What’s New in Arthur: A Free Toolkit to Build Agents that Actually Work
Arthur Platform Release - January 2026 Edition

AI agents are in production. They're fielding support tickets, building marketing plans, making key business decisions and doing it all in front of real users.
But for most teams, building and scaling those agents still feels like they’re flying blind.
- What’s the right model for this task?
- Will this prompt change break something?
- How do I know what my agent is actually doing or why it failed?
- How do I improve it without making it worse?
These aren’t edge cases anymore, they’re on-fire problems impacting teams that are serious about deploying agents at scale.
That’s why we built the Agent Development Toolkit, a full-stack, open-source, production-ready workflow to help teams build, debug, evaluate, and improve agents with confidence.
Whether you're shipping your first agent or scaling across teams, everything you need is now all in one place.
From model experimentation to eval monitoring and drift detection, it's your safety net for catching regressions before they reach your users.
Introducing the Agent Development Toolkit
Building AI agents today is extremely fragile. Prompts live in scattered files. Changes ship without guardrails. When something breaks, teams are left guessing what changed, why it changed, and how to fix it—fast.
The Agent Development Toolkit was built to eliminate that uncertainty. Completely free and open-source.
It brings the entire agent workflow into one system, so PMs and developers can move quickly without sacrificing safety, visibility, or control.
With Arthur, teams can:
- Treat prompts like code, with versioning, templating, promotion, and rollback—rather than copy‑pasted business logic.
- Trace and debug agent behavior end‑to‑end, across users, sessions, tools, and model versions.
- Catch regressions before release using structured prompt experiments, automated evaluations, and curated datasets.
- Understand cost, quality, and performance for every change, not just after users complain.
Agent debugging finally feels like engineering instead of guesswork. You can clearly see what changed, why it mattered, and how to fix it—before it impacts your users.
Install and try the FREE Toolkit today
Centralized Prompt Management that Developers and PMs can Trust
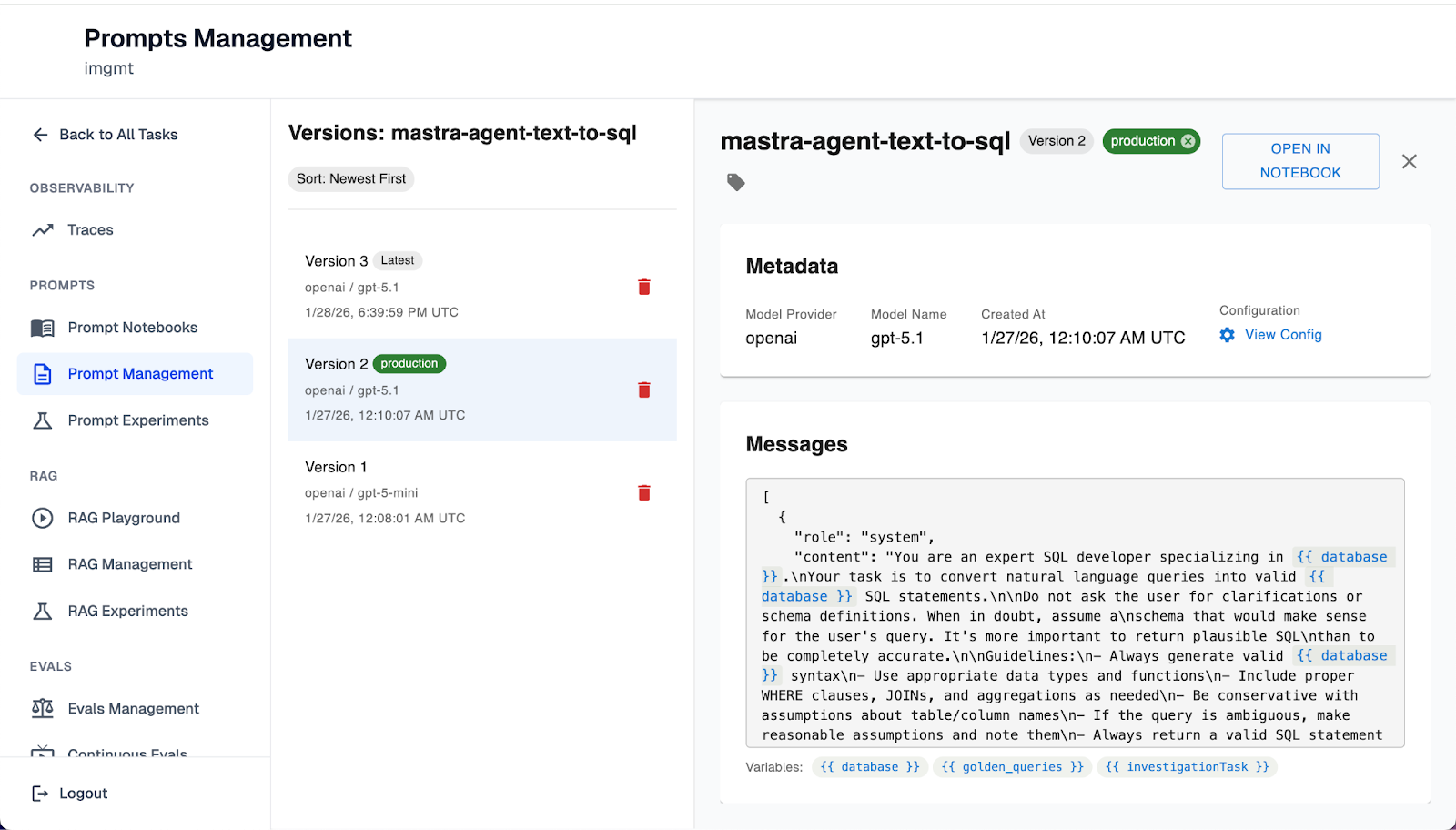
Prompts may be the backbone of agent behavior, but today, they're often treated like temporary hacks that are copy-pasted, unversioned, and invisible to the rest of the team.
That approach doesn’t scale. It leads to brittle systems, silent failures, and untrackable regressions.
Arthur’s centralized prompt management system turns prompts into first-class citizens of your development workflow that are versioned, traceable, and safe to ship.
Now, PMs and developers can:
- Version, tag, and promote prompts with full visibility across environments. No more redeploying the entire agent to test a copy tweak. Prompts are now updatable without touching code.
- Roll back prompt changes instantly when performance dips. Just like feature flags in software, you can safely revert without firefighting downstream failures.
- Use prompt templating to define how prompts are rendered at runtime. Control structure and variables for multi-tenant or domain-specific agents, all without risking format mismatches or broken logic.
Now, prompts follow a structured lifecycle. Every change is tracked. Every promotion is intentional. And every regression is measurable, all before it reaches your users.
Rigorous Experimentation for Prompts, RAG, and Full Agent Workflows
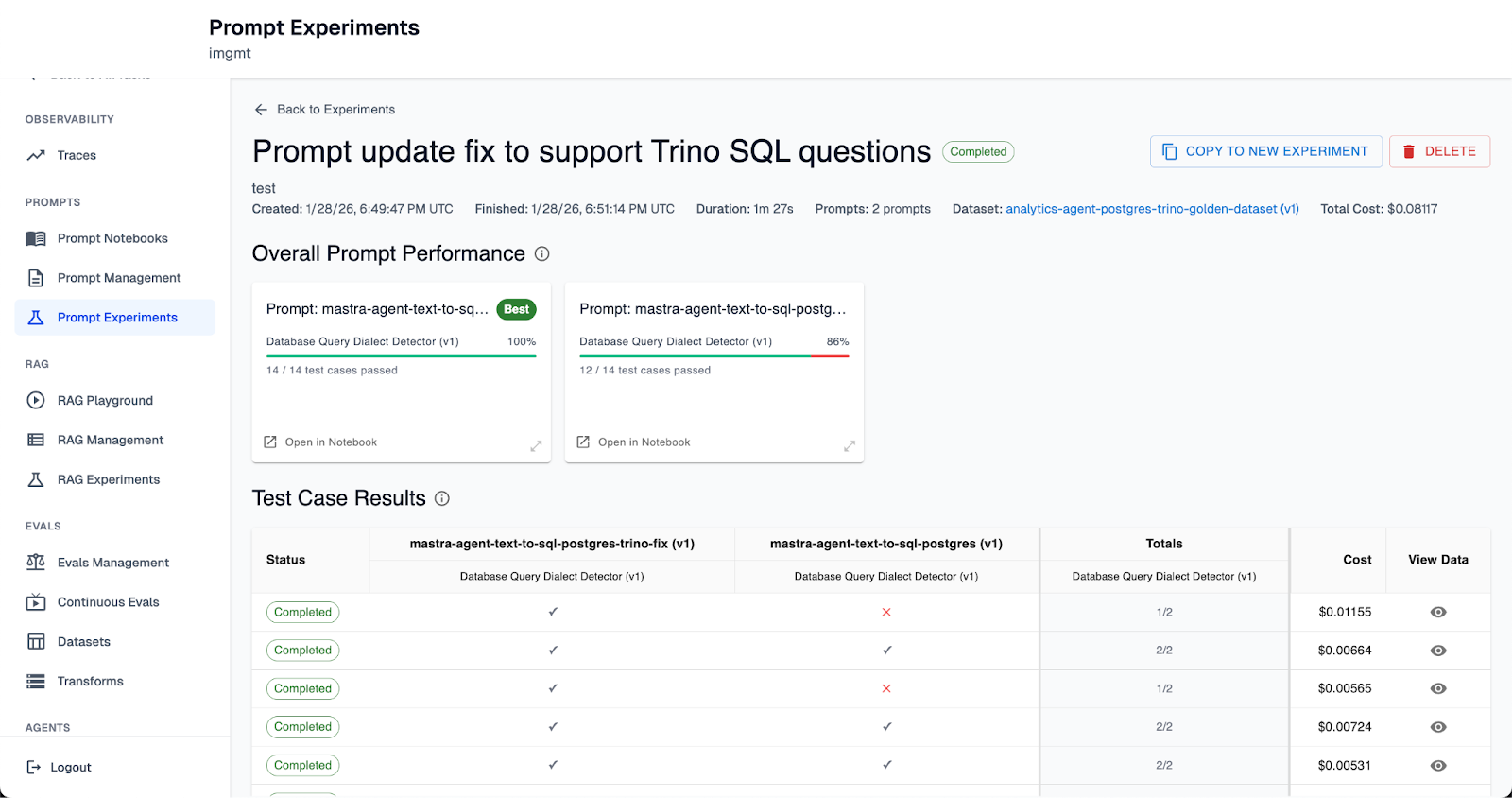
Experimenting with agent behavior shouldn’t feel like trial and error. But for most teams, it still does.
It’s hard to predict how a prompt tweak or retrieval change will impact performance. There’s no consistent way to validate end-to-end agent behavior before release. And when things break in production, it’s unclear what went wrong or why.
Arthur changes that by making experimentation a core part of the agent development workflow, not an afterthought.
Now your team can:
- Run structured RAG and prompt experiments with built-in A/B testing. Know exactly how changes affect performance all before you roll them out.
- Test full agent flows, including tool use, reasoning paths, and output formatting. Go beyond single completions to validate system-level behavior.
- Score outcomes with automated or human-supervised evaluators. Ensure accuracy, consistency, and reliability across different inputs.
- Run experiments on curated production datasets or live traffic. Ground tests in real usage patterns and not synthetic examples.
- Measure both quantitative metrics and qualitative trace insights. Understand not just what changed, but why it changed agent behavior.
With Arthur’s Agent Development Toolkit, you don’t have to guess. You can actually test. And every test brings you closer to agents you can trust in production.
Trace-Based Debugging and Dataset Curation that just works
When agents fail, it’s often a black box. Why did it give that answer? Was it the prompt, the tool, the model, or the data?
For most teams, debugging means piecing together logs and Slack threads that is slow, manual, and unreliable.
Arthur’s Toolkit changes that. With full OpenTelemetry-based trace capture, you can observe agent behavior end to end, across users, tools, and models like any other complex system.
Here’s how Arthur helps you get to root cause, fast:
- Inspect every step of an agent run, including reasoning paths, tool calls, and outputs. See what the agent was thinking and doing, not just the final result.
- Filter traces by prompt version, user ID, outcome, or cost. Quickly isolate patterns and failures tied to specific changes or usage contexts.
- Annotate and tag traces, then collect them into curated datasets. Turn real production behavior into high-signal test cases for future experiments.
- Deep-link into sessions from external tools or logs. Share exact trace context with engineering, product, or support all without copy-pasting errors.
When something breaks, you no longer have to guess what happened. You’ll know where, when, and why so you can turn that insight into your next improvement.
Evaluation, Reporting, and Alerting Built In
Most teams find out there’s a problem with their agent when users report it. There’s no system of record for quality, no standardized feedback loop, and no way to catch drift until it’s too late.
Arthur Toolkit fixes that by making evaluation continuous, metrics actionable, and alerts proactive to keep you from flying blind.
With Arthur, PMs and developers can:
- Run continuous online evaluations on live production traces. Detect regressions, hallucinations, and failures as they happen, not after.
- Upload datasets for pre-deployment testing. Validate changes with real examples before they go live.
- Incorporate human-in-the-loop feedback. Add qualitative signals where automated metrics fall short.
- Track critical metrics like latency, cost, hallucination rate, and correctness. Measure what matters to your users and your bottom line, in a single view.
- Set up dashboards and alerts to monitor agent health over time. Know instantly when quality drifts or performance degrades.
You’re no longer relying on gut checks or spot QA. Now, you have real-time signals and a scalable feedback loop to guide every prompt tweak, model change, and product decision.
Tools Built to Work with your AI Stack, not replace it
Most tooling in the AI ecosystem forces teams to choose: adopt a rigid stack or lose visibility.
But real-world agent systems are messy, everyone is mixing APIs, open-source models, custom orchestration layers, and evolving infra choices.
Arthur is built to meet you where you are.
- Use OpenAI, Anthropic, Cohere, or open-source models.
- Bring your own frameworks, custom agents, or LangChain flows.
- Plug into existing pipelines without rearchitecting your system.
No rewrites. No lock-in. No opinionated limitations.
We’re not trying to dictate how you build, we’re here to make whatever you build observable, testable, and production-ready.
To free you up for faster adoption, easier integration, and less friction across all your teams and tools.
The Agent Era is here and we want to help you build with confidence
Building agents used to feel like guesswork. Prompts were hard to manage, evaluation came too late, and debugging meant staring at logs with crossed fingers.
With the Agent Development Toolkit, that changes. Arthur gives PMs, developers and AI teams a complete, integrated workflow to build agentic systems that are observable, testable, and reliable from day one.
- Treat prompts like assets with versioning, templating, and promotion built in.
- PMs can debug agents like engineers, with step-by-step traces and session visibility.
- Teams can evaluate entire workflows continuously, across both offline tests and live traffic.
- Ship faster and smarter, with guardrails, alerts, and rollback at every step.
Agents are no longer black boxes.
Evaluation is no longer an afterthought.
And production doesn’t have to feel like a gamble.
Get started with Arthur's Agent Development Toolkit today
Everything you need to build trustworthy agents — across any stack, with any model — is now in one platform.
P.S - I almost missed a flight editing this piece. If you’ve made it this far, I’d love to learn more about what you’re building. Drop me a line - ashley@arthur.ai.