Best Practices for Building Agents | Part 3 - Continuous Evaluations

Welcome to the third installment of our series on building reliable AI agents. In Part 1, we covered observability and tracing. In Part 2, we covered prompt management and testing. This series distills lessons from our Forward Deployed Engineering team, based on real-world deployments of production agents across industries.
In this post, we cover continuous evaluations: automated checks that run against your agent's production interactions to detect behavioral issues before your users do.
The Problem With Waiting for User Reports
Most teams find out their agent is misbehaving when a user files a complaint. By then, the damage is done. User trust in AI agents is already fragile, and a bad experience at the wrong moment can permanently change how someone thinks about your product. Multiple users may have already been affected, and reproducing the issue means digging back through traces to find out what happened.
Unit tests help, but they aren't sufficient on their own. Agentic applications are non-deterministic: an agent that passes a test suite today may fail the same cases tomorrow. And the domain of inputs in production is far more diverse than any handwritten test set can reliably cover. Even with solid test coverage, you need continuous evaluations running against real production traffic to catch bad behavior as it emerges.
Continuous evals shift that dynamic. Instead of waiting, you get automated signal the moment something goes wrong. Two customers we work with put this into practice in different ways. One surfaces eval results directly to their end users as a transparency feature, giving their customers confidence that the agents they configure are performing reliably. Another built evals targeting specific failure modes their users had reported, so regressions get caught before anyone has to file a complaint. The rest of this post explains how to build evals that work the same way.
Supervised vs. Unsupervised Evals
Not all evals can run in production, and understanding why starts with a foundational distinction.
Supervised evals require knowing the correct answer ahead of time: the expected agent response, the tool that should have been called, or the expected RAG result. This makes them useful for pre-production experiments with a labeled test dataset, but they can't run continuously in production where inputs and outputs change with every interaction.
Unsupervised evals assess behavior using only the information available in the agent's own context. No expected output is required. Examples include:
- Hallucination: Did the agent state facts not explicitly supported by the context it had access to?
- Answer completeness: Did the agent address all aspects of the user's question?
- Topic adherence: Did the agent respond to questions outside the topics defined by its system prompt?
- Goal accuracy: Did the agent call the right tools to fulfill the user's intent?
Because unsupervised evals don't need a ground truth answer, they can run against every production interaction. Supervised evals remain valuable for offline regression testing. Unsupervised evals are what power continuous monitoring.
The remainder of this post will focus on best practices for unsupervised evals, but the next post in this series will cover supervised evals and experiments in detail.

Best Practices for Building Unsupervised Evals
Make evals binary, not scored on a range
Score evals as binary pass/fail rather than on a range like 1 to 10 or low/medium/high. Ranges push the judgment burden onto a human who has to decide what threshold requires attention, and LLMs compound this by being inconsistent scorers: the same interaction might return a 4 on one run and a 6 on another. The goal is evals that are reliable enough to make the judgment call on their own. When an eval fires, it should mean something requires attention. Require the eval to return an explanation alongside the pass/fail decision so you can quickly identify patterns across failures rather than re-reading every interaction from scratch.

Make evals specific, not generic
A generic eval like "rate the quality of this response" will produce noisy, inconsistent results. Each eval should target a concrete failure mode with a clear definition of what constitutes a failure. "Did the agent reference information not present in the retrieved documents?" is specific enough for an LLM to judge reliably. "Was the response good?" is not. Specificity also means including the right context in the eval: an eval checking for hallucination needs the retrieved documents, not just the final response, and an eval checking topic adherence needs the agent's system prompt so it knows what topics are in scope. If you can't describe what the eval checks in a single sentence, it's probably too broad.
Provide examples in the eval prompt
Examples reduce ambiguity more effectively than longer instructions. Include both passing and failing examples in the eval prompt to anchor the LLM's judgment around the specific boundary you care about. A written definition of "hallucination" leaves room for interpretation; a concrete example of a hallucinated response next to a grounded one makes the standard clear. Focus your examples on edge cases and boundary decisions rather than obvious pass/fail scenarios. The obvious cases are ones the eval will already get right. The value of examples is in calibrating the gray areas where the eval might otherwise be inconsistent.
Choose the right model for the job
Evals run on every production interaction, so cost and latency add up fast. A smaller model with a well-crafted prompt can often match a larger model's accuracy at a fraction of the cost. Start by establishing a quality baseline with a capable model, then test whether a smaller model produces comparable results on the same set of interactions. If accuracy holds, you can cut your eval costs significantly without sacrificing signal. If the smaller model struggles, that usually points to a prompt that needs more specificity or better examples rather than a hard requirement for the larger model.
Know what evals are good at (and what they aren't)
LLM-based evals are strong at generalizing over content: assessing tone, completeness, adherence to instructions, and whether a response is grounded in its source material. They are weaker at precise quantitative assessments. If you need to measure precision and recall of a retrieval step, verify that a calculation is correct, or check that a number falls within a specific range, a deterministic check (a simple function, a schema validator, or a math verification) will be more reliable and cheaper to run. Don't force an LLM eval where a programmatic check would do.
Responding to Failures
Once you have continuous evals running, you need a plan for what to do when they fail. In practice, we see two patterns.
Alerting: Teams with a clear picture of correct behavior wire up alerts to fire on eval failures. When an eval triggers, the team is notified immediately and can investigate before more users are affected. This works best when evals are high-confidence and produce few false positives.
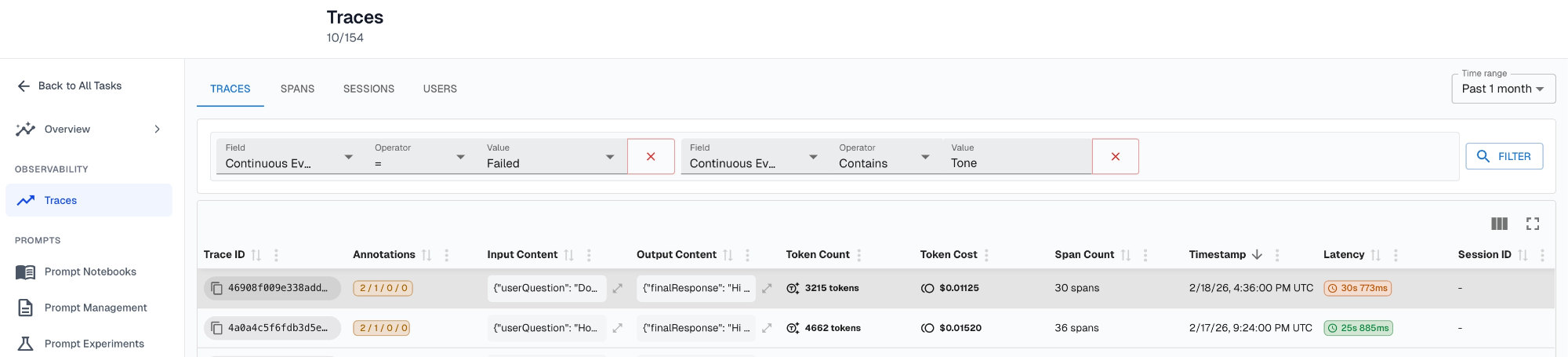
Human review filtering: Earlier-stage teams use eval failures as a triage mechanism rather than a direct alert. Failures queue interactions for human review, and the team analyzes clusters of failures to identify common patterns and prioritize improvements.
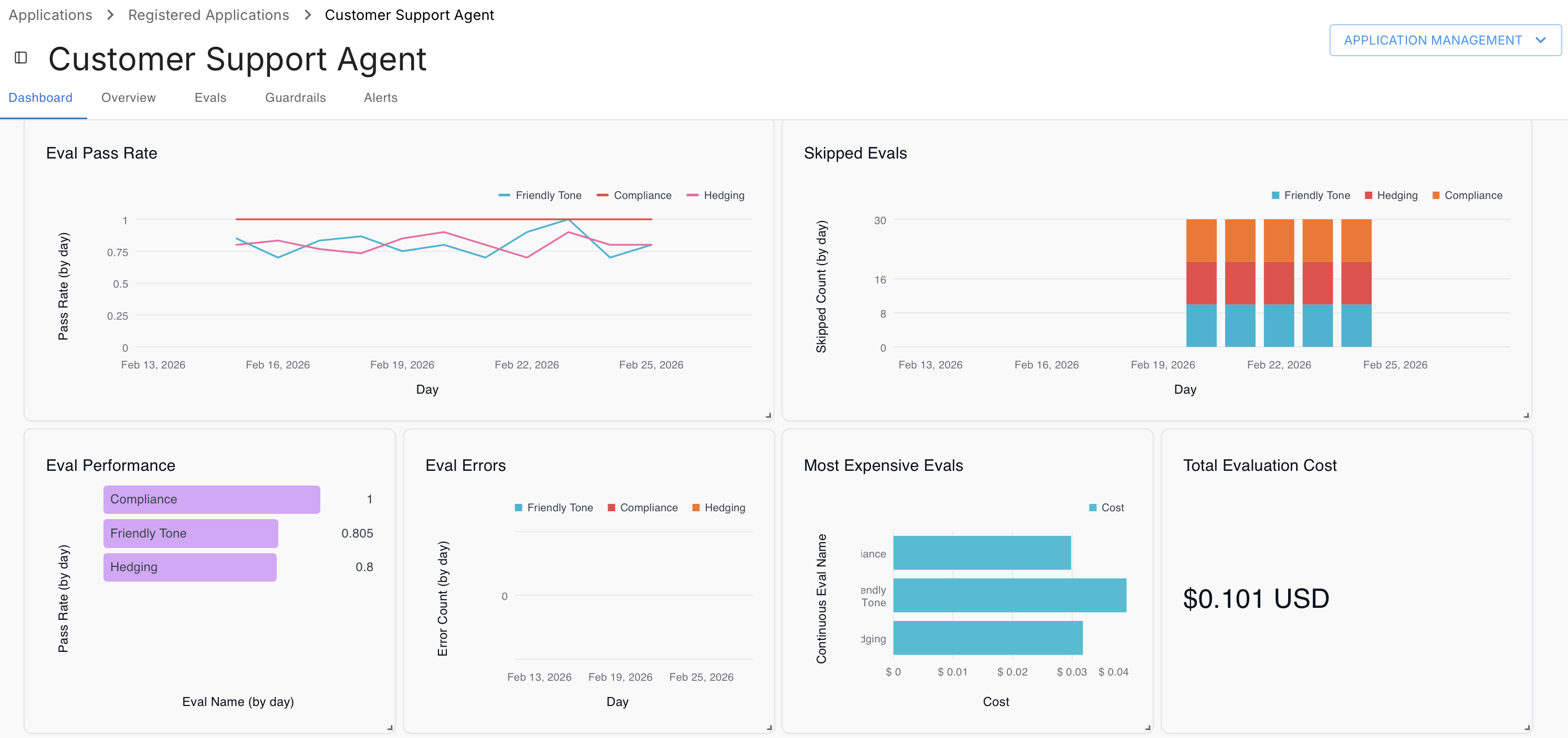
The two customers mentioned earlier map directly to these patterns. The consulting platform customer runs four continuous evals on every interaction: hallucination, answer completeness, goal accuracy, and topic adherence. These evals feed an analytics dashboard visible to their end users, giving customers direct evidence that the agents they configure are answering questions accurately and staying within their defined scope. The second customer built targeted evals around three failure modes their users had reported: the agent responding in the wrong format, the agent refusing questions it could have handled, and the agent using the wrong protocol when communicating with their datastore. When any of those evals fire, the dev team gets an alert and can address the regression before it compounds.
TLDR
- Most teams find out about agent failures from user reports. Continuous evals catch them first.
- Only unsupervised evals can run continuously in production, since they assess behavior without requiring a known expected output.
- Evals must be binary pass/fail. Range-based scoring is inconsistent and pushes judgment to humans.
- Provide examples of pass/fail results in eval prompts, specifically examples that capture edge-cases or decision boundaries
- Choose the right model to balance between eval correctness and cost
- Use programatic verification (eg: tools) for deterministic evaluation - use evals to generalize over content
- When evals fail, teams either alert immediately or queue interactions for human review, depending on their confidence in the evals and the maturity of the system.
- Combined with observability (Part 1) and prompt management (Part 2), continuous evals complete the feedback loop that makes reliable agent development possible.
Up Next
In the next post in this series, we'll cover experiments and supervised evals: how to test agent changes offline before they reach production.
Interested in building production-ready agents? Connect with me on LinkedIn.
If you'd like to learn more about shipping reliable agents using these best practices, book a demo with an AI expert.
Want to see how we've applied these best practices internally? Check out our agent building stories: How We Turned a Vibe-Coded Jira Bot Into a Reliable Agent in Two Weeks & What "Building an Agent" Actually Means (And Why Most People Get It Wrong).