Stop Guessing.
Start Shipping Agents.
An open-source toolkit for building, testing, and monitoring AI agents in production.
One workflow for the whole agent lifecycle.
Manage
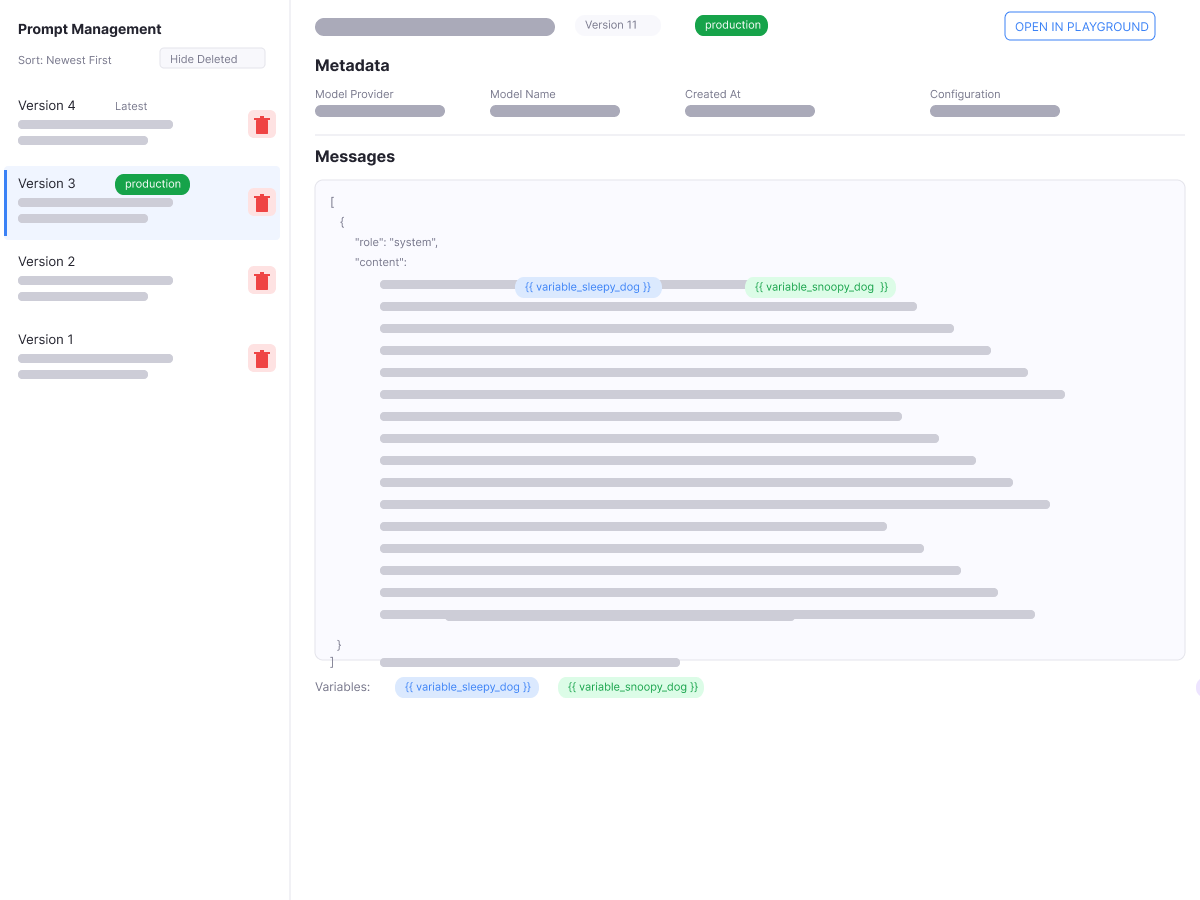
Keep prompts versioned, tagged, and promotable across environments. Roll back in seconds when something regresses.
Experiment
Test prompt changes, model swaps, and RAG configs against real data before anything ships. Know what changed and why it mattered.
Monitor
Trace every agent run end to end. Catch hallucinations, failures, and drift in production before your users do.
Get Started Today
Ship Reliable AI Agents.
Fast.
Prompts that behave like code.
Most teams treat prompts like config files — unversioned, untracked, and painful to roll back. One bad change can quietly break production.
Version and promote prompts across environments without redeploying your agent
Roll back in seconds when performance drops — no firefighting, no guesswork
Template prompts to control structure and variables at runtime, across teams or tenants
Test changes before they reach users.
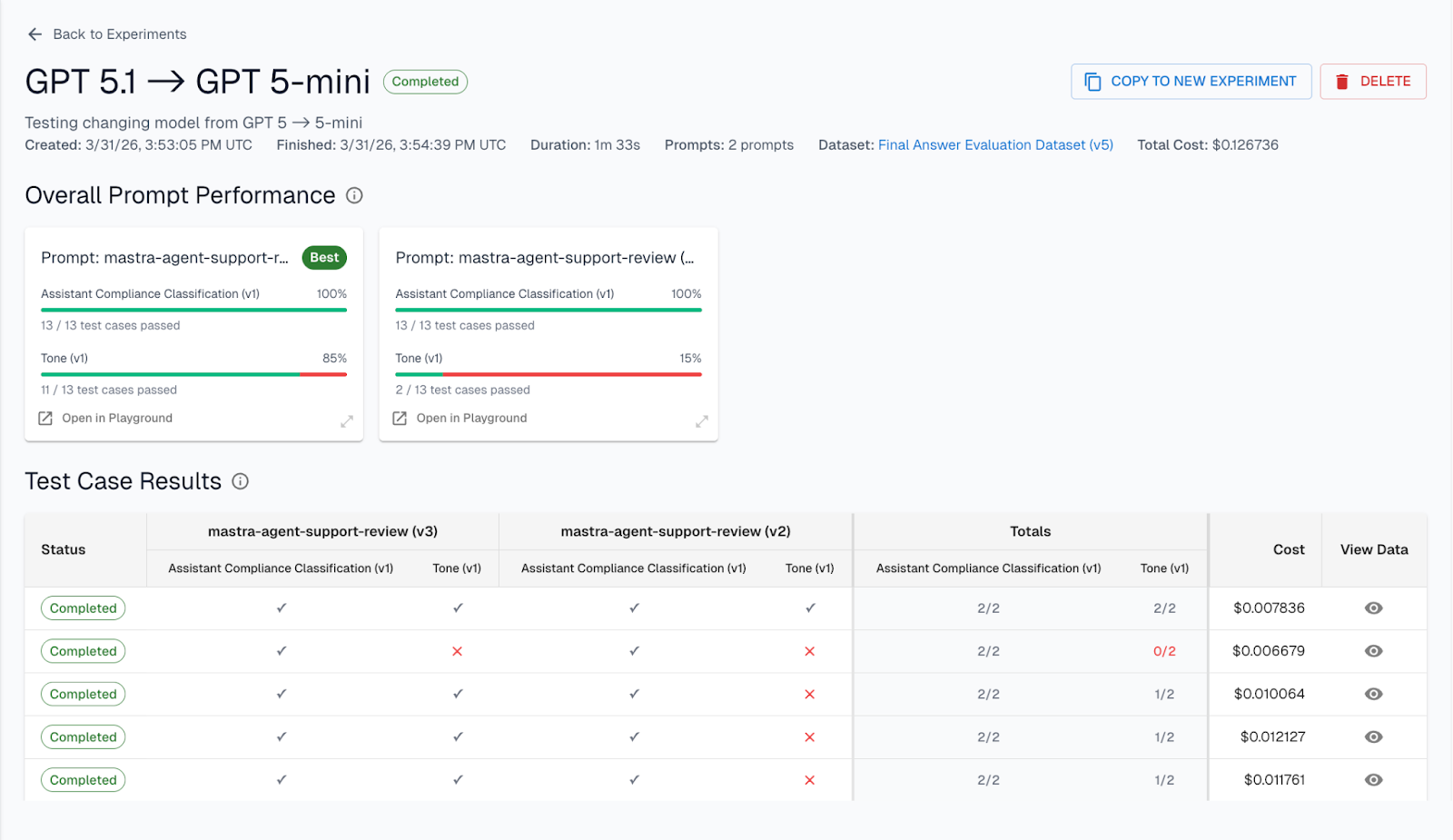
Swapping a model or tweaking a prompt is a gamble without structured tests. Most teams ship first and find out what broke second.
A/B test prompts, models, and RAG configs against real production data — not synthetic examples
Test full agent workflows — tool use, reasoning paths, and output formatting, not just single completions
Score results automatically or with human review — and see exactly what changed and why
See exactly what your agent did.
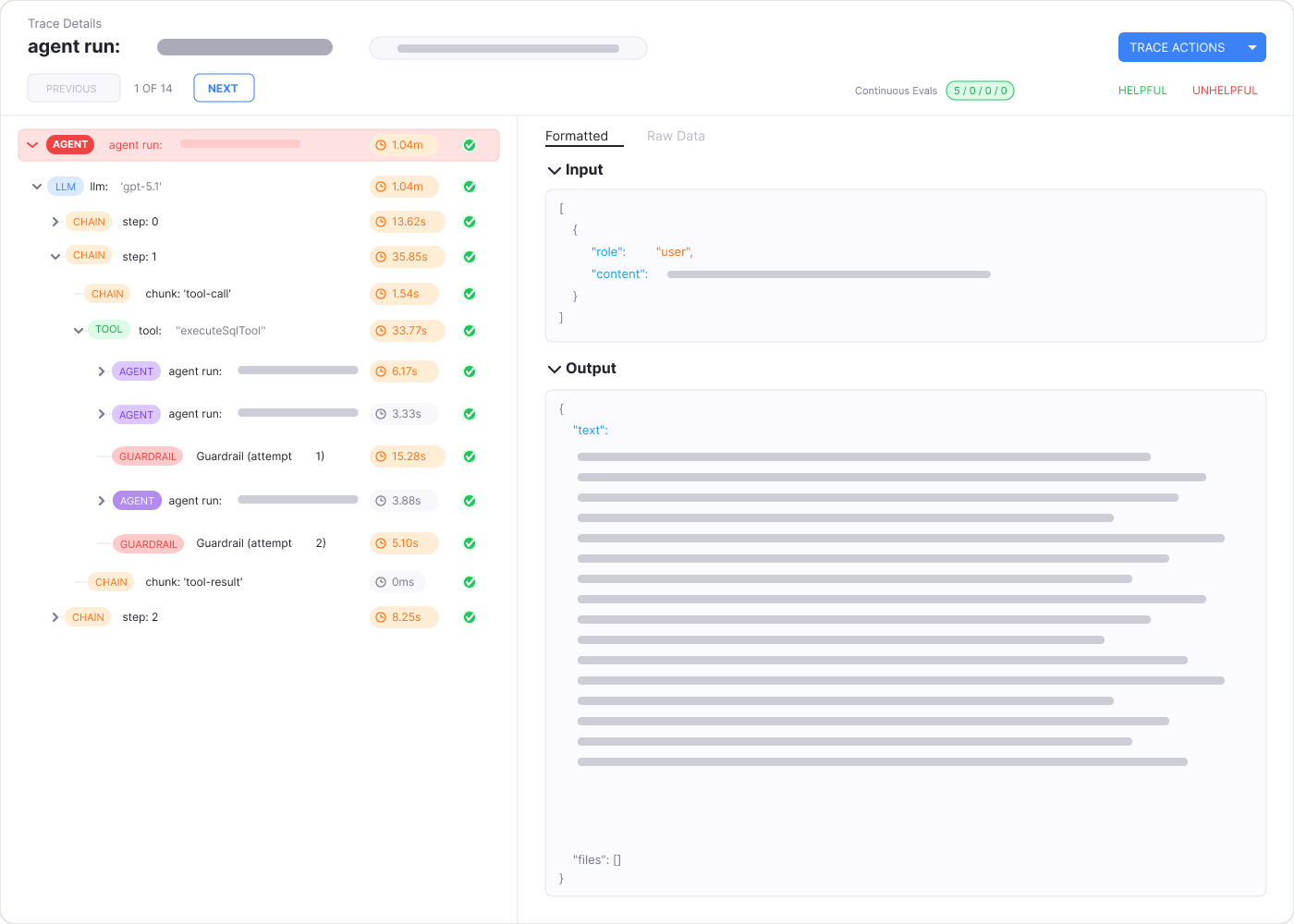
When an agent fails, you shouldn't have to piece together logs and hope for the best.
Inspect every step — inputs, tool calls, reasoning paths, and outputs across every run
Filter by prompt version, user, outcome, or cost to find the source of a failure fast
Built on OpenTelemetry — works with LangChain, LlamaIndex, OpenAI, Anthropic, and anything else in the OpenInference ecosystem
Know before your users do.
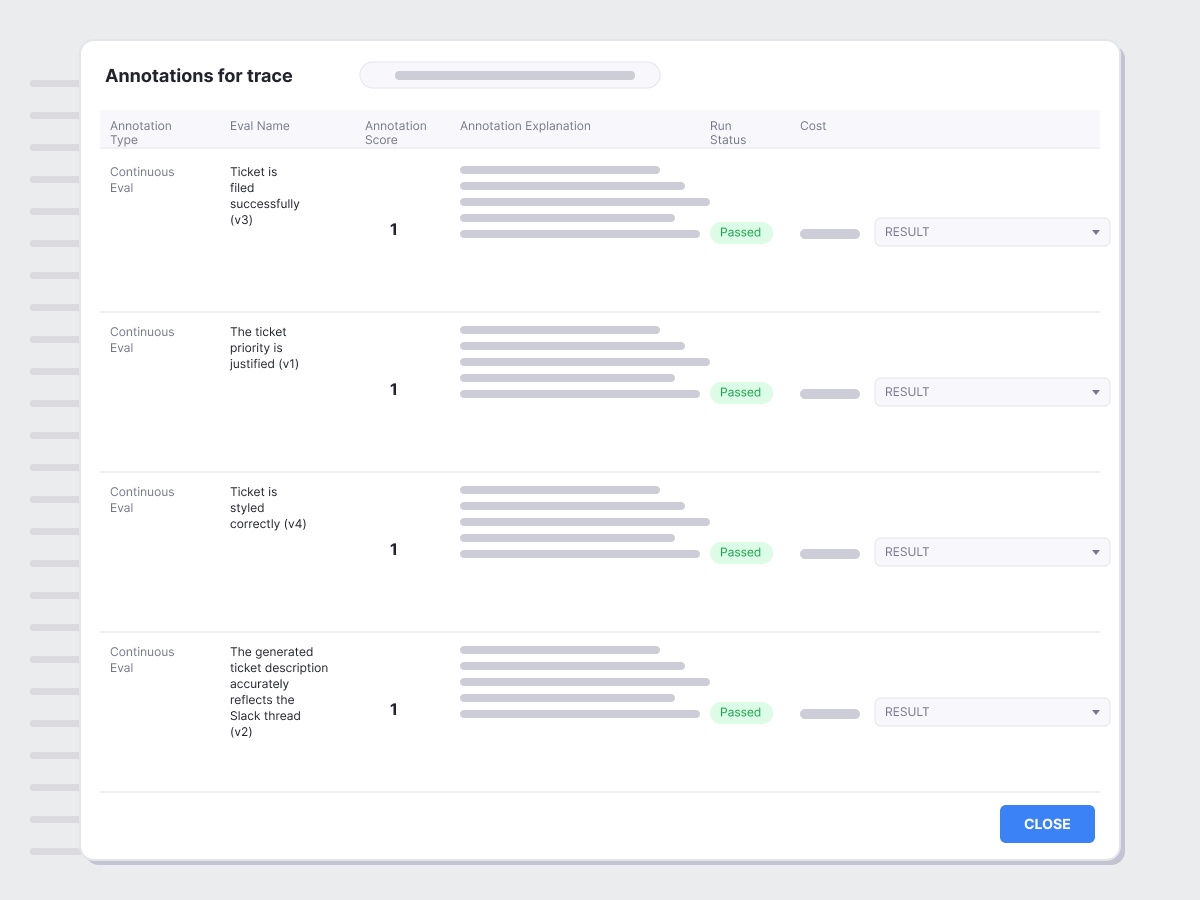
Quality problems in production are invisible until someone complains. By then it's too late.
Run evals on live traffic — hallucination, PII, prompt injection, toxicity, and correctness, continuously
Set alerts the moment quality drifts — not after a user escalation
Validate before you ship with curated datasets and pre-deployment test runs
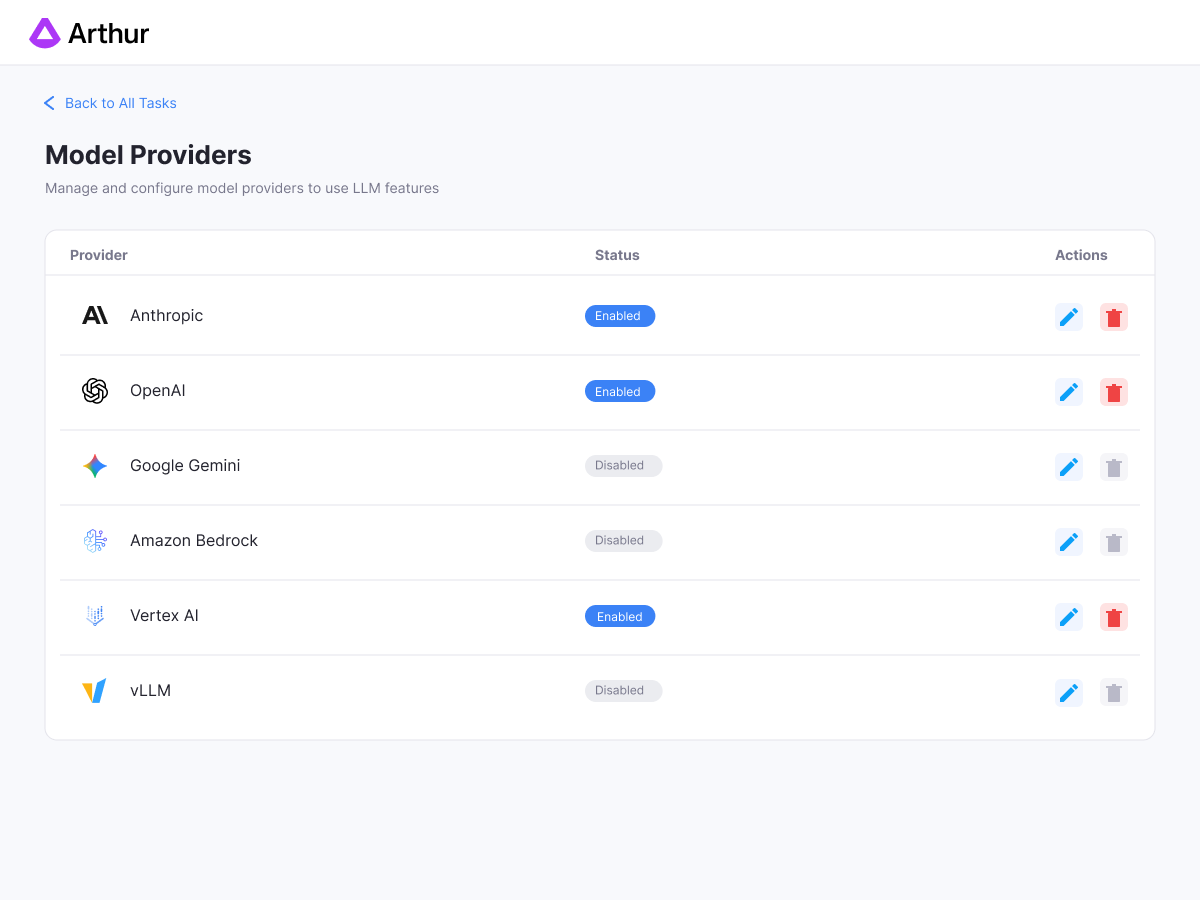
Works with what you already have.
You shouldn't have to rebuild your stack to get observability.
Use any model — OpenAI, Anthropic, Cohere, or open-source
Bring any framework — LangChain, LangGraph, LlamaIndex, Vercel AI SDK, and more
Deploy your way — Docker, CloudFormation, or Helm. Your environment, your data.
Agent Framework
Eval Platform
Arthur Engine + Toolkit
Build and run agents
Prompt versioning & management
Basic
Structured A/B experiments
Real-time guardrails (hallucination, PII, injection)
End-to-end trace debugging
Traditional ML model eval
Self-hosted / open-source
Varies
SaaS
MIT licensed
How It Fits Into the Arthur Engine
The Agent Toolkit is part of the Arthur Engine — Arthur's free, open-source AI evaluation and monitoring platform. The Engine provides the foundation: real-time guardrails, LLM eval infrastructure, and flexible deployment. The Toolkit builds on top of that with the full agent development workflow.
Works with every model and framework











Ready to turn your AI into real-world impact?
We’ll help you move from pilots and prototypes to production-grade applications, with evaluation every step of the way.
