Introducing Arthur Bench: The Most Robust Way to Evaluate LLMs
Introducing Arthur Bench, the most robust way to evaluate LLMs

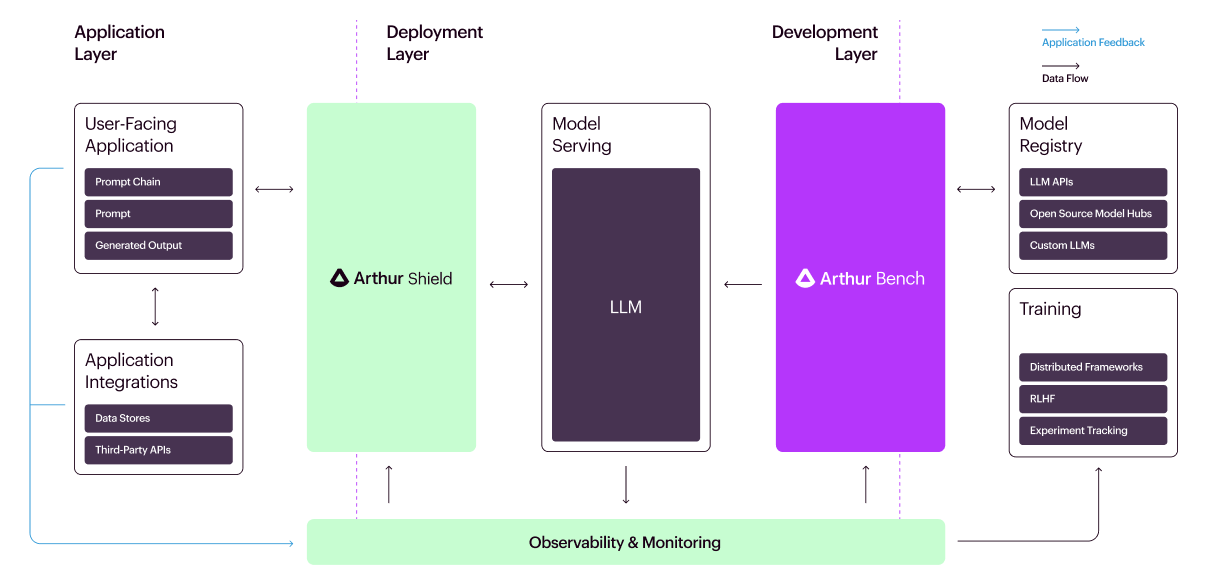
At Arthur, we’ve spent this year building out our suite of monitoring tools for large language models to help businesses quickly and safely integrate LLMs into their operations. We launched Arthur Shield back in May, which acts as a firewall to protect organizations against the most serious risks and safety issues with deployed LLMs.
Today, we’re excited to introduce our newest product: Arthur Bench, the most robust way to evaluate LLMs. Bench is an open-source evaluation tool for comparing LLMs, prompts, and hyperparameters for generative text models. This open source tool will enable businesses to evaluate how different LLMs will perform in real-world scenarios so they can make informed, data-driven decisions when integrating the latest AI technologies into their operations.
Here are some ways in which Arthur Bench helps businesses:
- Model Selection & Validation: The AI landscape is rapidly evolving. Keeping abreast of advancements and ensuring that a company’s LLM choice remains the best fit in terms of performance viability is crucial. Arthur Bench helps companies compare the different LLM options available using a consistent metric so they can determine the best fit for their application.
- Budget & Privacy Optimization: Not all applications require the most advanced or expensive LLMs. In some cases, a less expensive AI model might perform the required tasks equally as well. For instance, if an application is generating simple text, such as automated responses to common customer queries, a less expensive model could be sufficient. Additionally, leveraging some models and bringing them in-house can offer greater controls around data privacy.
- Translation of Academic Benchmarks to Real-World Performance: Companies want to evaluate LLMs using standard academic benchmarks like fairness or bias, but have trouble translating the latest research into real-world scenarios. Bench helps companies test and compare the performance of different models quantitatively so that they are using a set of standard metrics to evaluate them accurately and consistently. Additionally, companies can configure customized benchmarks that they care about, enabling them to focus on what matters most to their specific business and their customers.
In conjunction with this, we’re also excited to unveil the Generative Assessment Project. GAP is a research initiative ranking the strengths and weaknesses of language model offerings from industry leaders like OpenAI, Anthropic, and Meta. As part of our mission to make LLMs work for everyone, we will continue to use GAP to share discoveries about behavior differences and best practices with the public. Learn more about this initiative and see some of our initial experiments here.
“As our GAP research clearly shows, understanding the differences in performance between LLMs can have an incredible amount of nuance. With Bench, we’ve created an open-source tool to help teams deeply understand the differences between LLM providers, different prompting and augmentation strategies, and custom training regimes,” said Adam Wenchel, co-founder and CEO of Arthur.
As mentioned, Arthur Bench is completely open source, so new metrics and other valuable features will continue to be added as the project and community grows. You can visit our GitHub repo, or click here to learn more about what it has to offer.