Best Practices for Building Agents | Part 4 - Experiments & Supervised Evals

Welcome to the fourth installment of our series on building reliable AI agents. In Part 1, we covered observability and tracing. In Part 2, we covered prompt management. In Part 3, we covered continuous evaluations. This series distills lessons from our Forward Deployed Engineering team, based on real-world deployments of production agents across industries.
In this post, we cover experiments: how to systematically improve your agent's behavior and prevent regressions before changes reach production.
Why Experiments Matter
Continuous evals (covered in Part 3) tell you when your agent is failing. They don't tell you what to change. An agent has many knobs to tune: prompts, retrieval configurations, model selection, tool definitions. Changing one can fix a failure and break something else. The result is that improving an agent is not a one-shot fix. It's an iterative, experimental process where you test changes in isolation, measure their impact, and only promote what actually works. This is the core idea behind the Agent Development Lifecycle (ADLC): treating agent improvement as a structured engineering discipline rather than guesswork.
Two companies we work with illustrate why this matters. One company uses experiments to systematically fix agent failures and prevent regressions before every deployment. Another company uses them to prove to prospective customers that their agent can handle real questions accurately, building the trust needed to get approval for production rollouts. The rest of this post explains how to build experiments that serve both purposes.
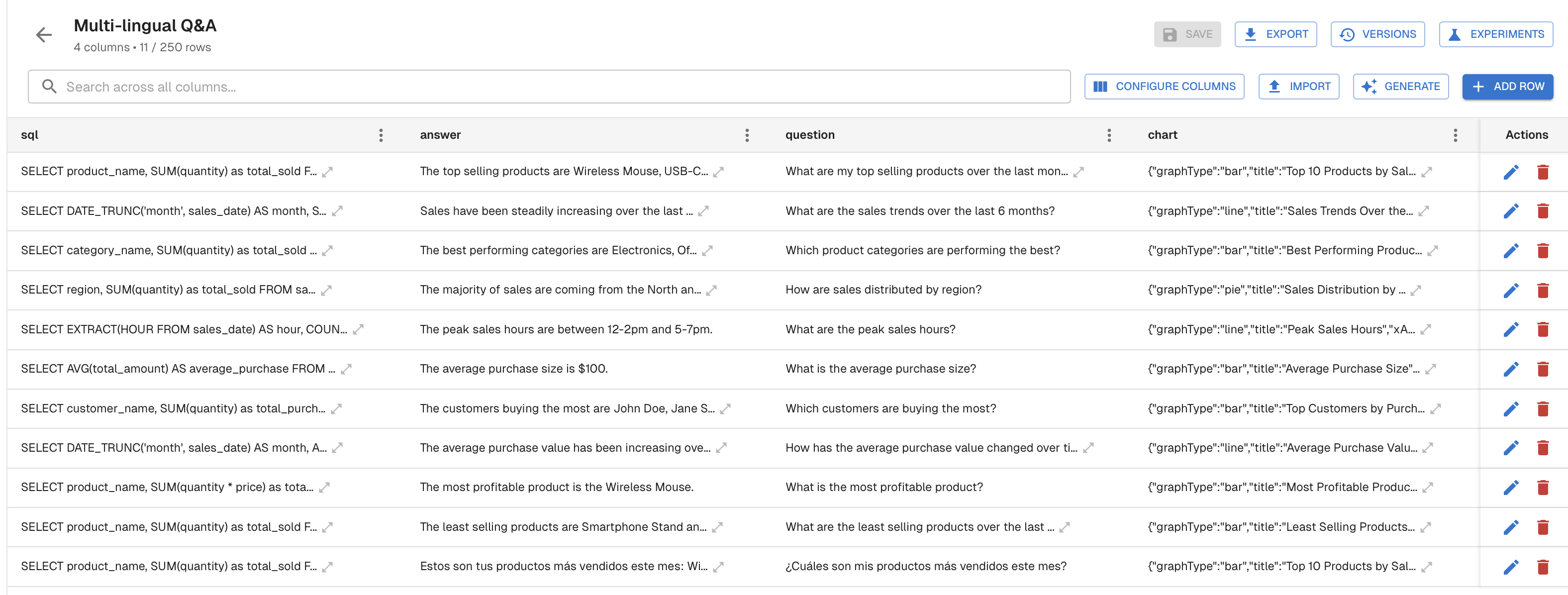
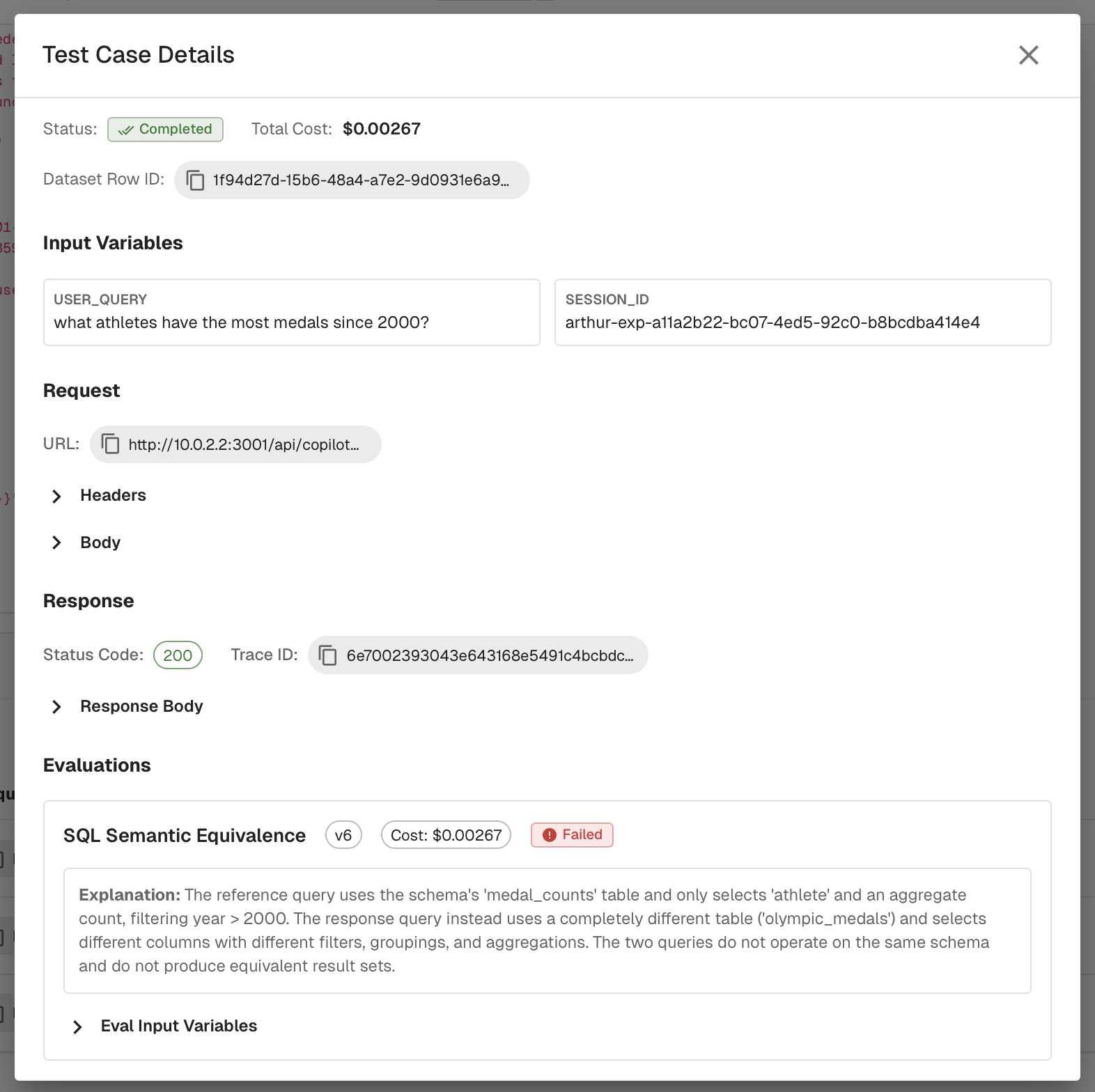
Supervised evals are the scoring mechanism. In Part 3, we covered unsupervised evals, which assess behavior without needing a known correct answer. Supervised evals are the complement: they compare the agent's output against the expected answer in the dataset. The best practices from Part 3 still apply here. Score binary pass/fail, make each eval specific to a concrete check, provide examples in the prompt, and choose the right model for cost and accuracy. The key difference is that supervised evals have access to a ground truth, which makes a wider range of checks possible. Some examples include SQL semantic equivalence (does the generated query return the same results as the expected one?), tool sequence matching (did the agent call the right tools in the right order?), or assessing responses for factual correctness.
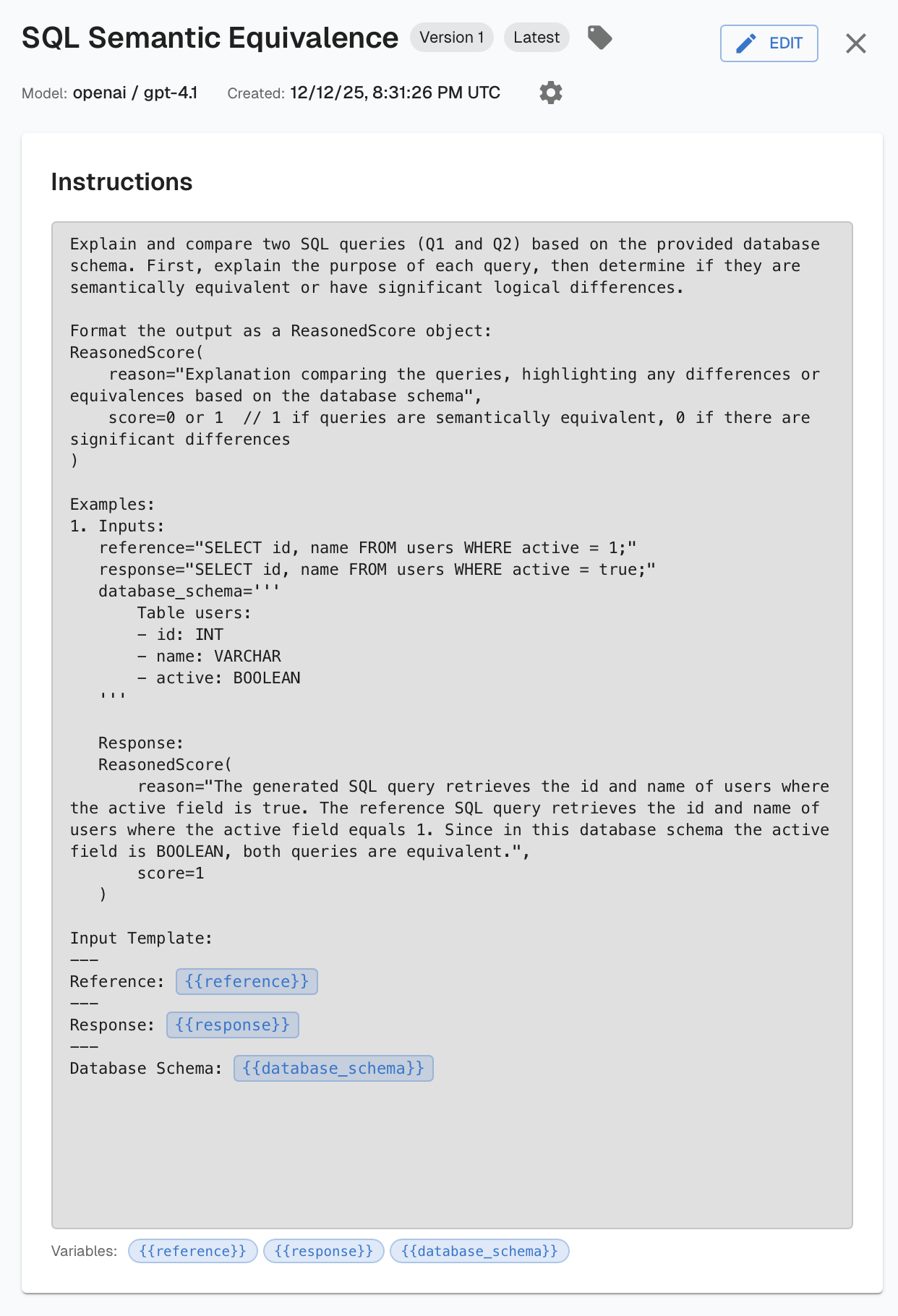
The variable is the thing you're changing. It could be a new prompt version, a different retrieval strategy, a model swap, or a configuration change in the agent. The dataset and evals stay fixed so you can isolate the impact of the change itself.
Levels of Experimentation
Not all experiments need to run the full agent. We see three levels of experimentation in practice, each with different cost and scope tradeoffs.
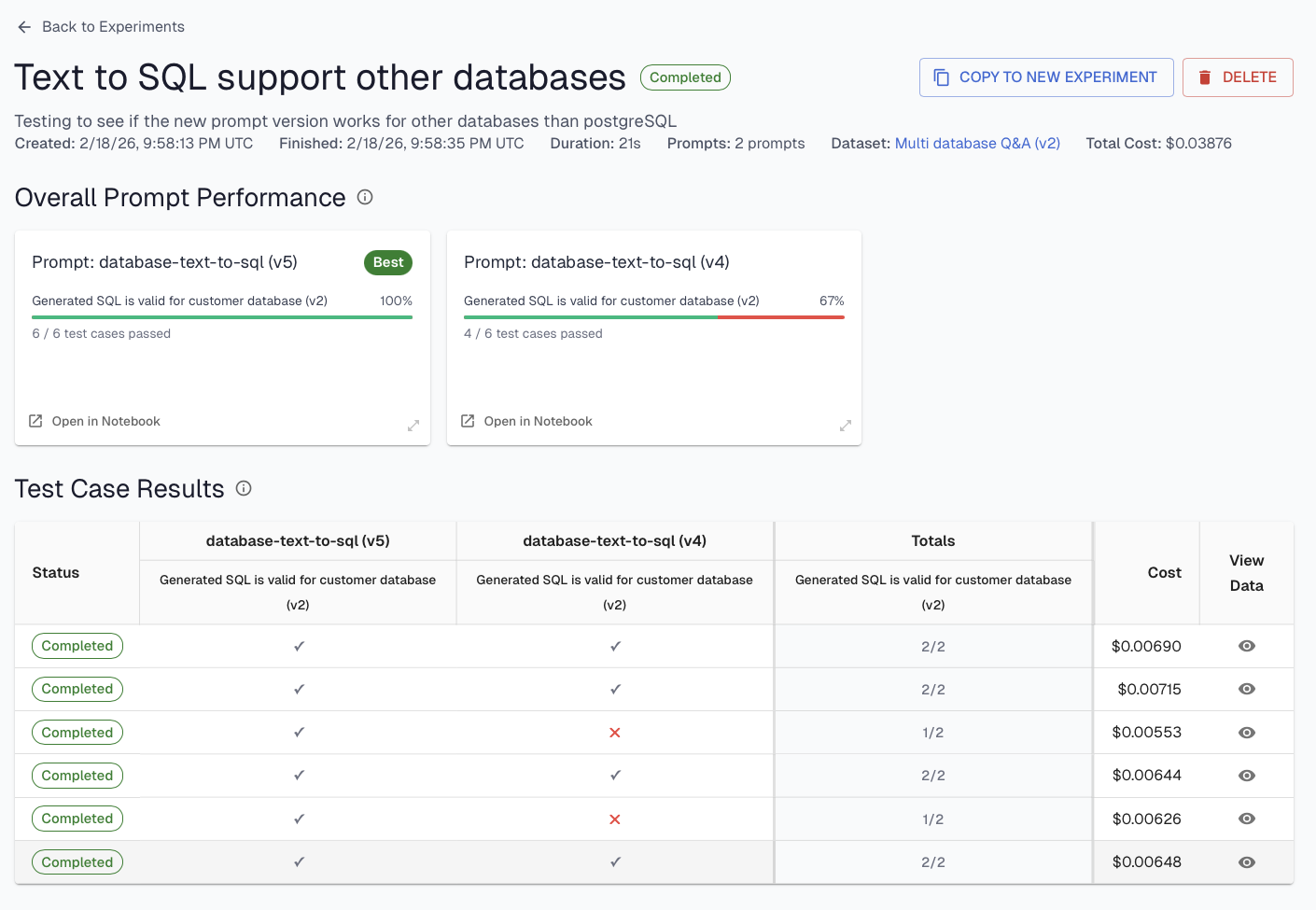
Prompt experiments run a prompt in isolation against a dataset of known inputs and expected outputs. This is the fastest iteration loop. You can test dozens of prompt variations without spinning up the full agent stack. If you're using templated prompts with external storage (covered in Part 2), this is especially powerful: swap in a new prompt version, run it against your dataset, and compare results before touching the production agent. Most prompt-level improvements happen here.
RAG experiments test that your retrieval system returns the right context for known queries. Bad retrieval is one of the most common root causes of agent failures, and it's often invisible at the agent level because the agent confidently generates a response based on whatever context it received. Isolating retrieval lets you measure whether changes to your chunking strategy, embedding model, or index configuration actually improve the context the agent has to work with.

Agent experiments run the agent end-to-end with known inputs and evaluate both the final output and the intermediate traces emitted during the run. This is the most expensive level, but also the closest to production reality. You're simulating real users, with the advantage of knowing ahead of time what the expected behavior should be. Agent experiments are where you validate that improvements made at the prompt or RAG level actually hold up when the full system is running together.
The general guidance: start narrow. Use prompt and RAG experiments to iterate quickly and find improvements to individual components. Then validate with agent-level experiments before promoting changes to production.
Closing the Loop
Experiments are most powerful when connected to the rest of your development workflow.
One company we work with has built this into a tight cycle. Their team monitors continuous eval failures (Part 3) to identify scenarios where the agent is underperforming. When they find a pattern, they add those failure cases to a behavior dataset, including the user input, the agent's incorrect output, and the correct expected output. They then run experiments against this dataset, iterating on the relevant component (usually a prompt or retrieval configuration) until the failure cases pass. Once the experiment shows improvement without regressions, they promote the change to production. The same dataset that drove the improvement now serves as a regression test: before every deployment, they re-run their experiments to make sure new changes don't break previously fixed behaviors.
This creates a virtuous cycle. Observability (Part 1) gives you traces. Continuous evals (Part 3) surface failures from those traces. Experiments turn those failures into improvements. And the dataset grows over time into a comprehensive regression suite that represents the accumulated knowledge of how your agent should behave.
Another company uses experiments for a different purpose entirely: building trust with their new customers. Their agent serves enterprise buyers who need confidence that the agent can handle their specific use cases before approving a production rollout. During onboarding, the customer provides a set of questions they expect the agent to answer correctly, along with the expected answers. The team loads these into a test dataset and runs the agent experiment end-to-end, producing a scorecard showing exactly how well the agent performs on the customer's own questions. This gives buyers concrete evidence to bring back to their stakeholders. Experiments here go beyond being an internal development tool and become part of the GTM motion, establishing the trust required to go live in production.
TLDR
- Improving an agent is an experimental process, not a one-shot fix.
- Experiments combine three things: a dataset, supervised evals, and a variable to test.
- Supervised evals follow the same best practices as unsupervised (Part 3), with the added advantage of comparing against a known expected output.
- Test at the right level of isolation: prompt, RAG, or full agent. Start narrow, then validate end-to-end.
- Build datasets from real production failures and use them as both an improvement tool and a regression suite.
- Experiments can also serve as a trust-building tool for new customers evaluating the agent.
Up Next
In the next post in this series, we'll cover guardrails for agents, and how to build agents that self-correct their own behavior.
Interested in building production-ready agents? Connect with me on LinkedIn.
If you'd like to learn more about shipping reliable agents using these best practices, book a demo with an AI expert.
Want to see how we've applied these best practices internally? Check out our agent building stories: How We Turned a Vibe-Coded Jira Bot Into a Reliable Agent in Two Weeks & What "Building an Agent" Actually Means (And Why Most People Get It Wrong).