
Last week, Google announced a new dermatology app that will use Computer Vision to automatically classify skin conditions from images and provide “dermatologist-reviewed information and answers to commonly asked questions, along with similar matching images from the web” for the matching skin condition.
Why it’s important: Google first published their model in Nature in 2020. Moving to embed that technology into a public-facing app highlights the continued impact of computer vision in the healthcare industry.
Concerns around bias: Google’s announcement prompted concerns that the model would be less accurate for darker-skinned people. According to the Nature paper Google published, Fitzpatrick Type V and VI skin, which broadly correlates to brown and dark brown skin, accounted for under 3.5% of the train set. That class imbalance could cause the model to underperform on darker-skinned people -- raising concerns about disparate impact bias.
Things we noticed in Google’s validation set numbers
As others have noted, just 2.7% of the validation set examples from the Nature publication used Type V or VI skin, so it’s difficult to assess how well the model generalizes to dark skin.
We also noticed that the topline accuracy numbers Google reported for ethnicity-level accuracy might obscure racial disparities in the validation set. In slides shared with Motherboard (Vice’s tech publication), Google reported that its model had an 87.9 percent accuracy rate for Black patients -- the highest of any ethnicity group. The Nature publication also reported a relatively high accuracy rate for Black patients (though we couldn’t find the 87.9 percent figure) that were on par with accuracy rates for White patients.
Just looking at the accuracy rate, however, can obscure potential racial disparities. In the supplementary figures, Google’s Nature publication reported its average sensitivity, which they calculate by averaging sensitivity across the 26 conditions the model considers. This has the advantage of weighting each condition’s performance equally, so common conditions don't skew the accuracy rates as much.
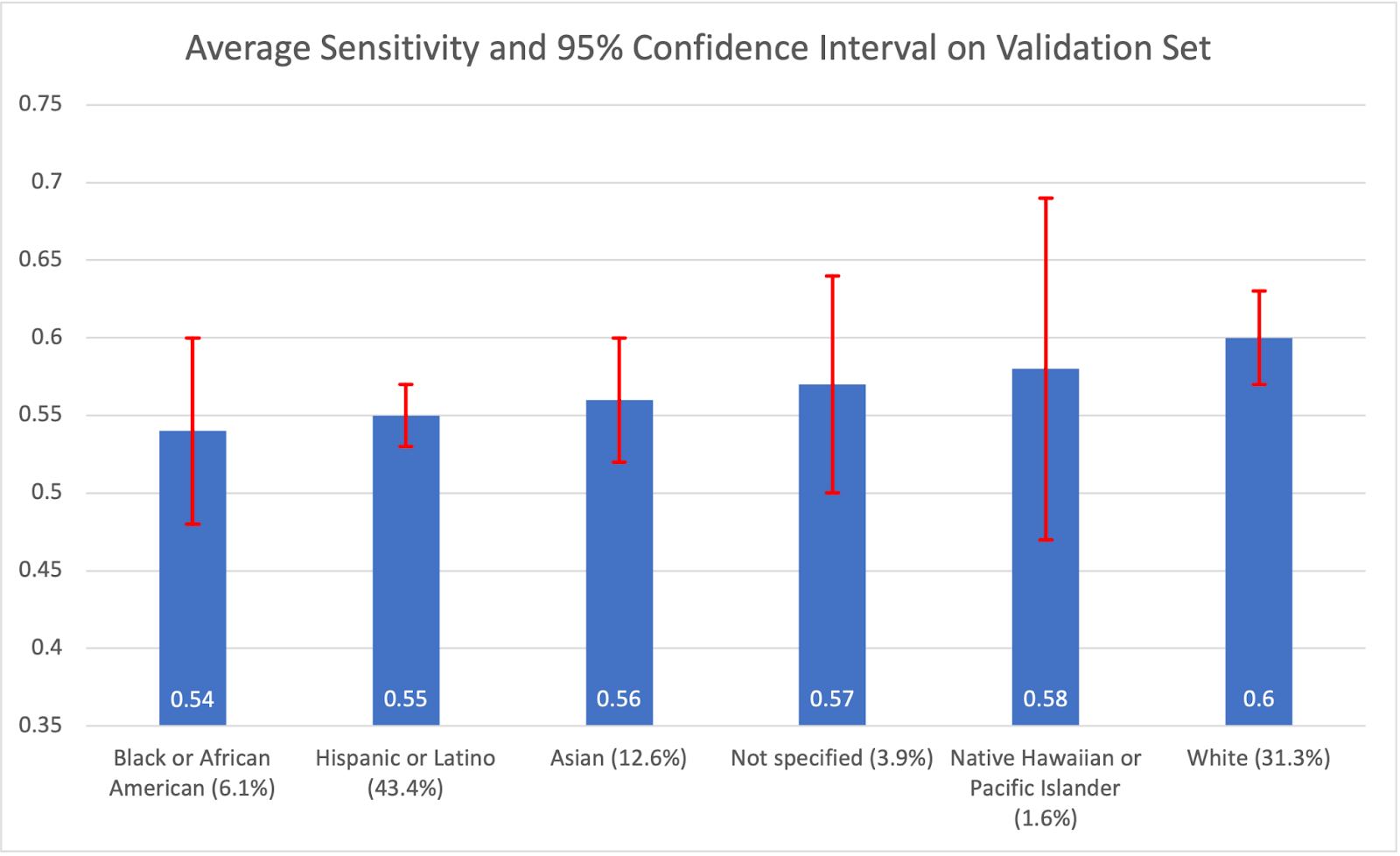
Looking at average sensitivity, Google’s model performed worst on Black patients. The difference between accuracy and sensitivity rates for Black patients could suggest that the Black patients in their validation set were more likely to have a common condition (eg. Acne) that the model can perform very well on, but when it comes time to detect a more serious but less common condition like skin cancer, the model underperforms for Black patients.
Non skin-cancer conditions could be overrepresented in the Black sample because the prevalence of skin cancer in non-White people is lower than the prevalence for White people (however, skin cancer diagnoses in non-White people often come at a more advanced stage -- increasing the lethality rate). Imagine we randomly sample a group of Black patients with some type of skin condition (not exclusively skin cancer) and an equally sized group of White patients with some type of skin condition: if the prevalence of skin cancer is higher in the White population than the Black population, a random sampling process will result in the White sample having more patients with skin cancer and the Black sample having more patients with some non-cancerous skin condition. The code below demonstrates this phenomenon.
Whatever the underlying cause for the disparities, low sensitivity rates for Black patients could exacerbate existing racial inequalities in healthcare.
A Brief History of Bias in Computer Vision Models
As computer vision research has exploded, there’s been an increased interest in auditing these models for potential racial and gender bias. In 2018, Gebru and Buolamwini found three major commercial facial recognition systems performed significantly worse on darker-skinned people and women than lighter-skinned people and men. That landmark study inspired further research into auditing other computer vision models that might exhibit these pernicious biases.
Studies have also examined CV models in a healthcare context: last year, a study looked at chest X-ray diagnosis computer vision models and found that they exhibited TPR (true positive rate) disparities with respect to gender, race, and age. TPR disparities with respect to race were especially prominent with the models performing best on White patients and worst on Hispanic patients.
Difficulties in auditing dermatology CV models
After Google’s announcement, our team looked into conducting an audit of a dermatology computer vision model using an external test set to look for possible racial or gender bias. However, as we explored the feasibility of such a study, it became clear that there were no open source dermatology datasets that included metadata on each patient’s race or skin type. External audits are important methods of ensuring that models in production are equitable and inclusive: balanced datasets that include patient skin type and race metadata are critical to enabling these audits, and we at Arthur hope that the healthcare and tech industries work together to create these datasets and conduct these audits.
SHARE





