
What does it actually take to move AI from experimentation to production?
For most teams, the blocker is no longer model performance. It is AI governance, observability, and the ability to scale agent development with confidence.
As AI systems grow more complex, visibility fragments. Trace data exists but is difficult to operationalize. Experiments produce outputs but not always insight. Governance frameworks sit beside delivery workflows instead of inside them. Over time, this disconnect slows product velocity, increases operational risk, and erodes trust in production AI systems.
Product managers struggle to tie agent behavior to measurable business outcomes. Developers lack tight feedback loops on latency, token usage, and failure modes. Compliance teams need policy enforcement and oversight without creating bottlenecks. The result is a widening gap between AI experimentation and operational deployment.
This month, we focused on reducing that friction and closing the gap.
Rather than shipping a single feature, we strengthened the core infrastructure required for production AI: deeper trace visibility, more flexible analytics, stronger governance foundations, scalable experimentation workflows, and integrated synthetic data generation.
The goal is simple. Make it easier for teams to build, evaluate, deploy, and govern AI agents at scale.
Experimentation Without Fragility
Experimentation is where AI products are won or lost. But many teams still operate with brittle workflows.
Session IDs that are hard to reproduce.
Datasets that are overwritten inconsistently.
JSON outputs that fail silently.
RAG pipelines that are difficult to evaluate end to end.
We wanted to focus heavily on strengthening this layer.
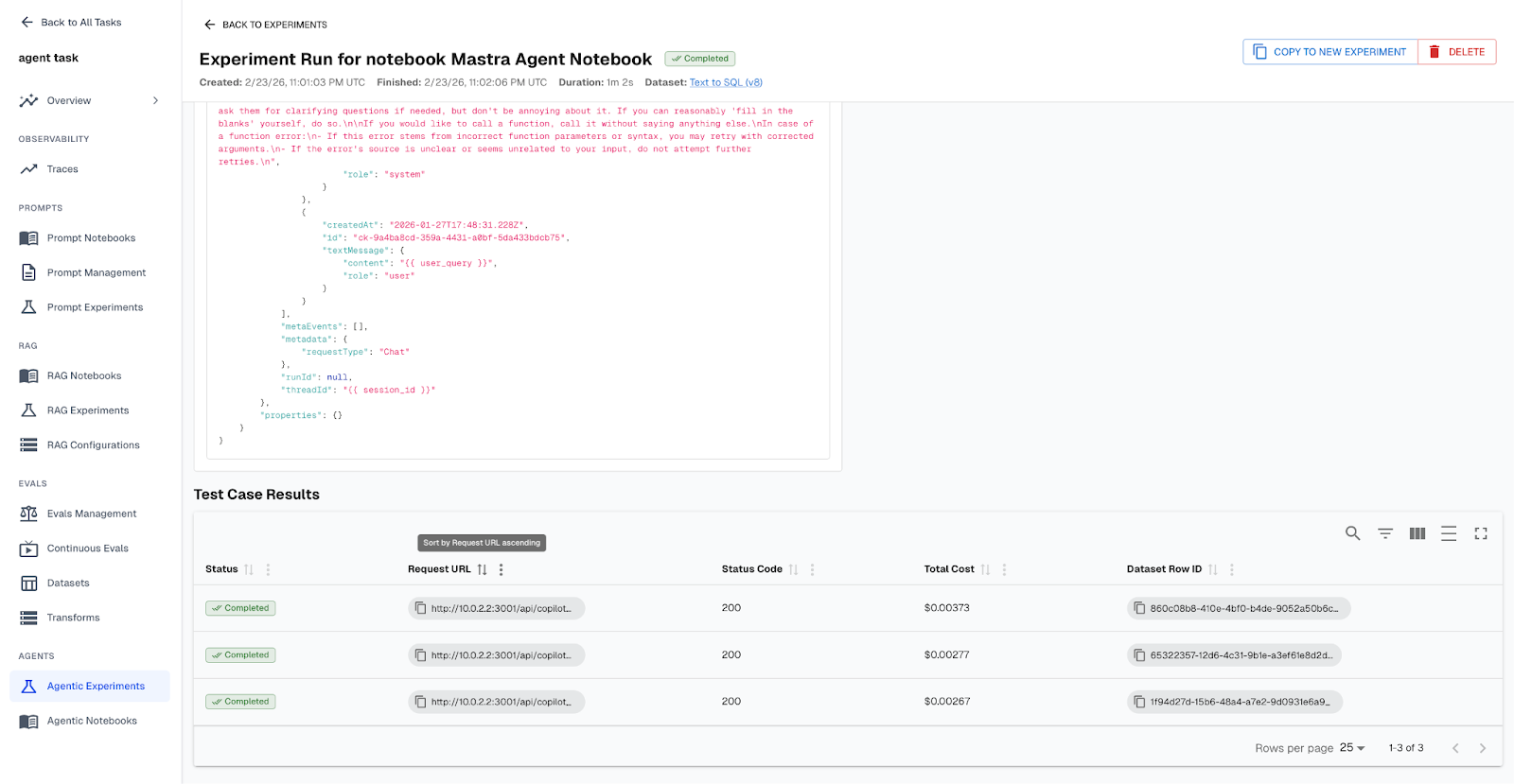
Agent Experiments now support reproducible session IDs, dataset overwrite controls, bulk editing, and stronger JSON validation. RAG notebooks and evaluation workflows are easier to configure, debug, and compare.
This matters because experimentation velocity determines how quickly teams can ship meaningful improvements. When experiments are stable and traceable, PMs can confidently green light changes. Developers can isolate root causes without guesswork. The path from prototype to production becomes shorter and safer.
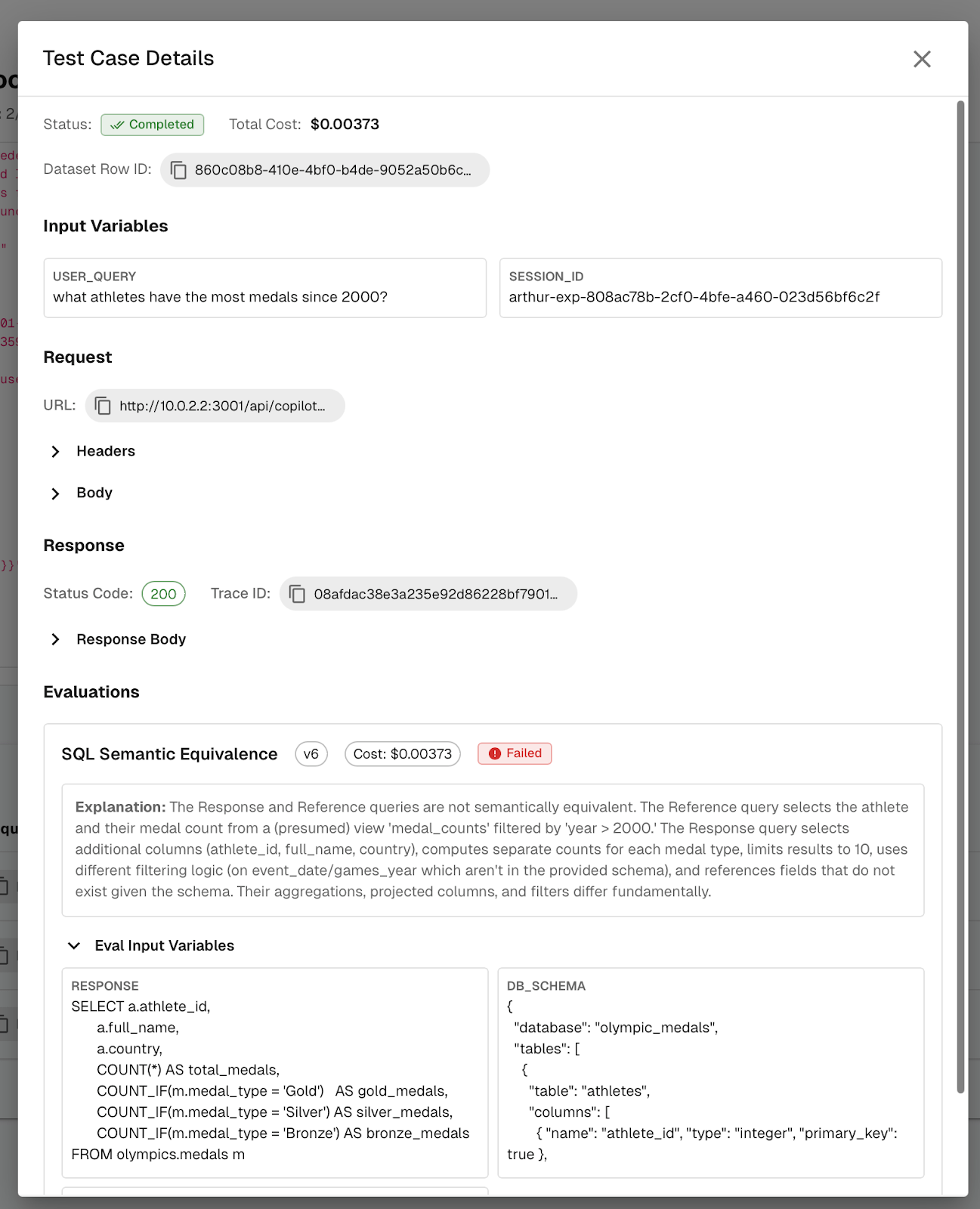
Synthetic Data Generation for Safer, Smarter Agent Iteration
One of the most persistent blockers in AI experimentation is not model quality. It is dataset coverage.
Teams frequently hit a ceiling where their existing dataset no longer exposes new edge cases. The agent performs well on known scenarios, but blind spots remain. Creating new high quality test cases manually is slow. Using production data is manual and toilsome. Relying on static mock data limits realism.
To eliminate that bottleneck, we introduced built-in, LLM powered Synthetic Data Generation directly in the Engine Toolkit.
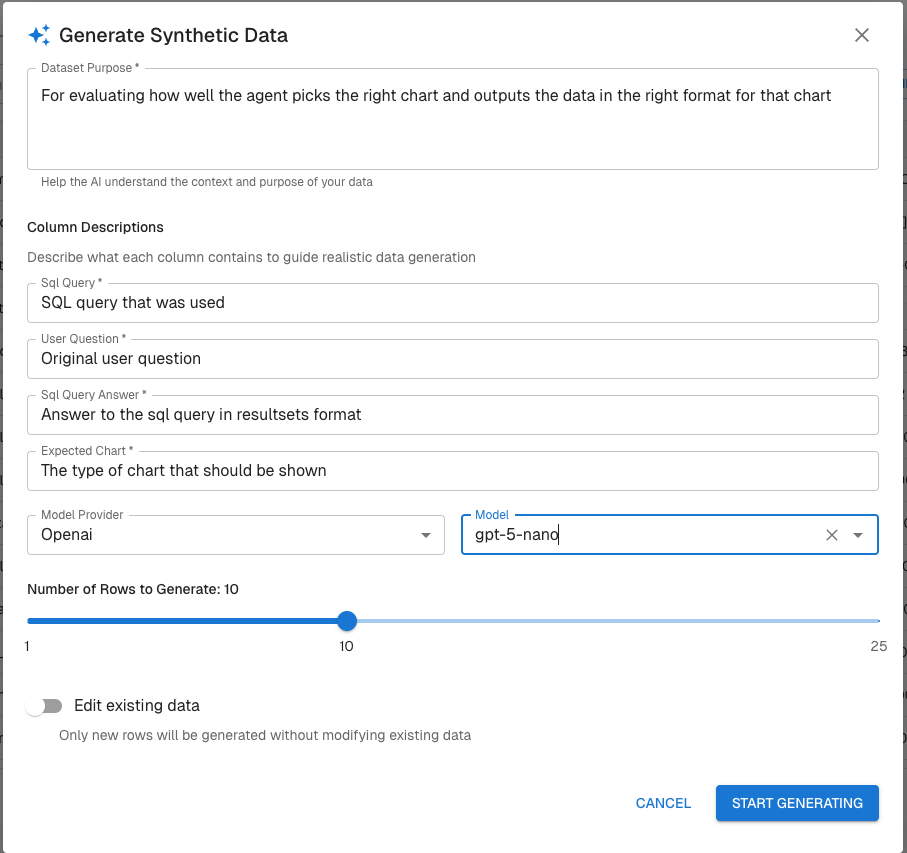
From the Datasets page, you can now click Generate to enrich an existing dataset using a large language model. Rather than replacing your dataset, this feature expands it by generating new synthetic rows, such as additional test cases, edge conditions, or scenario variations aligned to your task.
This allows teams to continuously stress test and improve agent performance without waiting on new production data.
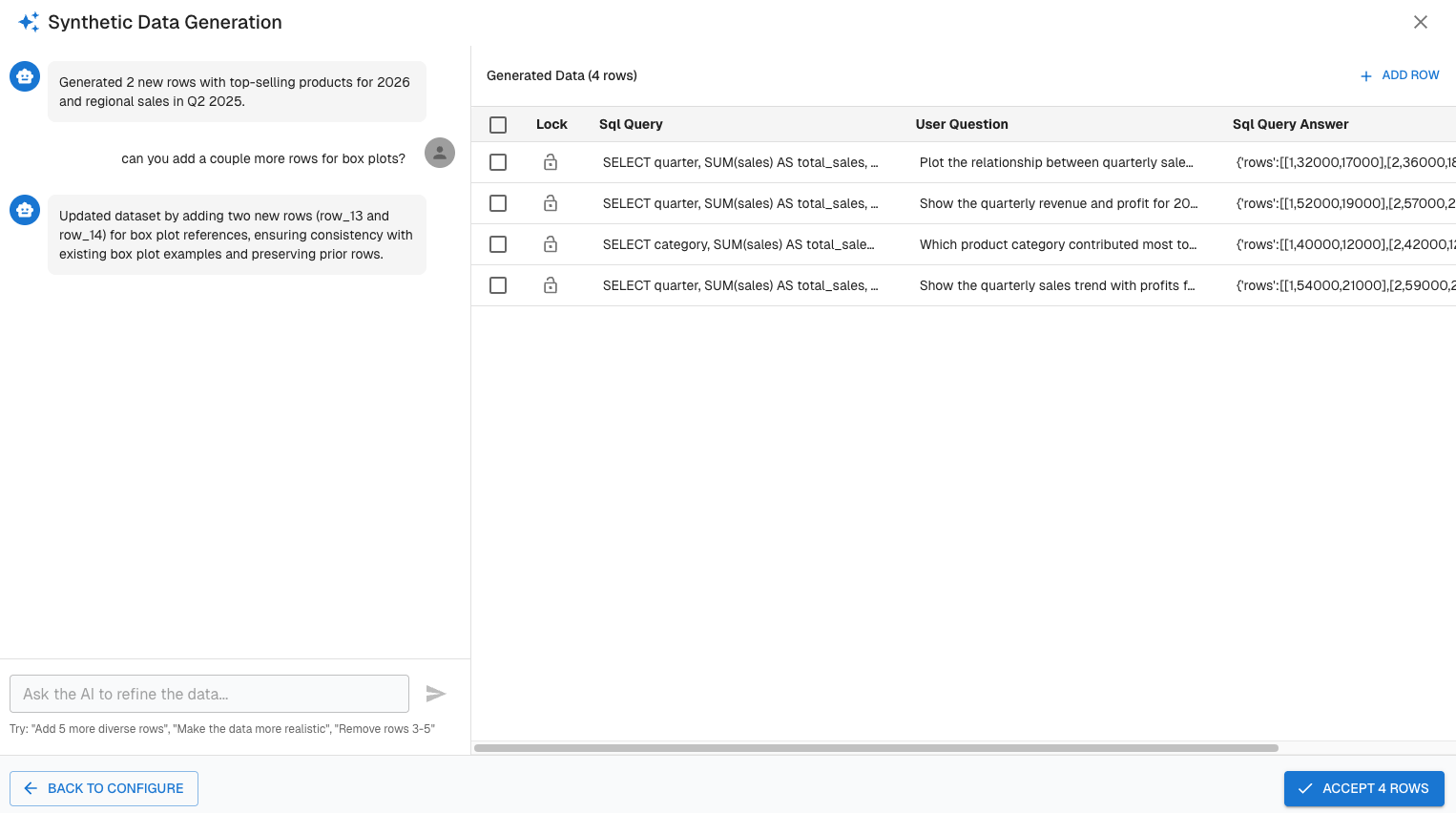
Synthetic data unlocks several critical workflows:
- Creation of new test cases to expose edge conditions
- Expansion of evaluation datasets to improve coverage
- Faster iteration when improving prompts, retrieval logic, or orchestration
- Controlled dataset growth without external data dependencies
Because the enrichment is schema aware and tied to your existing dataset structure, generated data maintains structural consistency. That means it works seamlessly with evaluation mappings, metrics, and governance rules already configured in the platform.
For developers, this means broader coverage and more robust regression testing.
For PMs, it means measurable performance improvements driven by expanded test scenarios.
For governance teams, it means safer experimentation without introducing new sensitive data sources.
As AI systems move from experimental to operational, performance improvements depend on expanding the test surface. Synthetic data generation makes that expansion continuous, controlled, and directly integrated into your workflow.
Analytics That Reflect How Organizations Actually Work
AI performance is not one dimensional.
Compliance teams care about risk signals.
Developers care about latency and output structure.
PMs care about trends and behavioral shifts.
Leadership cares about cost and impact.
Historically, dashboards force all of those personas into the same view.
So building on the theme of visibility, Arthur’s analytics layer evolved to support flexible slicing and dicing of AI performance metrics across models, agents, datasets, and time intervals. The same underlying system can now present different answers to different stakeholders without duplicating infrastructure.
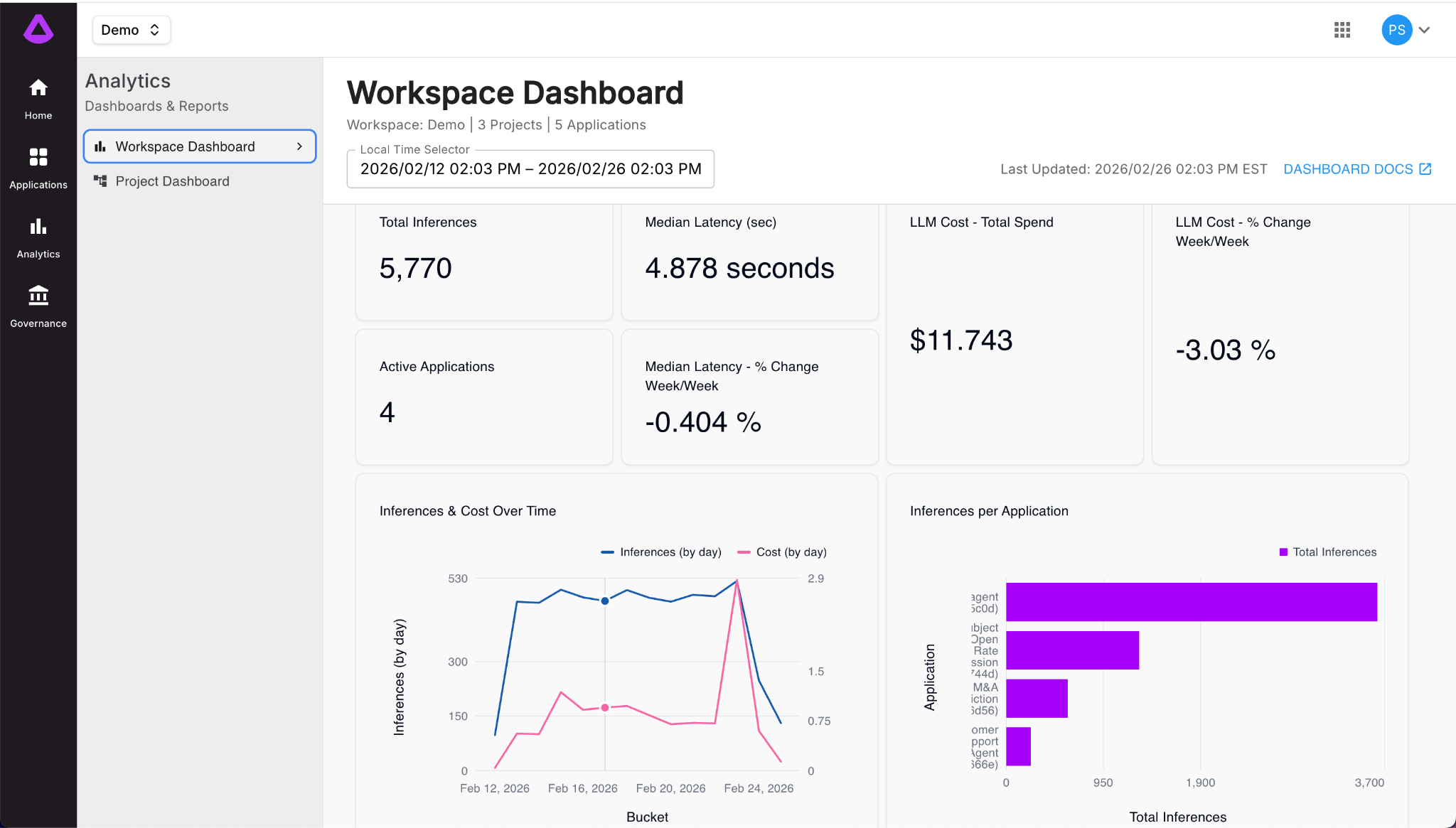
For PMs, this means correlating agent behavior to product outcomes without waiting on a data team.
For compliance, it means visibility without blocking engineering velocity.
For developers, it means isolating regressions faster and with greater confidence.
When performance metrics become adaptable, alignment across teams becomes easier.
When You Cannot See It, You Cannot Trust It
One of the most common patterns we see across product managers and developers is this: something feels off with agent performance in production, but the signal is buried.
A spike in latency.
An unexplained cost jump.
An agent that “mostly works” but occasionally fails in ways that are hard to reproduce.
The data exists. The insight does not.
To solve this, we reshaped how trace visibility works across the Toolkit.
A new trace viewer and enhanced trace table make debugging feel less like archaeology and more like engineering. Status badges and token counts are not cosmetic additions. They reduce cognitive load. They shorten feedback loops. They let developers diagnose behavior without stitching together context from five different views.
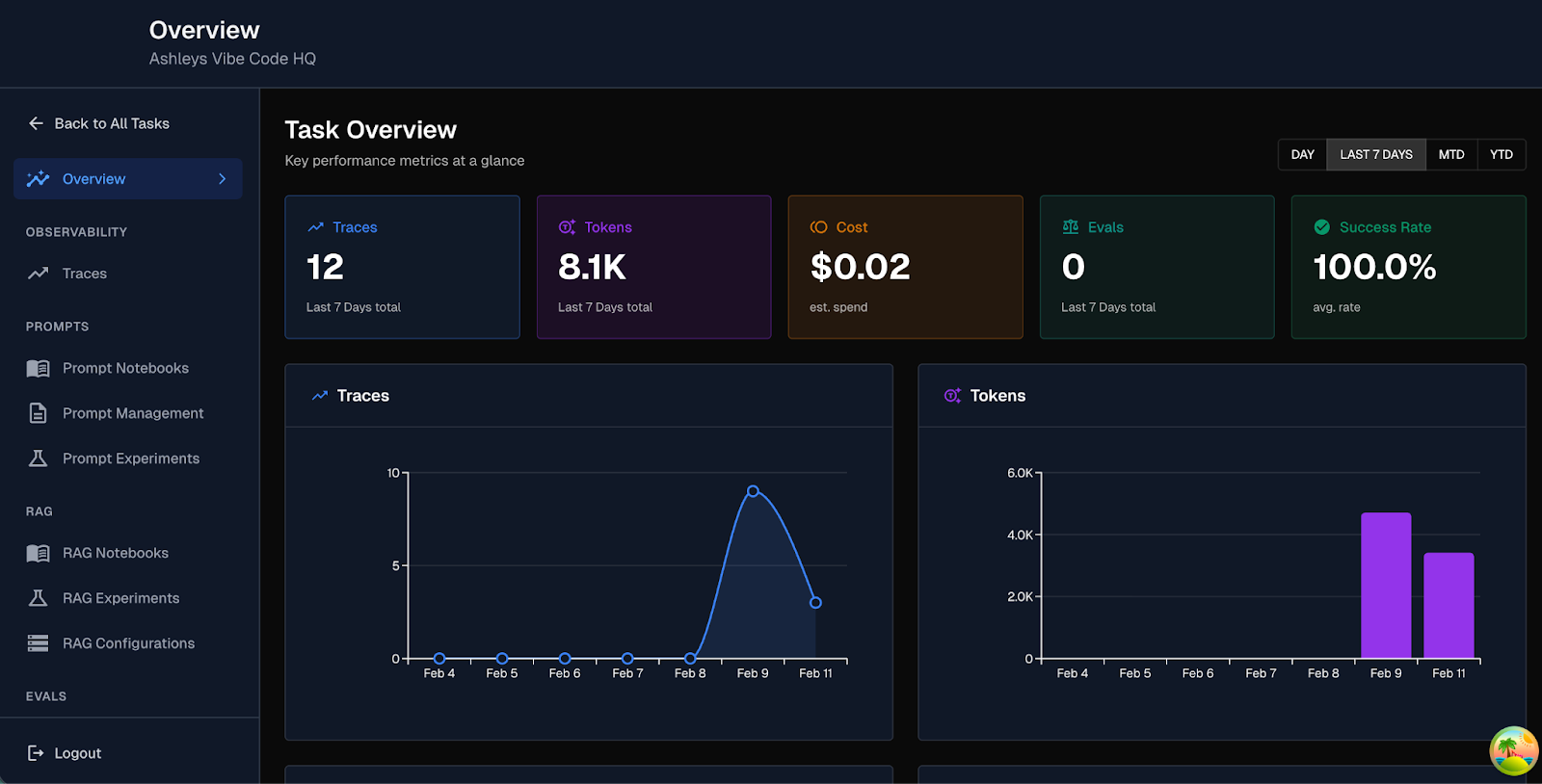
Our new trace overview dashboard brings key KPIs directly to the surface. Instead of digging through rows of raw traces, teams can now see performance signals in aggregate. Token usage. Cost metrics. Span level status. Failure patterns. All contextualized. And easily accessible.
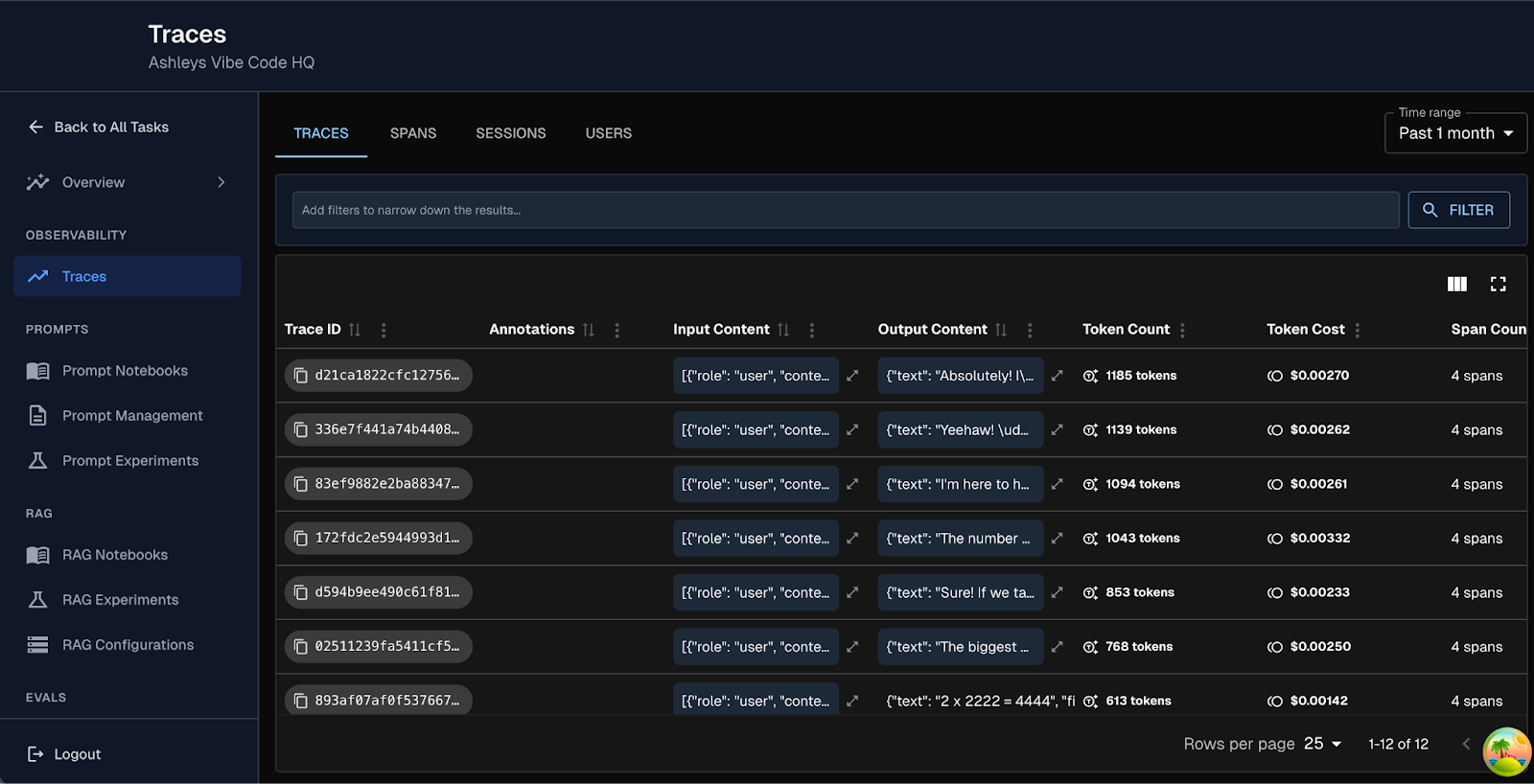
And yes, we shipped it in dark mode too.
In the words of a (real human) developer: “yesssss finalllyyyyy”
Meeting Enterprises Where They Are
We continue to build on our recently introduced Agent Discovery capabilities, structured metadata support, and annotation analytics that strengthen the foundation for scalable oversight.
Arthur expanded support for Vertex AI, AWS Bedrock, and vLLM, alongside improvements in provider handling and model management workflows. GCP model upload with CI/CD integration, OpenShift compatibility, and airgapped model loading all push the platform closer to true enterprise readiness.
Providing enterprise with the tools to support governance as a system, not a checkbox.

Operational AI systems live in cloud environments. Increasingly, teams are deploying agents via GCP Cloud Run and similar services.
Until now, ingesting traces from those environments required more manual coordination.
Which is why we introduced an Agent Polling Mechanism that allows users to continuously poll GCP Cloud Run traces and automatically populate them into the Engine.
This changes the posture from periodic ingestion to continuous visibility.
Instead of waiting for trace uploads or managing custom integrations, teams can:
- Automatically stream trace data into Arthur
- Monitor cloud native deployments in near real time
- Maintain consistent observability across environments
Why? Because governance only works when it is integrated into daily workflows. By embedding discovery and metadata directly into the platform, we are moving governance from reactive to systematic.
From Experimental to Operational
February’s release is more than a collection of improvements. It reflects a broader shift in how AI systems are built and matured inside real organizations.
Arthur is evolving into a platform where AI systems are not only monitored, but truly understood. Not only deployed, but governed with intention. Not only engineered, but shaped collaboratively by the people responsible for outcomes, compliance, user trust, and long term value.
The future of software development will not be defined solely by who can write the deepest infrastructure code. It will be defined by how quickly teams can identify friction, surface insight, and act on it across roles. The platforms that win will be the ones that strengthen the surface layer where daily trust is earned, through clarity, visibility, and continuous refinement.
This month was about tightening that loop.
Helping teams move from reactive debugging to proactive insight.
From fragmented experimentation to reproducible evaluation.
From opaque agents to discoverable, governable systems.
Arthur is not just helping teams ship AI with confidence. It is evolving into a collaborative operating layer for AI, where more people can meaningfully influence how intelligent systems are built, evaluated, deployed, and overseen.
That is how AI moves beyond impressive demos and becomes operational infrastructure teams rely on every day.
See the full platform release notes for February 2026 here.
P.S - If you’re a PM, Developer or Engineer building AI agents or systems and you’ve made it this far, I’d love to learn more about what you’re building. Drop me a line - ashley@arthur.ai.
SHARE




