Introducing The Agent Development Lifecycle (ADLC)
A New Methodology to Build Reliable AI Agents

Agentic AI is a finicky, chaotic beast to build with right now. Monetizing Agents demands reliability. To help the community solve this problem, today we are releasing the methodology we’ve developed over the course of many projects with our amazing partners building mission critical systems. The Agent Development Lifecycle (ADLC) is a complete rethinking of the venerable SDLC which reflects the new reality of software systems. When used properly, this methodology guarantees successful, robust, reliable results.
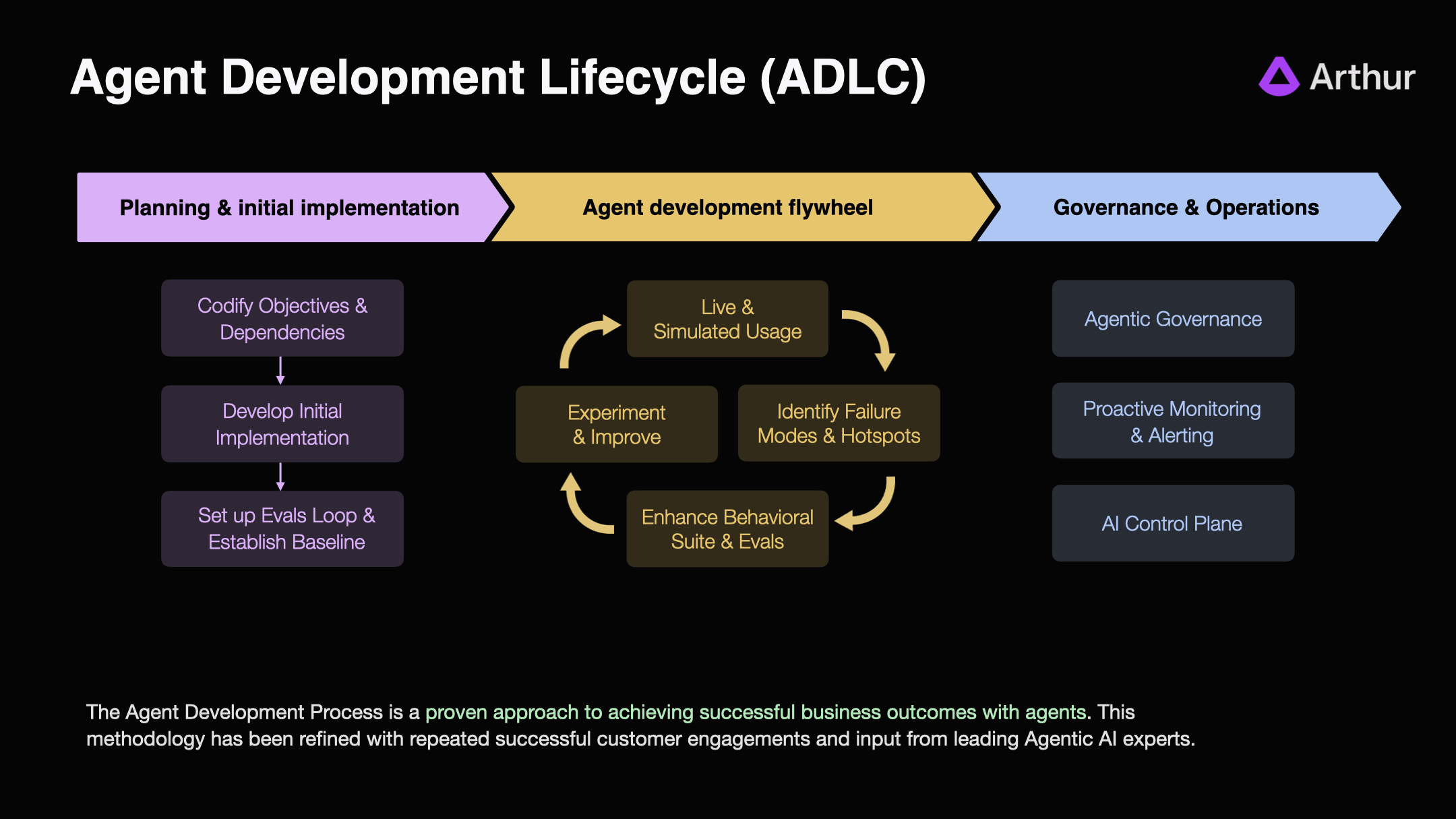
The ADLC is a wholly new approach to developing software that accounts for the massive differences between developing probabilistic reasoning systems vs traditional deterministic software. Contrast it with a typical SDLC process:
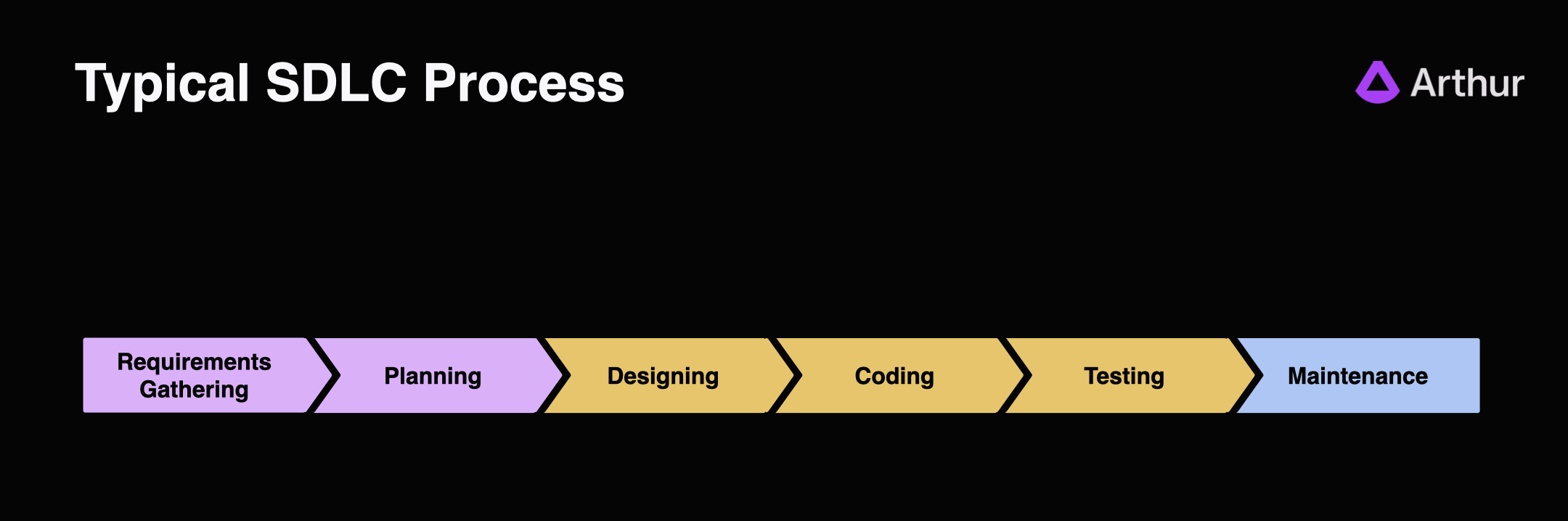
Compared with the SDLC, there are significant differences:
- Less time spent on upfront planning and design. It is still critical to align stakeholders on what you are trying to accomplish and expectations. But change requests and evolving the capabilities are less costly with Agentic AI.
- Significantly more emphasis on tuning and optimizing across a wide range of tasks and outcomes. This is the heart of the ADLC and the absolute most important part to nail.
- Even more focus on automated governance and oversight. This is an imperative due to the emergent behaviors these systems produce and relative autonomy compared with traditional systems.
Let’s break down the three major phases.
Planning & Initial Implementation 🤝
Creating alignment on the goals of the system, including intended behaviors, and then establishing the technical foundation is the starting point. This part is similar to traditional software development. The good news is that Agent systems are generally much easier to wire together and get to a functionally complete state that produces end-to-end results.
Key activities:
- Align on outcomes for the system and key KPIs to track success.
- Connect the agent to real systems and data sources.
- Set up observability for every tool call, retrieval, and reasoning step.
- Build human-in-the-loop feedback systems that capture user evaluations and feedback - thumbs up, thumbs down responses.
- Establish a baseline behavioral suite - a set of representative tasks that define what “good” looks like.
Now for the challenge: the amount of tuning effort to go from functionally complete to reliable and trustworthy is significantly higher with agents compared to traditional software. Especially if you are relying on vibes to get you there. In the next section we present a methodical approach to this challenge to ensure success, an approach we call The Agent Development Flywheel.
The 💜 of the ADLC: The Agent Development Flywheel
With traditional software application, when your system was functionally complete the lion’s share of the work was often done. With agentic AI, getting to a functionally complete state tends to be pretty quick. Going from functionally complete to reliable is where the work lies.
This is why the heart of the ADLC is the Agent Development Flywheel. This continuous process takes you from a functional pilot that produces great, yet unreliable results to a system that is robust and trustworthy in production.
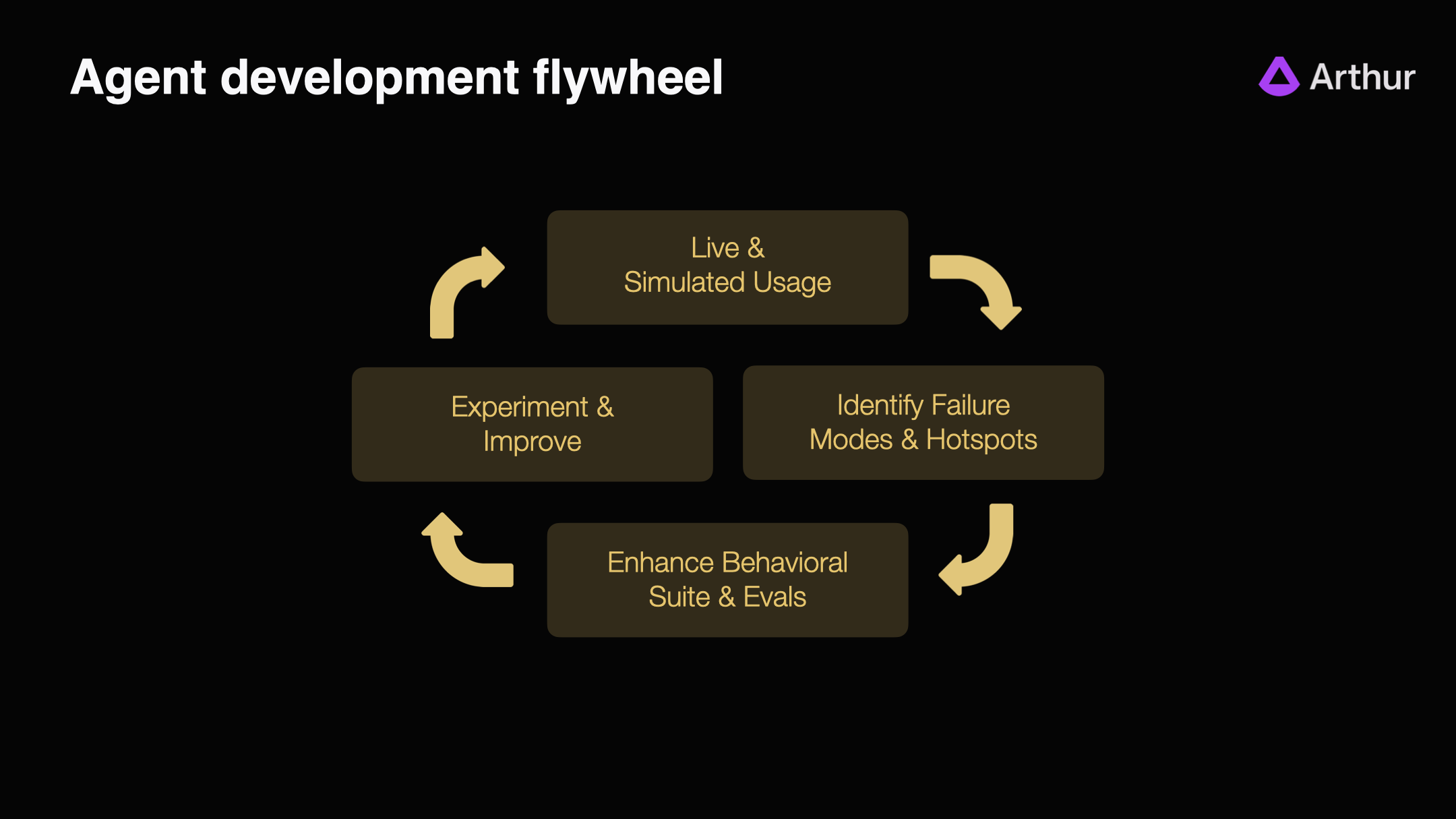
The key at this step is moving beyond vibes to a methodical approach, anchored in a well-curated set of evals. That’s something we’ve made very easy on our platform. A well-curated eval suite is the single biggest unlock to guarantee success in an Agentic System.
Step 1: Live & Simulated Usage
Teams roll out agents gradually first to internal test groups, then to controlled pilots, and finally to production traffic. Each interaction provides behavioral data that helps in evaluation and iteration. The goal of this step is to ensure that you have controlled usage to generate performance data that can be used to improve the agent systems performance.
Leading teams also run large-scale simulated runs in parallel, stress-testing how the agent performs under new prompts, edge cases, or tool combinations before those changes ever reach end users.
Step 2: Identify Failure Modes and Hotspots
Every reliable agent begins as a bundle of unknowns: brittle prompts, unpredictable retrievals, fragile orchestration logic.
By tracing decisions, comparing outputs against evaluation benchmarks, and correlating results with business KPIs, teams can quickly surface failure modes (patterns where the agent consistently underperforms).
The goal of this step is to be equipped with the tools to quickly surface problems with prompts, models, rag retrievals, tool selection, orchestration sequences, and all other key agent behaviors.
Step 3: Enhance Behavioral Suites and Evals
Once failure patterns are identified, they should be used to enhance your evaluation test suite. Feeding these edge cases back into their evaluation suites ensure that the same problem can never silently reappear.

This evolving suite acts as the agent’s control system - a safety net that ensures progress doesn’t come at the cost of reliability.
Step 4: Experiment and Improve
With robust evals in place, teams can confidently ship updates to prompts, context retrieval strategy, and add new tools. This ensures that new iterations don’t cause regressions.
Instead of shipping blind, every modification is grounded in metrics:
- Did reasoning quality improve?
- Did business KPIs move in the right direction?
- Did we avoid regressions elsewhere?
For many, this step can seem a bit daunting, but once you’ve spent a bit of time creating evals it quickly becomes second nature. We are always happy to help people get started, we are doing a lot of that right now!
Agentic Governance 🛡️
The #1 question I’ve been asked recently is how to effectively govern these systems. Governance means a lot of different things to people.
Three key requirements for good Agent Governance:
- Ensure adherence to policy (expected behaviors)
- Communicate KPIs to diverse stakeholders
- Automatically detect and escalate performance concerns in realtime
This should all be automated, and it should be easy. I will be publishing a blog post entirely on this topic in the next couple of weeks, follow me on LinkedIn to read it when it drops.
Getting started with the ADLC
The Agent Development Lifecycle is a framework. It gives enterprises a clear path to move beyond experimentation, grounding every stage of agent development in measurable outcomes, observability, and continuous improvement.
At Arthur, we’ve refined this lifecycle through our work with leading companies deploying real-world agents, from financial services and airlines industries, to customer operations and data platforms. Our forward-deployed engineers help teams adopt the ADLC from day one- standing up evaluation pipelines, instrumentation, and governance frameworks that build long-term reliability into every release.
If your organization is building AI agents, learn more about how you can implement ADLC in your ecosystem.
Want to go deeper on building reliable agents? Check out Arthur's Best Practices for Building Agents series, including Part 1: Observability and Tracing, Part 2: Prompt Management, Part 3: Continuous Evaluations, Part 4: Experiments & Supervised Evals, Part 5: Guardrails, and Part 6: Agent Discovery & Governance. And if you're building an internal tool and want to see what the path from prototype to production looks like in practice, read about how we turned a vibe-coded Jira bot into a reliable agent in two weeks.