallucination failures is a signal worth investigating before users have to report it, the same principle as continuous evals from Part 3.

TLDR
- Guardrails intercept agent behavior in real time: pre-LLM checks protect what goes into the model, post-LLM checks control what comes out.
- Pre-LLM guardrails handle PII, sensitive data, and prompt injection. Post-LLM guardrails handle output quality, hallucinations, and action validation.
- The most powerful post-LLM pattern is a self-correction loop: failed responses are revised mid-execution rather than returned to the user.
- Emit guardrail events as telemetry and monitor failure rates over time to catch emerging issues before your users do.
- Combined with observability, prompt management, and continuous evals, guardrails complete the runtime layer of a production-grade agent system.
Up Next
In the next post in this series, we'll cover agent discovery and governance: how teams manage multiple agents, track ownership, and maintain visibility as their agent footprint grows.
Interested in building production-ready agents? Connect with me on LinkedIn.
If you'd like to learn more about shipping reliable agents using these best practices, book a demo with an AI expert.
Want to see how we've applied these best practices internally? Check out our agent building stories: How We Turned a Vibe-Coded Jira Bot Into a Reliable Agent in Two Weeks & What "Building an Agent" Actually Means (And Why Most People Get It Wrong).
SHARE




