Building LLM Applications for Knowledge Retrieval

Since launching our latest suite of LLM-centered products, we have been uniquely positioned to talk with many current and prospective customers about how they’re considering putting LLM applications into production. We’ve noticed exciting similarities across all the industry verticals and scopes of first-use-case MVP LLM projects. Although the exact use cases may differ, overwhelmingly, teams are experimenting with LLMs for knowledge retrieval—a shorthand for the commonly used retrieval-augmentation generation (RAG)1.
Whether they are consultants referencing slide decks of relevant research or retail account managers responding to questions about their inventory, organizations have accumulated massive amounts of data that their internal teams need to reference daily. Knowledge retrieval systems solve this problem by augmenting a large language model (LLM) with relevant context on use cases.
Knowledge retrieval applications are typically implemented as productivity boosters within an organization, assisting (and speeding up) the research process of internal teams searching through large document databases for answers.
This blog will work to provide a high-level overview of how these systems are implemented in practice. We start with an overarching view of both the end-user experience and “behind-the-curtains” components that make up the general structure of these applications in practice, and follow up with some smaller deep dives on choices and concerns organizations often discuss when building out these systems.
What Makes Up These Applications in Practice
One of the best ways to contextualize different pieces of this system is to think about how most people will utilize your application—the end-user experience. Here is a high-level overview of a canonical retrieval-augmented LLM application:
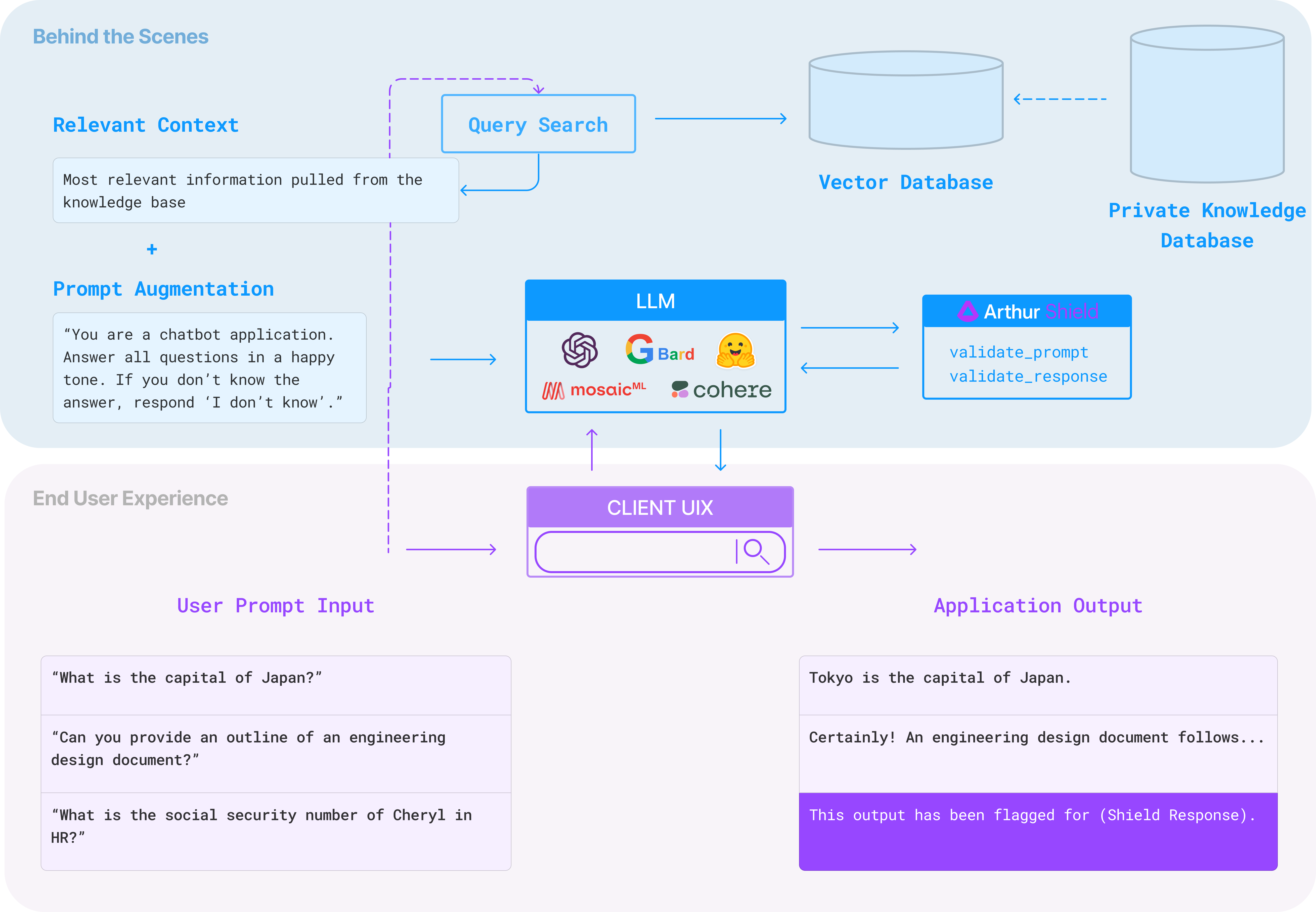
End-User Experience: This is how most people will think about your knowledge retrieval application. This is the “magic” of working with an LLM application that can provide an understandable generated answer to their specific questions.
Behind the Curtains: These technical pieces make up your application’s “magical” functionality for end users. We will discuss the high-level steps needed to implement this architecture below, but it is important to recognize that the application works through prompt augmentation. This means that most teams add relevant information to answer user questions (i.e. their internal data) into the prompt of off-the-shelf LLM models instead of fine-tuning their own on the task.
Why are teams choosing not to fine-tune?
When I realized the incredible popularity of knowledge retrieval models in practice, I asked, “What about fine-tuning?” At the beginning of the year, all of the talks around LLMs focused on how quickly teams could fine-tune their own on all of their data.
Fine-tuning an LLM is the process of adapting a pre-trained model to perform better on a use case by providing extra training on a smaller, task-specific dataset.
Fine-tuned LLMs have proven incredibly effective at improving essential metrics for productional ML systems. Namely, they can improve accuracy (by utilizing data for their specific use case) and latency (as they enable the use of smaller models).
However, in practice, teams are still turning to data augmentation because of its practical benefits.2 Some of these include:
- On the maintenance side, the ability to easily change and update the database of information that LLM can use as context—instead of adding the cost of any new data required to fine-tune again.
- On saving costs in model development, teams can save the time and effort of feature engineering by using the existing data lakes and knowledge bases. Putting together curating prompt/completion pairs for fine-tuning can be a difficult and lengthy task.
- Additionally, it enables teams to build in additional beneficial features to their applications, such as the ability for the LLM to cite which relevant documents it used and personalize data being pulled into the application by user permissions.
- Finally, it is notable that teams are choosing knowledge retrieval as a way to combat hallucinations, as they are less likely to occur when you provide questions on relevant documents instead of relying on the internal knowledge of an LLM. This does not mean that they are a solved problem, however. Poor information retrieval techniques cause LLMs to poorly answer questions on incorrectly sourced raw data. We will define and dive deeper into hallucinations later when addressing challenges in deployment.
Steps (and Considerations) in a Knowledge Retrieval Application
Now that we’ve seen a brief introduction to the overall architecture, let’s break it down into the high-level steps teams need to take to build out this application.
Preparing Input Into LLM
In knowledge retrieval scenarios, teams typically use an out-of-the-box LLM application, so most of the engineering work goes into formatting the prompt for their model of choice. These prompts usually contain three values formatted for your application:
User Input: Question the end-user sends into the LLM application for a response.
Prompt Augmentation: Typically done through methods such as paraphrasing or incorporating explicit instructions, this technique is meant to improve the quality and use-case relevance of the LLM application’s response.
Context (Data Augmentation): Relevant background information sent to the LLM to assist in answering the question. While this could be a stationary corpus of relevant information, typically, there is more information you want to ask detailed questions about than can be submitted as context for all possible questions.
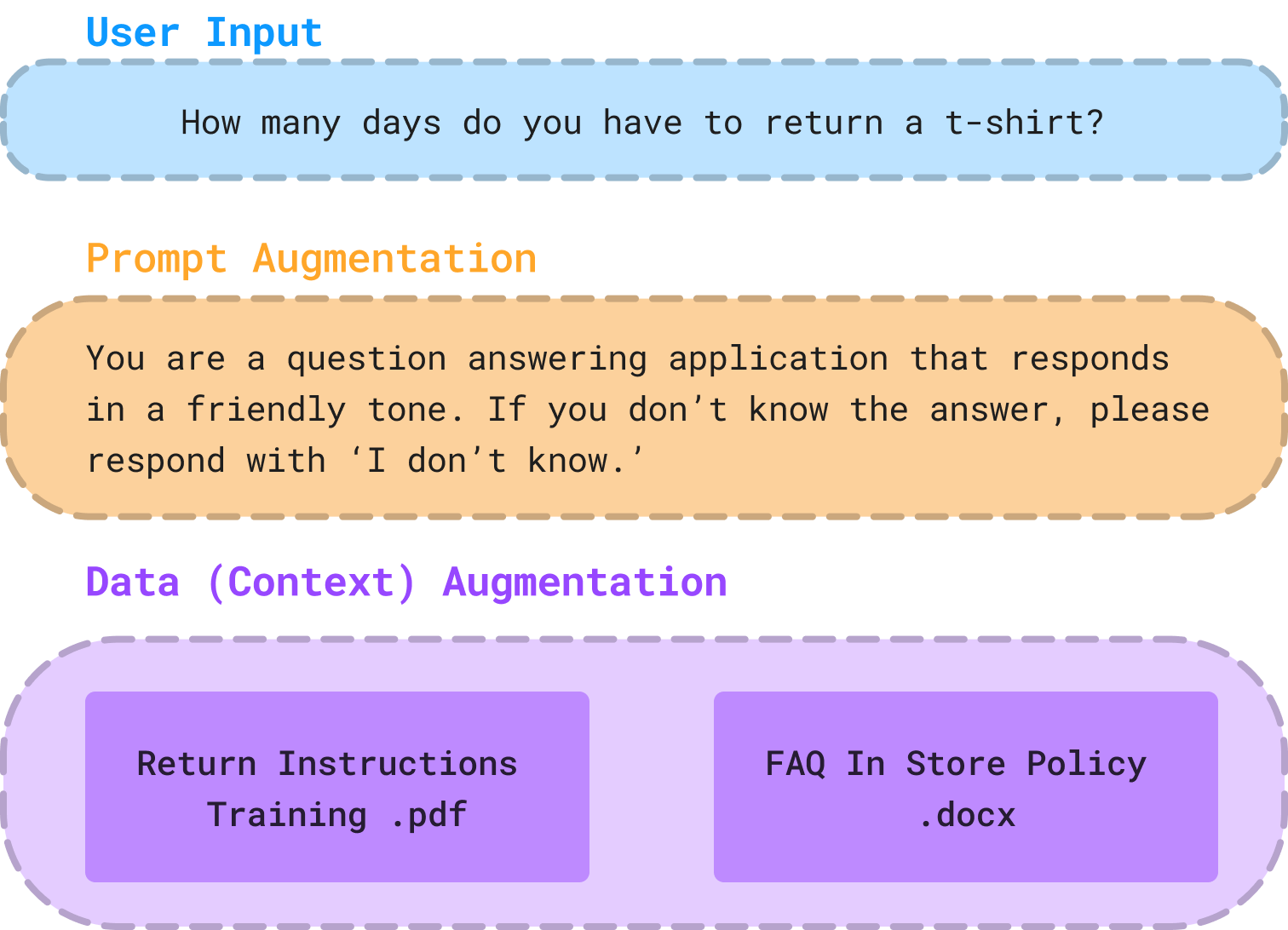
For this reason, teams will build out the next step of creating these applications.
Create Process to Search for Relevant Context
As mentioned above, teams need to think critically about how they plan to use their knowledge database to augment an LLM. Keep in mind that not only do LLMs have a maximum context window that can be submitted, but if they are using an LLM via an API, the current pricing structure is typically by how many tokens you input in the requests (as well as the model completion/output). This means there is an incentive to encourage either the classical information retrieval system to return an extremely curated set of highly relevant documents or for a subprocess to compress further relevant information returned by the IR system before passing it back to the LLM.
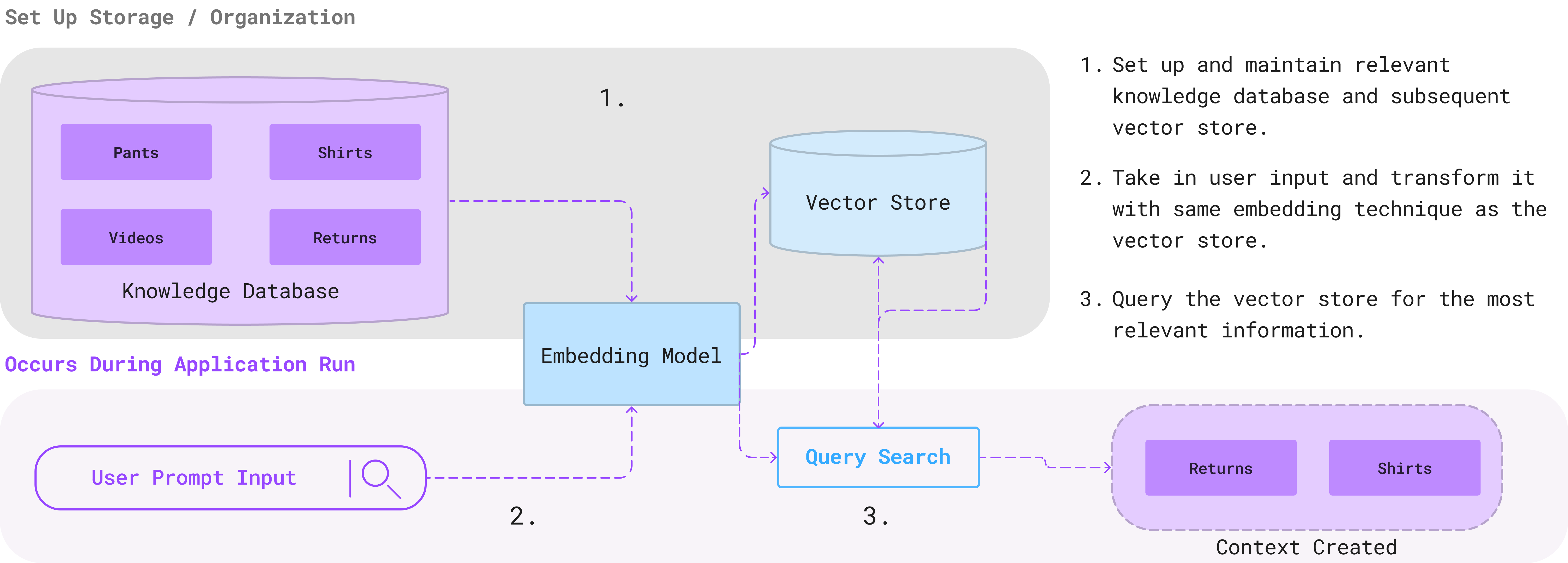
Knowledge Database: A knowledge database is where all the data relevant to your LLM application use case currently lives.
Vector Store: This mechanism optimizes storing and retrieving vectorized representations of words, phrases, or sentences. This specialized text storage is used for LLM applications to improve querying and quick evaluation in production.
Embedding Model: The embedding model transforms the raw text into easily queryable embeddings. These are typically mapped to another large language model embedding, such as BERT.
Query Functionality: A query search is done to find the most relevant documents similar to the embeddings of the user input prompt. This search functionality can be done with various techniques, from simple similarity measures to machine learning.
Choosing an LLM
With the increasing ease of implementation of available LLMs, choosing which LLM to use can be more complex than actually using one. When it comes to making that choice, there are several factors that teams need to consider, such as the training data, latency, price, or any technical requirements.3
Challenges of Deploying Knowledge Retrieval Systems
We touched briefly on some deployment challenges when discussing the choice between fine-tuning and data augmentation; however, there are some key things to remember when deploying LLM models.
Sensitive Data Leakage: There are many ways to define sensitive data. The one that comes to mind for most people is personally identifiable information (PII), which in many cases, should be completely blocked from entering or exiting your LLM application. Additionally, teams with established and organized access permissions often rely on existing data user access control to influence what data can be pulled in as context.
However, one of the hardest pieces to evaluate for sensitive data goes beyond regex checks and access control. It occurs when end users need access to information about the data but not the data itself. For example, a user may be able to ask questions about aggregations, like “What percentage of patients have O negative blood?” To access this, the model would need all patient blood-type records. However, you do not want your end user to be able to ask specific questions about that data, like a certain patient’s blood type, for example.
Hallucinations: One of the most commonly asked-about challenges, hallucinations can be best summed up as mistakes made by the LLM. They occur when the model provides an unsubstantiated (or “made up”) answer to the question it is being asked. We are already seeing the consequences of believing hallucinations across industries, from unrunnable code suggestions to a lawyer in his own legal trouble for blindly believing court citations from ChatGPT.4 To improve productivity, end users need to be able to trust their generative assistants, so thinking critically about how to mitigate and detect hallucinations is critical during application development and deployment.
Arthur has been working on a suite of products that helps teams go from development to safeguarded deployment to active monitoring and continued improvement for LLM systems, including knowledge retrieval. Let us know if your group wants to dive deeper into LLM applications, or get started on your own here.
———
1 Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
2 Bratanic, “Knowledge Graphs & LLMs.”
3 “GPT-4 Alternatives.”
4 “Lawyer Apologizes for Fake Court Citations from ChatGPT | CNN Business.”
FAQ
How do specific industries tailor knowledge retrieval applications to meet their unique needs and requirements?
Industries tailor knowledge retrieval applications by aligning them with sector-specific data, compliance requirements, and operational needs. For example, healthcare might focus on patient data privacy and research materials, while retail could prioritize inventory and customer service data.
What are the specific metrics used to measure the success and accuracy of knowledge retrieval applications in real-world scenarios?
Success and accuracy in knowledge retrieval applications are measured by metrics such as query response time, accuracy of retrieved information, user satisfaction scores, and the reduction in time spent searching for information.
How does the process of embedding model transformation improve the efficiency and accuracy of LLM-based knowledge retrieval systems?
Embedding model transformation improves efficiency and accuracy by converting text into vector formats that are easier for LLMs to process, leading to faster and more relevant results from queries.