Downstream Fairness: A New Way to Mitigate Bias

Note: This blog post and code could not have been done without the fantastic research from our former research fellow Kweku Kwegyir-Aggrey and former machine learning researcher Jessica Dai. You can view their paper here.
Motivation
Many organizations utilize binary classifiers for a variety of reasons, such as helping loan providers decide who should get a loan, predicting whether or not something is spam, or providing evidence on whether or not something is fraudulent. These use cases require specific classification thresholds. Imagine an algorithm is predicting whether or not someone qualifies for a loan. One way to do this is to attribute a probability to a person, and if that probability is above a certain threshold (let’s say 0.5), then they can get a loan. If not, then they will be rejected.
What is the proper threshold to use in these scenarios? Taking spam detection as an example, the threshold set will determine how often an email is classified as spam. A threshold of 0.8 is less permissive than a threshold of 0.4. That is why many organizations have threshold ranges for their algorithms, which can complicate things.
Current bias mitigation techniques, such as the one we offer at Arthur, traditionally require you to change your classification threshold to meet some fairness definition. This change in threshold could be outside the range that your company allows, creating questions as to whether or not you can be fair. Further complicating these situations are models that are utilized in many downstream applications, where different threshold ranges (and possibly different fairness definitions) need to be utilized.
Downstream fairness solves this dilemma. It’s an algorithm that achieves various fairness definitions (equalized odds, equal opportunity, and demographic parity) in a threshold-agnostic way, meaning that a company won’t have to adjust their threshold. Instead it operates on a binary classifier’s output probabilities to achieve a fairness definition. And this is all done with minimal accuracy loss! For the remainder of this blog post, we’ll be digging deeper into this algorithm and how to use our new open source code.
Downstream Fairness
Saving the mathematical details for the Geometric Repair paper, we will discuss the essence of how Downstream Fairness works and provide code snippets from our open source package. First off, downstream fairness is a post-processing algorithm that operates on the training dataset (or some representative dataset) for the model we are trying to make fair. The data needs to contain some key information: the prediction probabilities for each data point, the classification label, and a column containing the sensitive attribute on which you are operating.
| Prediction Probabilities | Prediction Labels | Group Information |
How the algorithm works is that it looks at the distribution of prediction probabilities per group of our original model and then computes a repair of each of those distributions for demographic parity. The reason this works for demographic parity is because the definition of demographic parity (equalizing selection rates for each group) only requires prediction probabilities and group information.
On the implementation side, this process produces an adjustment table. The adjustment table contains how much the prediction probabilities need to be adjusted to achieve demographic parity, for each group. Below is an example of how that table looks:
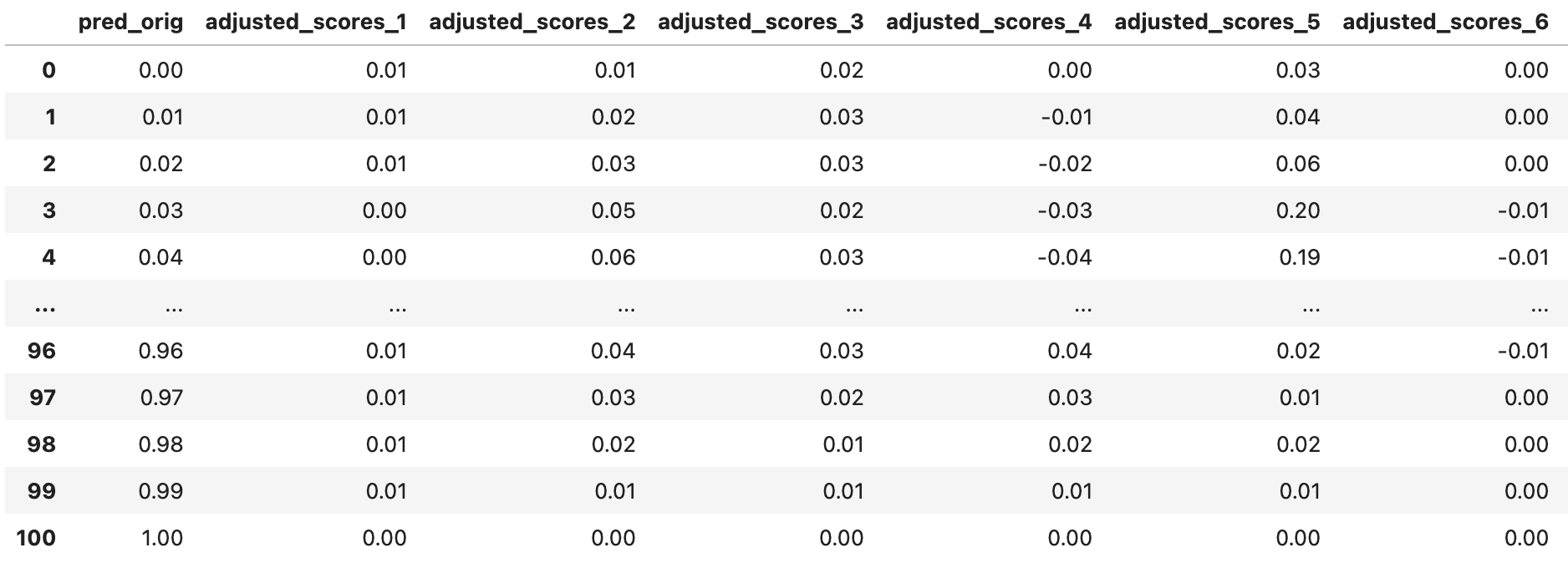
The pred_orig column is a granular representation of possible prediction probabilities a binary classifier could give—in this case, the granularity is set to hundredths. The adjusted_scores_x are the adjustments for group x. If the fairness definition you want to use is demographic parity, we are done! On new inferences, find the prediction probability for that inference and the group that the inference comes from, and then add the adjustment value to the inference probability:
new_prediction_probability = old_prediction_probability + appropriate_adjustmentIf you want to use a different definition, such as equalized odds or equal opportunity, then we need to do one more thing. As we stated before, our goal is to repair the original prediction probability distribution so that it achieves demographic parity. In the paper, we call this a full adjustment, meaning that the adjustment table produced is a full adjustment of our model. For other fairness definitions, such as equal opportunity or equalized odds, we need to find a dampening term that adjusts the adjustments, so that we can achieve those fairness definitions.
In order to do this, we first need to find which group in the sensitive attribute column is experiencing the most disparity according to whatever fairness definition you want to choose. Once we identify that group, we are going to go through an optimization process to find a λ (what we call it in the code and how it is talked about in the paper), which will work as our dampening term, so we can satisfy other fairness definitions. Once we obtain this λ, we can apply it in the following way with our adjustment table:
new_prediction_probability = old_prediction_probability + lambda*appropriate_adjustmentLuckily, this is all automated with our codebase! Here is an example of how to do this:
And, unlike some other bias mitigation approaches, downstream fairness is a pareto optimal algorithm. Meaning that it will achieve these fairness definitions with the minimum amount of accuracy loss.
Of course, there are some limitations. The dataset used to train downstream fairness must contain prediction probabilities for each class for each group, and there should be a good amount of examples for each class for each group. But if that is provided, the algorithm should work as expected.
Conclusion
We went through some of the algorithmic and implementation details of downstream fairness. If you want to explore more of the mathematical details, please go read the paper. Us at Arthur would love for you all to try out our work! Feel free to pip install our package and kick the tires a bit. As you find failure cases or think of new features, feel free to send your feedback to me at daniel.nissani@arthur.ai. Even better, please submit PRs or Issues on our open source GitHub repo. The GitHub repo provides a demo notebook, where you can try out all of our functionality we described in this post.
FAQ
1. What are the specific mathematical principles behind the Downstream Fairness algorithm?
The Downstream Fairness algorithm is grounded in statistical and probability theory, particularly focusing on the concept of distribution repair for ensuring fairness across different groups. The mathematical foundation involves adjusting the distribution of prediction probabilities for each group to align with fairness criteria such as demographic parity, equalized odds, or equal opportunity. This involves a process known as "Geometric Repair," which essentially recalibrates the output probabilities of a predictive model so that the resultant probabilities do not disproportionately favor or disadvantage any particular group based on sensitive attributes. The algorithm employs optimization techniques to find the best possible adjustments that achieve fairness while minimizing accuracy loss. This is achieved by constructing an adjustment table that represents how much the prediction probabilities need to be shifted for each group to meet the desired fairness standard.
2. How does Downstream Fairness compare to other bias mitigation techniques in terms of performance and implementation complexity?
Downstream Fairness differs from other bias mitigation techniques primarily in its post-processing approach, focusing on adjusting model outputs rather than altering the training process or the data. Compared to methods like reweighing, which modifies the weight of instances in the training data, or adversarial debiasing, which involves training a model to predict the target while another model predicts the sensitive attribute to reduce bias, Downstream Fairness is implemented after a model has been trained, thereby not affecting the original training pipeline. This can make it easier to integrate into existing workflows without needing to retrain models. In terms of performance, Downstream Fairness aims to be pareto optimal, meaning it seeks to achieve the best possible trade-off between fairness and model accuracy. This contrasts with some methods that might significantly reduce a model's performance to achieve fairness criteria. However, the actual performance and complexity can vary based on the specific scenario and the extent of bias in the original model.
3. Can Downstream Fairness be applied to non-binary classifiers and multi-class scenarios?
The concept of Downstream Fairness as described in the blog post primarily addresses binary classification problems. However, the underlying principles can be adapted for non-binary or multi-class classification scenarios with some modifications. In multi-class scenarios, fairness typically involves ensuring that the predictive performance is balanced across different groups for all classes, not just two. This could involve extending the adjustment table to cover all possible class predictions and ensuring that the adjustments lead to fair outcomes across all classes and groups. However, this adaptation can increase the complexity, as it requires considering inter-class fairness in addition to intra-group fairness. The implementation for multi-class scenarios would need to calculate separate adjustments for each class and group combination, possibly leading to a more complex optimization problem. While the original Downstream Fairness algorithm may not directly apply, the principles of adjusting prediction probabilities and achieving demographic parity can still be extended to these more complex scenarios with appropriate modifications.