
Over the past few months, we published a six-part series on building reliable AI agents. The series distills lessons from our Forward Deployed Engineering team, based on real-world deployments of production agents across startups and enterprises.
This post is a recap of the six part series and if you're building an agent right now, treat this as your checklist for what's next.
TLDR
- Observability and tracing. Instrument every LLM call, tool invocation, RAG call, and key decision point so you can see what your agent did and why.
- Prompt management. Store prompts externally, version them, template them, and test new versions before promoting.
- Continuous evaluations. Run unsupervised evals on production traffic to catch failures the moment they happen.
- Experiments and supervised evals. Validate prompt, RAG, and agent changes against a fixed dataset before they ship.
- Guardrails. Intercept bad inputs before they reach the model and bad outputs before they reach the user.
- Discovery and governance. Make the agent discoverable, auditable, and owned so it can clear enterprise review.
If you only read one, start with Part 1. Tracing is the foundation the rest of the series depends on.
Part 1: Observability and Tracing
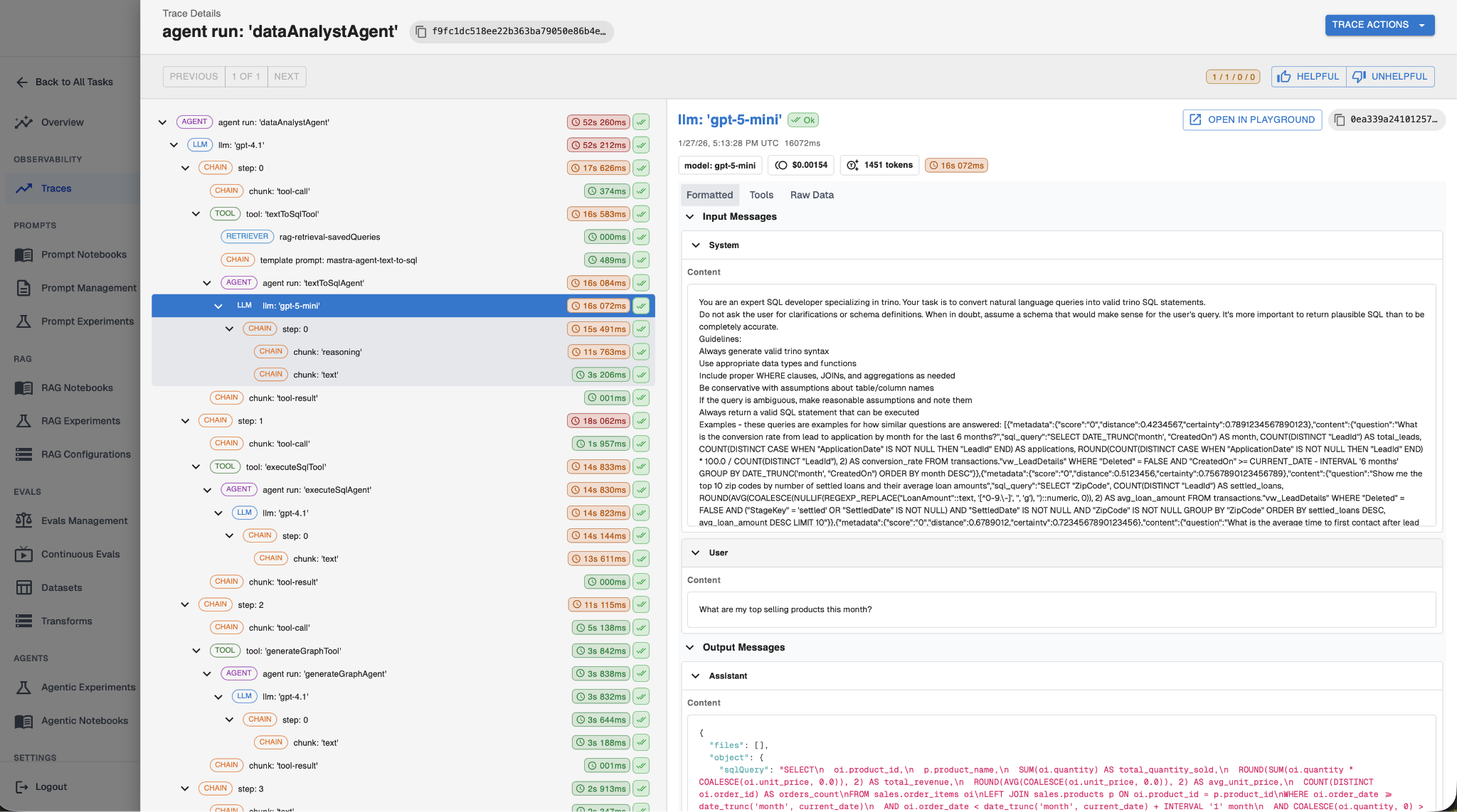
Why you should care: When a user reports a bad response, you have no way to know whether it was caused by a bad prompt, a bad retrieval, a bad tool call, or something else. With traces, you can see exactly what your agent did and where it went wrong.
In this part, we covered the five things you need to instrument at a minimum: every LLM call (with prompts, completions, tokens, and cost), every tool invocation, every retrieval, your application metadata (user IDs, session IDs), and the key decision points in your agent's logic.
You can’t fix what you can’t see, so without tracing you can’t build evals or experiments. Observability and tracing is the bare minimum an agent must have before you can start improving it.
→ Read Part 1: Observability and Tracing
Part 2: Prompt Management
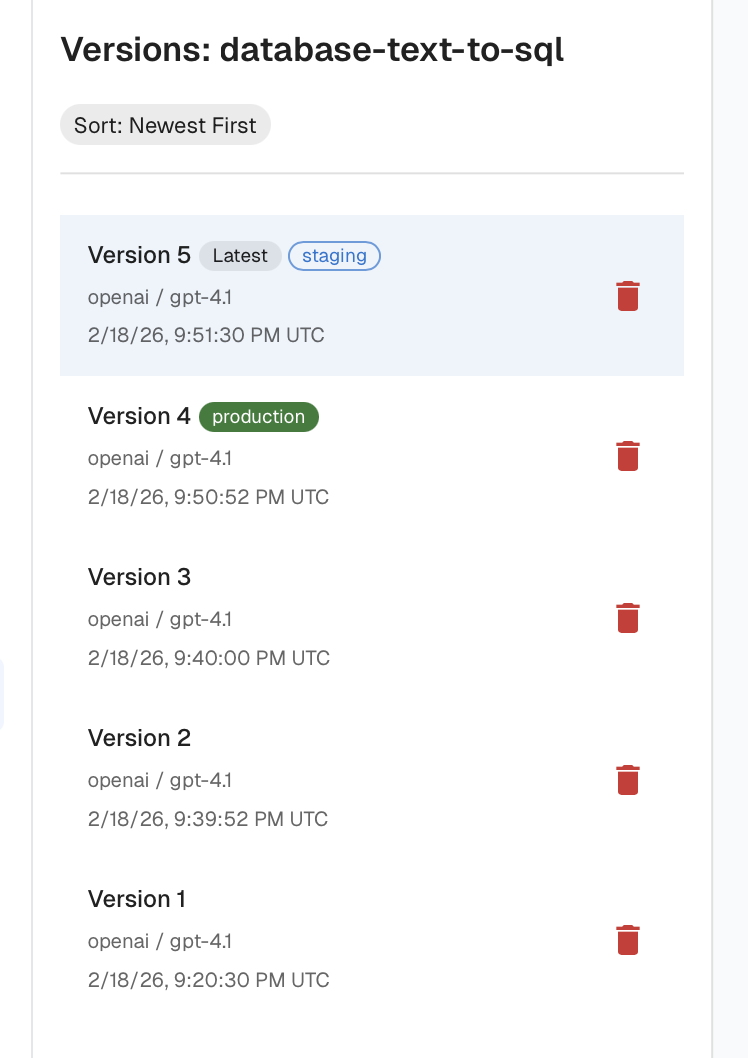
Why you should care: If your prompts live as hardcoded strings inside your application, every prompt tweak requires a full redeploy and every change risks a silent regression.
Part 2 covers the four things mature prompt management requires:
- External storage. Keep prompts out of your application code so non-engineers can contribute and you can iterate without redeploying.
- Versioning and rollback. Every prompt should have explicit versions, change history, and environment tags (dev, staging, production) so you can promote and revert with confidence.
- Templating. Use variables and conditional logic to keep prompts small and dynamic instead of one bloated mega-prompt.
- Experimentation and regression testing. Replay historical inputs against new prompt versions before you promote them.
→ Read Part 2: Prompt Management
Part 3: Continuous Evaluations

Why you should care: Most teams find out their agent is misbehaving when a user complains. By that point, multiple users have been affected and you're scrambling through traces to figure out what happened. Continuous evals give you automated signals the moment something goes wrong.
Continuous evals are unsupervised evals running against live production traces. Unsupervised evals assess behavior using only the agent's own context, so they don't need a known correct answer the way supervised evals do. Here’s the distinction between the two:
The best practices:
- Make evals binary, not scored on a range. LLMs are inconsistent rangers, and ranges push the judgment back onto a human.
- Make evals specific, not generic. "Did the agent reference information not in the retrieved docs?" beats "was the response good?"
- Provide examples in the eval prompt, especially edge cases on the decision boundary.
- Eval costs add up fast on every interaction, and a smaller model with a tight prompt often matches a larger one.
- Use programmatic checks for deterministic things. Don't ask an LLM to verify math or SQL schema validity.
Traces from Part 1 give you the data. Prompt management from Part 2 gives you a way to fix what evals find.
→ Read Part 3: Continuous Evaluations
Part 4: Experiments & Supervised Evals
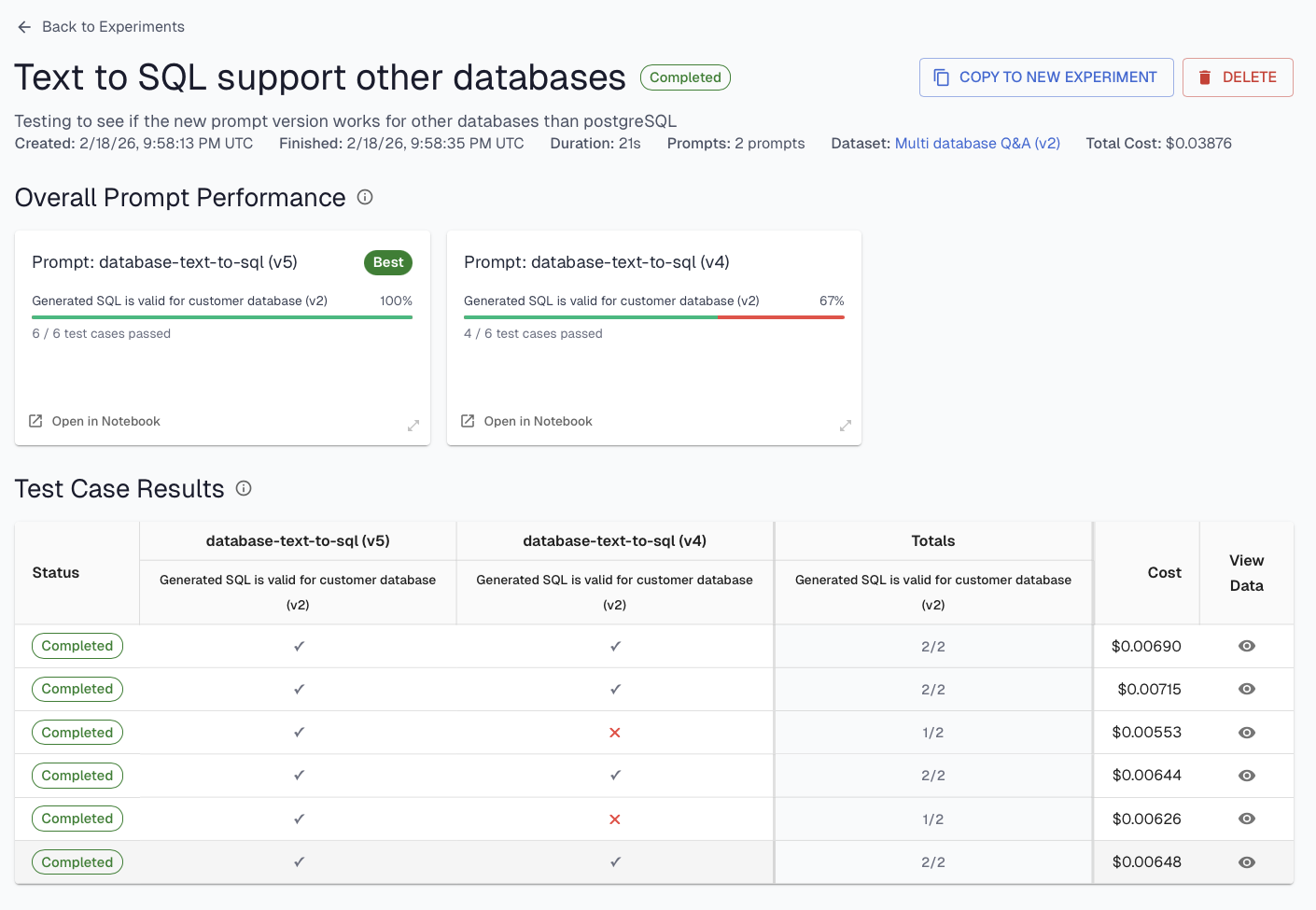
Why you should care: Every prompt change, every model swap, every retrieval tweak is a chance to break something that was working. Experiments let you verify changes work, and don't introduce regressions before they ship to production.
An experiment is three things: a dataset, a set of supervised evals, and a variable you're testing. The dataset and evals stay fixed and the variable is the parameter you're changing.
Part 4 also covers the three levels of experimentation, ordered by speed and scope. Prompt experiments run a prompt in isolation against known inputs and are the fastest loop. RAG experiments test retrieval changes against expected documents. Full-agent experiments validate end-to-end before you promote. The advice: start narrow, iterate quickly on individual components, then validate end-to-end.
→ Read Part 4: Experiments & Supervised Evals
Part 5: Guardrails
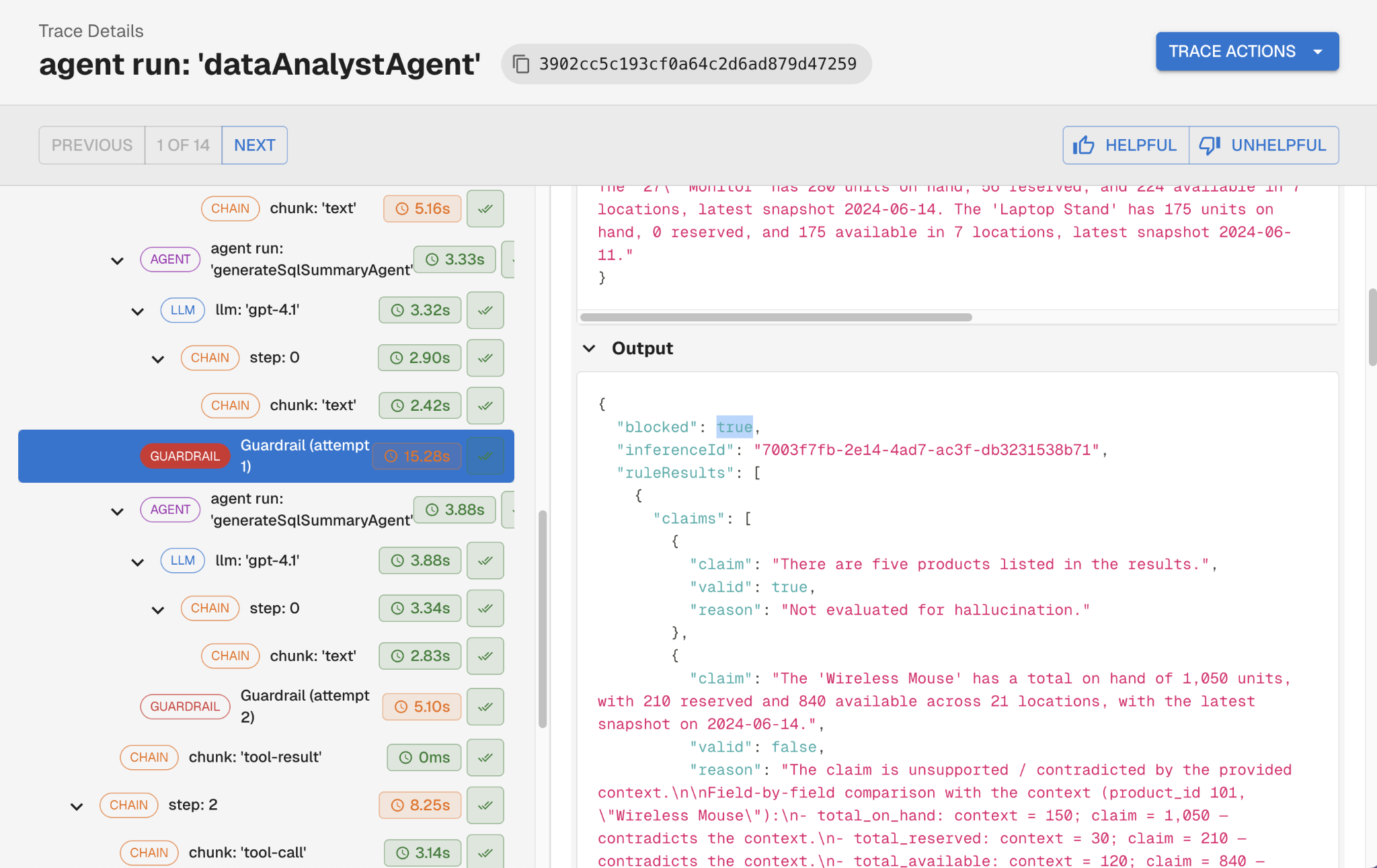
Why you should care: Guardrails intercept agent behavior in real time, before a bad input reaches your LLM or a bad output reaches your user.
Guardrails can be implemented into two ways based on where they run.
Pre-LLM guardrails run before the user's input hits the model. Common uses: PII detection and redaction, sensitive data blocking, and prompt injection detection.
Post-LLM guardrails run after the model responds, but before that response is acted on. Common uses: hallucination detection, toxicity, tool and action validation, and output format compliance.
Post-LLM guardrails can also drive a self-correction loop. Instead of just blocking a bad response, you feed the flagged issues back to the LLM with a targeted correction prompt:
Here's what you said -> here's what was unsupported -> revise -> the agent retries -> the user only ever sees the corrected output.
Part 6: Discovery and Governance
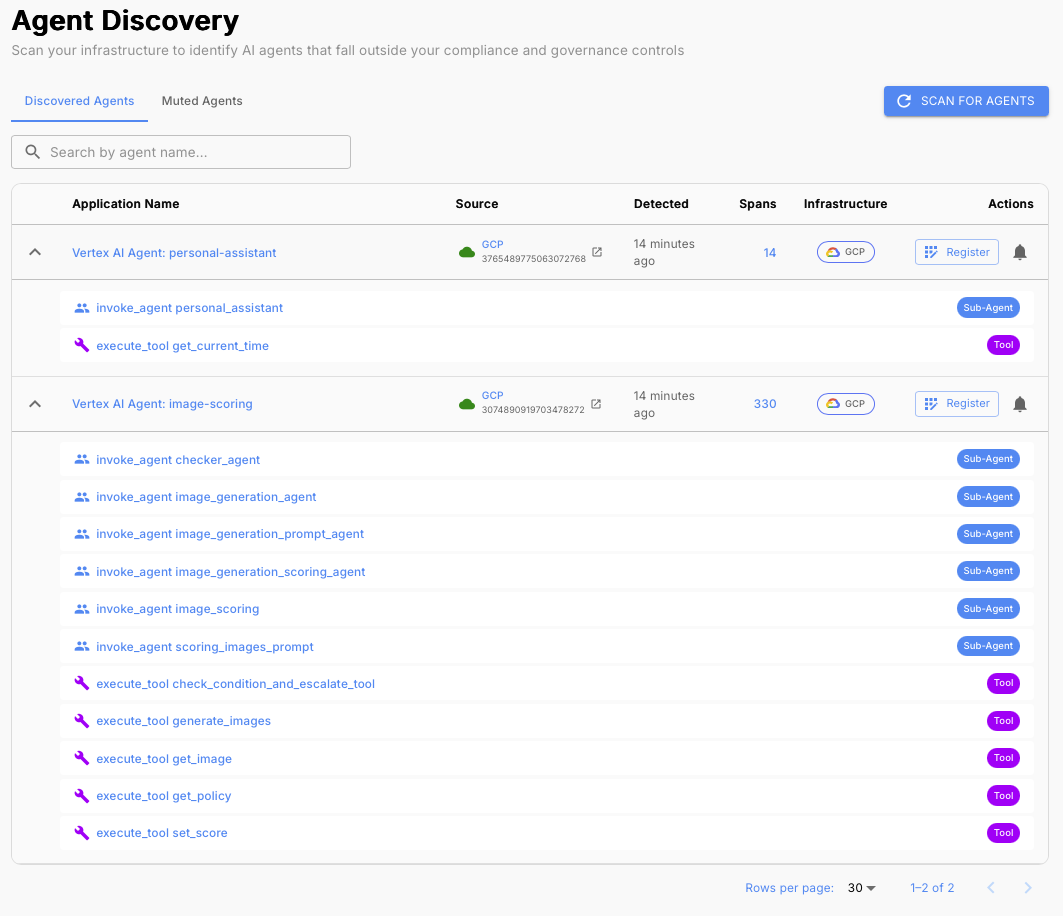
Why you should care: A great agent that can't pass governance review never ships into the enterprise. As agent adoption grows, organizations are losing track of what agents are running, what data they can access, and who's accountable. Enterprise governance teams are responding by requiring agents meet specific standards before they're allowed to operate.
If you did the work in Parts 1 through 5, you're most of the way there. The Part 6 checklist:
- Use frameworks with out-of-the-box telemetry and emit traces to centralized, well-known destinations. Governance tooling discovers agents by finding their telemetry. An agent that emits no traces is invisible to the organization.
- Instrument thoroughly so reviewers can assess your full risk surface: tools, subagents, LLM providers, data sources.
- Implement continuous evals and guardrails, and be ready to demonstrate them. Continuous evals (Part 3) and running guardrails (Part 5) are concrete evidence of production readiness.
- Assign clear ownership. Every agent needs a named owner accountable for its behavior. An agent without an owner is a red flag in any compliance review.
→ Read Part 6: Discovery and Governance
Where to Start
If you're new to the series, start with Part 1: Observability and Tracing. You can't manage prompts you can't trace, you can't run evals without the data tracing produces, and you can't pass a governance review without telemetry. Then work your way through:
- Part 2: Prompt Management
- Part 3: Continuous Evaluations
- Part 4: Experiments & Supervised Evals
- Part 5: Guardrails
- Part 6: Discovery and Governance
Want to see these practices applied to a real agent? Check out How We Turned a Vibe-Coded Jira Bot Into a Reliable Agent in Two Weeks, a step-by-step walkthrough of applying every part of this series to an internal Slack-to-Jira bot, from initial instrumentation through prompt iteration and eval-driven fixes.
You can also get started for free at platform.arthur.ai/signup or book a demo with an AI expert → https://www.arthur.ai/demo
SHARE





.png)