
Upsolve is an agentic platform which provides AI-driven business intelligence and analytics to their customers.
Upsolve selected Arthur to help them develop their Analysis AI Agent which lets users ask questions about their data in natural language, generates data insights and explains the reasoning behind each answer. Users can (and often do) add their own training data to the agent, to help the agent better understand their schema and business context. Upsolve needed to guarantee, as they rolled these Agents out across their customer base, any performance issues were immediately diagnosed and fixed in a way that made the entire system better. Additionally, providing measurable proof that it could answer their questions correctly made a huge difference in customers’ willingness to adopt.
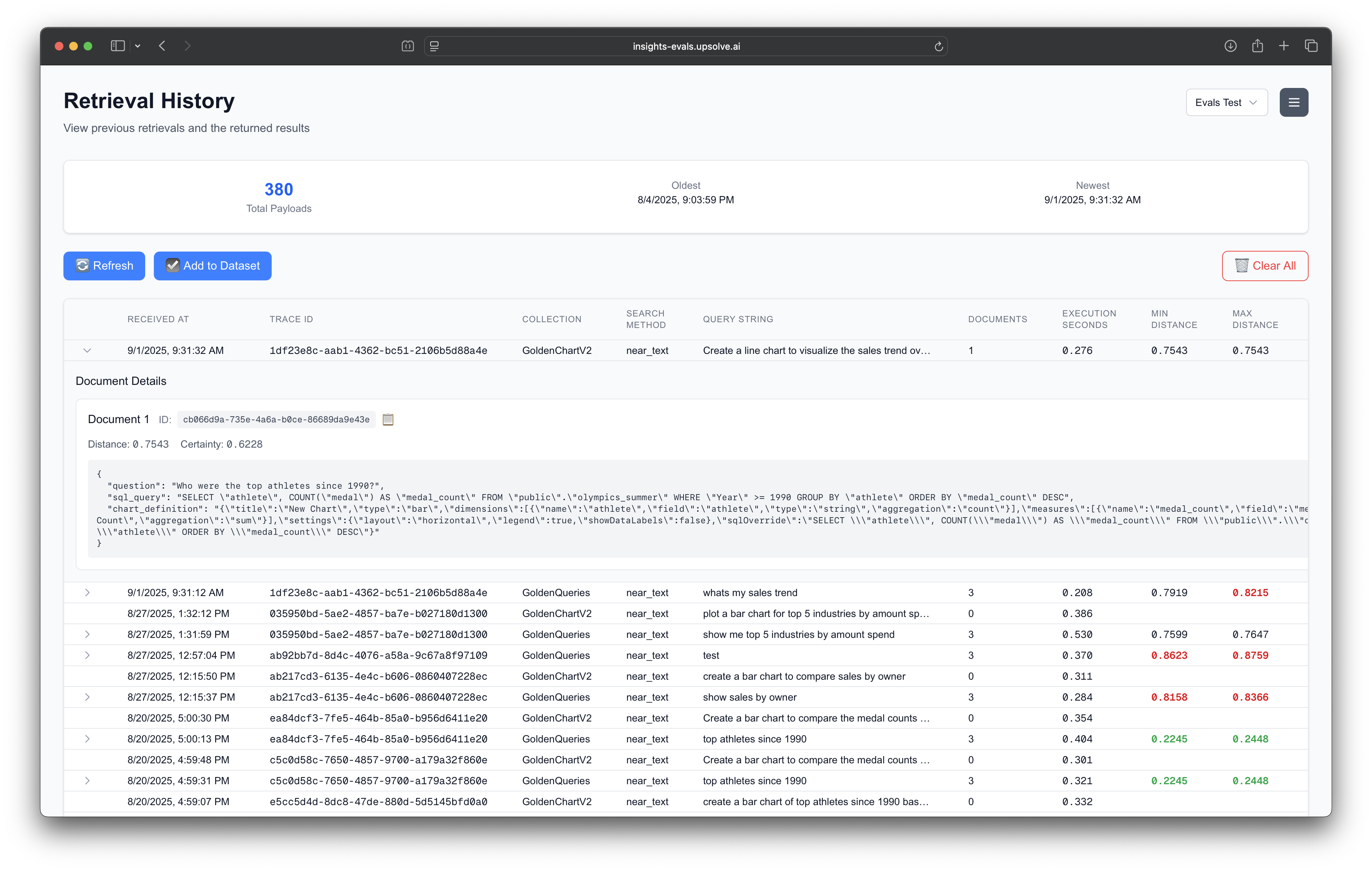
As a result, Upsolve engaged Arthur’s Forward Deployed Engineering (FDE) program and incorporated Arthur’s technology to ensure performance and build trust features directly into their product. The Arthur FDE integrated Arthur’s observability and experimentation solution which allowed Upsolve’s customers to quickly observe and improve the behavior of Upsolve’s Analysis AI Agent. The Arthur platform provided a level of visibility which allowed Upsolve to build trust with their customers that their Agent was working correctly and reliably.
Even after development, Arthur’s value continued to be felt. When OpenAI released GPT-5, Upsolve adopted the new model. Arthur quickly flagged a serious performance issue in the Agent introduced by GPT-5, an issue that would have otherwise gone unnoticed until customers were affected.
The Problem Statement
As Upsolve was building this feature and taking it to market, there were two things that kept coming up in conversations:
- How can we ensure that the Agent is working reliably as we expose it to our customers?
- How can customers trust that the Agent is doing what it’s supposed to and answering questions correctly?
The Upsolve Agent is a complex, multi-step planning Agent which performs the following actions for each user query:
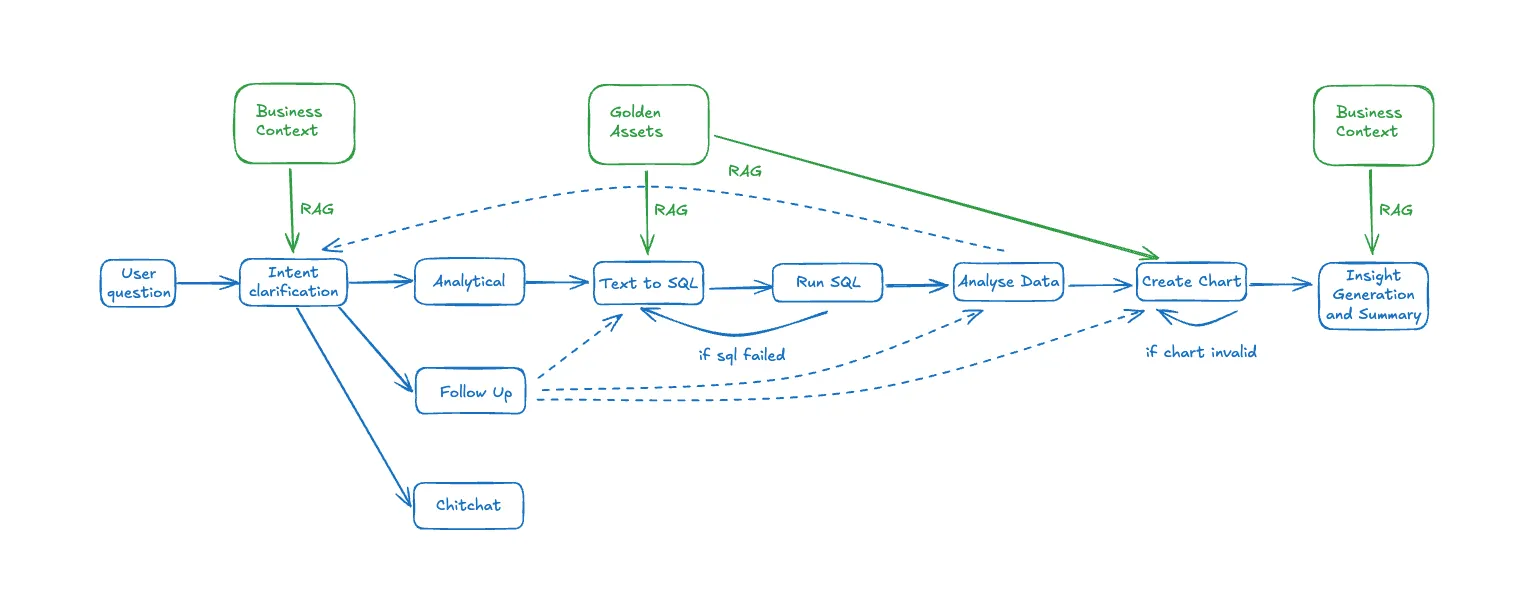
The Solution
The Arthur Platform gave Upsolve the ability to build trust with their users and effectively measure performance using Continuous Evals to drive the critical Agent Development Flywheel (see ADLC diagram).
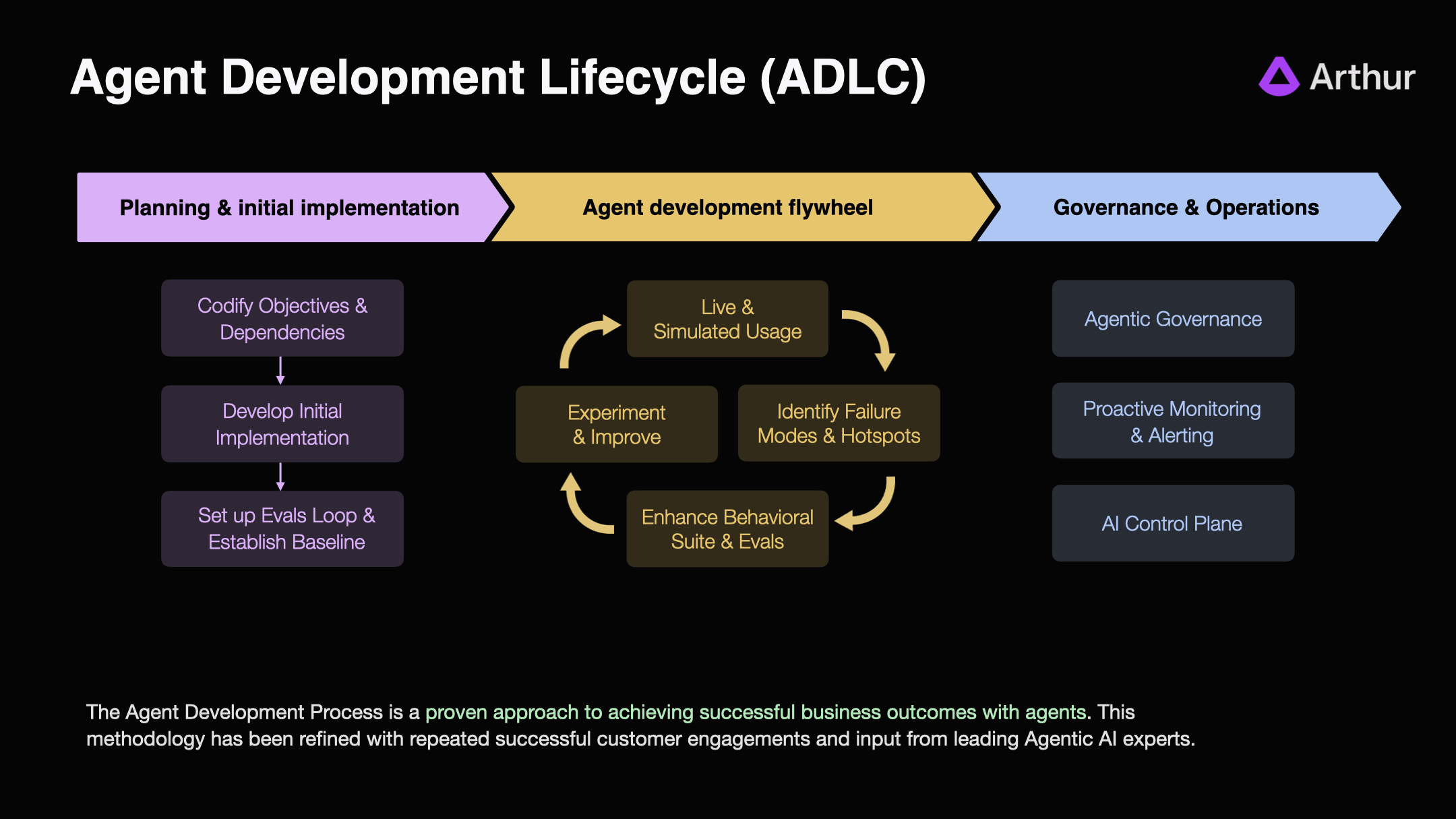
By instrumenting effective, domain-specific measures of performance, eg: evals, Upsolve was able to immediately measure and improve the performance of their Agent internally. Once the evals were developed, Upsolve then exposed these evals in a customer-facing application, along with tools that allowed customers to make tweaks and provide training examples to the agent so that they could optimize Upsolve’s Agent for their use-case.
Setting up the Baseline
At the beginning of the ADLC, the team instrumented the agent with tracing, so they could observe how the agent was thinking and acting internally.
This instrumentation captured key raw data such as: token counts, latencies, vector database retrieval performance, as well as the inputs and outputs from the language models, vector databases, and tools. This data was then fed into Arthur’s analytics and evals to give an instant, programmatic understanding of Agent Performance. Using this, developers were able to move beyond low-efficacy vibe checks and quickly improve the performance of the Analysis AI Agent.
Gathering the data
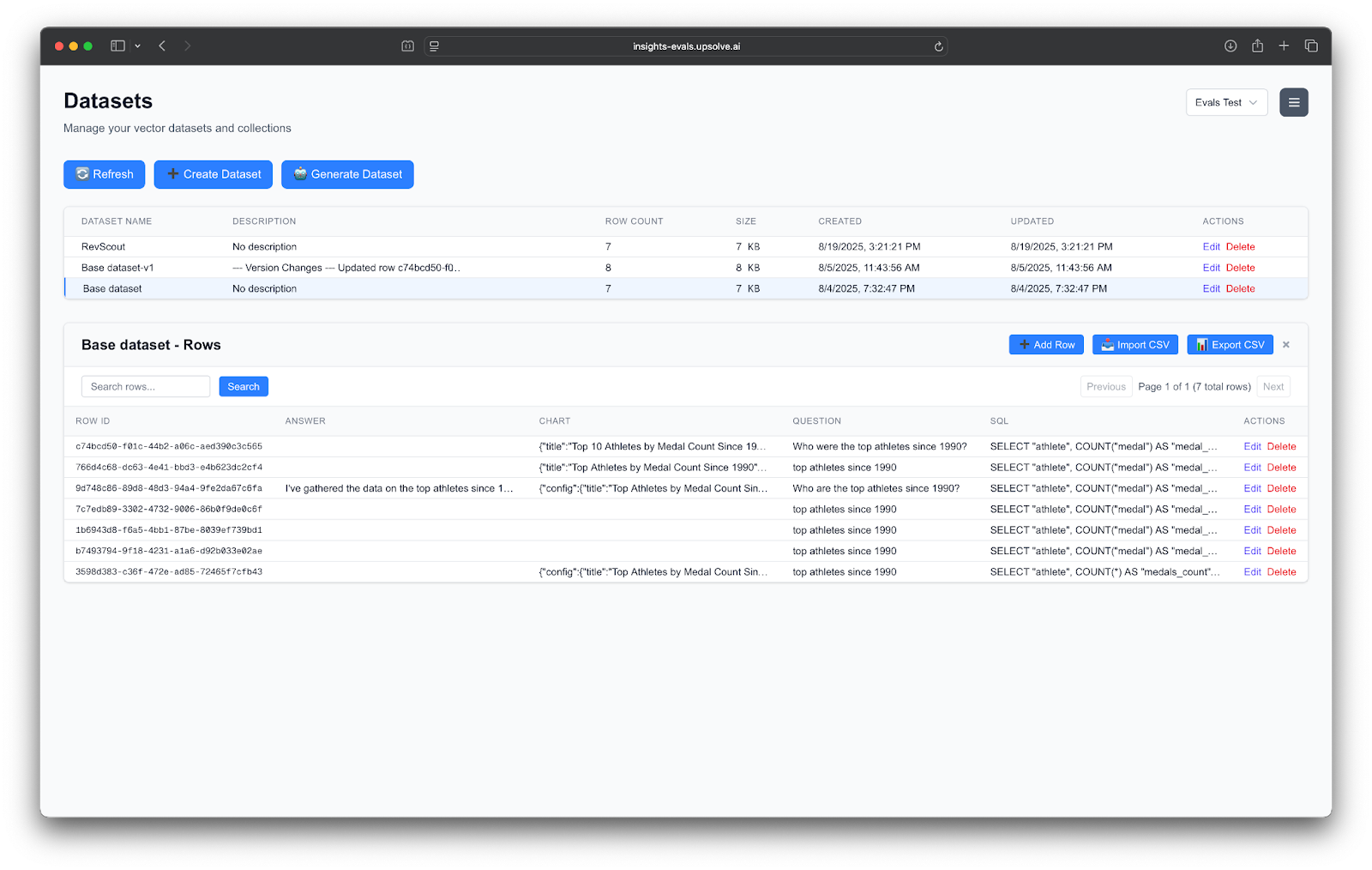
Once we started measuring the baseline performance of the agent, we started capturing “gold standard” datasets. So if the question was “Which Olympic athlete won the most medals?”, we would expect to get a SQL query that properly queried the database, a bar chart showing all of the athletes and their individual medal counts, and the final answer to be “Michael Phelps”.
At first, this dataset was manually curated and built by the Upsolve engineers as they iterated with the agent. To make it more scalable and methodical, they added functionality to their user interface that allowed them to save interactions into a gold standard dataset with a simple click using Arthur’s APIs.
Creating the Domain-specific Evaluations
Now that the team had baseline telemetry and a gold standard dataset of expected behavior, they were in a position to use the Arthur Experiments framework via Test Runs.
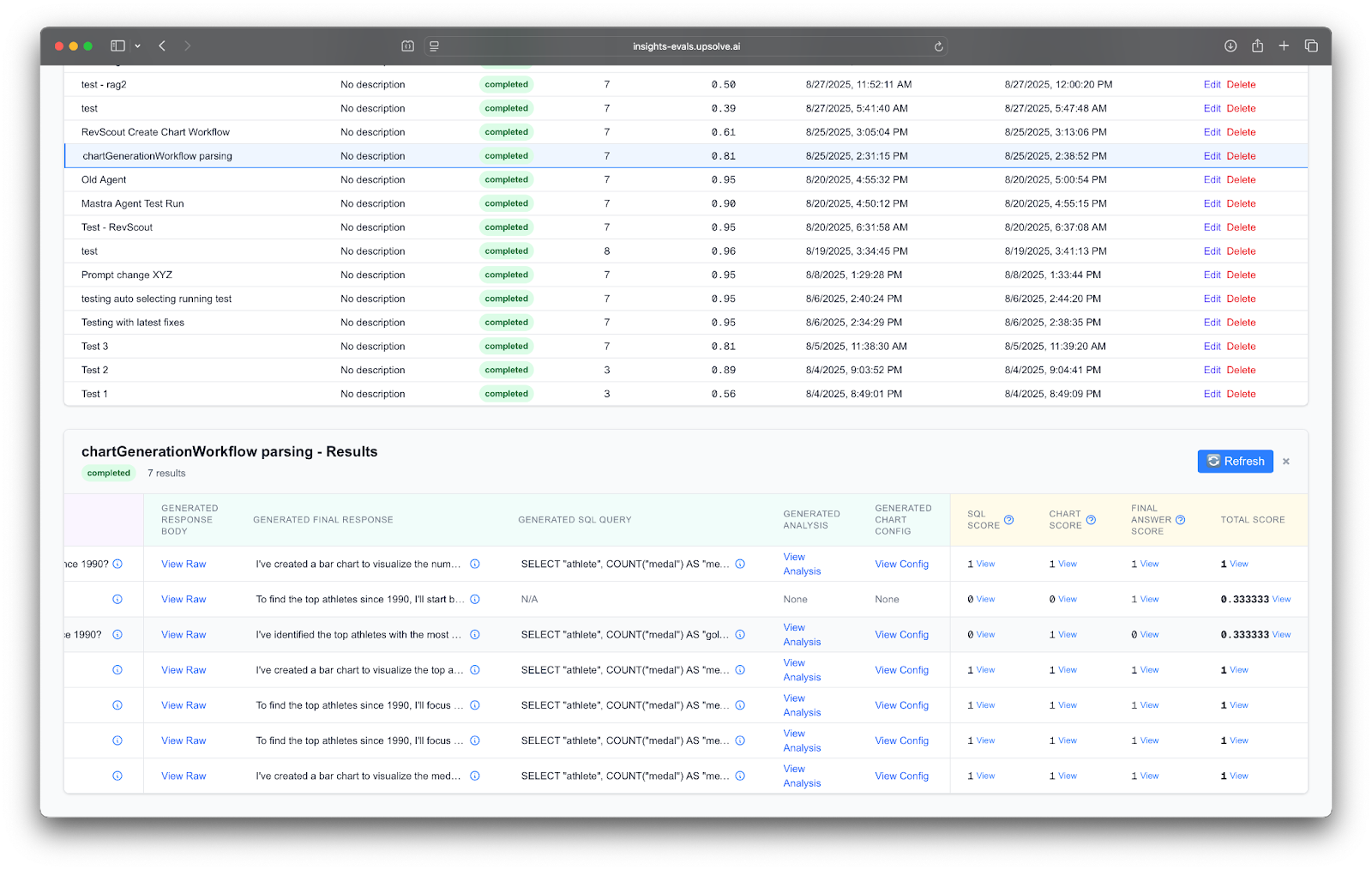
A Test Run is an automatic replay of all the records in a gold standard dataset against a potential deployment of an agent. By running through all of the gold standard questions on a test-version of the agent, the team could directly look at the before-and-after impact that the change would have on the expected answers. If there were unexpected changes in the response, the proposed agent change could be considered a regression, and conversely, if there were no unexpected changes in the response, the proposed agents change could be considered as having no negative impact on the behavior.
Tracking experiments
Finally, now that the team had a way to compare the behavior of their agent before and after a change, we then quantified the difference in performance using Domain Specific Evals. Because the agent returned three answers, a SQL query, a chart, and a final answer, we could score (a value of either 0 or 1, 0 being incorrect and 1 being correct) the performance of a change across these three dimensions. This was accomplished in the Arthur platform via an LLM-as-a-Judge technique, where the prompt for the evaluation documented the evaluation criteria - for example: the SQL query should have the same semantics as the reference SQL query.
Looking Forward
Arthur gives Upsolve a methodical way to deliver a robust, powerful Agentic AI solution that provides immense value for their users and creates massive strategic differentiation in the marketplace for them.
If you're a venture-backed startup building AI Agents and interested in working with Arthur to ship reliable AI agents to production, apply for Arthur's startup partner program. This program offers early access to Arthur's agentic tools, dedicated support, and resources to launch your AI safely in production.
Learn more about the Agent Development Lifecycle and how you can implement it in your organization here!
SHARE




