
Every team building production agents fights the same battle on three fronts: token spend, model performance, and speed. You want responses that are accurate, fast, and cheap. In practice these usually feel like a pick-two problem. Lower cost and you risk quality. Chase quality with a bigger model and you pay for it in latency and dollars.
Task-specific small language models offer a way out of that tradeoff. The catch is that swapping a model into a production agent is a change you have to be able to defend, and most teams can't defend it with confidence. This post is about how ScaleDown and Arthur address both halves of that problem together: more accurate, leaner, and faster models from ScaleDown, and the evals and observability from Arthur that prove the change actually made your agent better.
Task-Specific Small Models Fix All Three
ScaleDown builds small, purpose-built language models for the workhorse steps inside an agent: compression, summarization, extraction, and classification. These are the high-volume, repetitive operations that quietly drive most of an agent's cost and latency. They rarely need a frontier model, but they almost always get one by default.
This is a different way of thinking about model selection. Instead of routing every step through one large general-purpose LLM, you use a specialized small model for the task in front of you. AI engineers already understand the principle: regardless of which model you pick, you have to evaluate it. Task-specific SLMs simply give you more, and better, options for each step.
The payoff shows up across all three of the pains above. ScaleDown's golden metrics are comparable or better accuracy, 10 to 15x cheaper, and 2 to 20x faster than the large models teams typically reach for. That is the rare change that improves cost, speed, and quality at the same time, rather than trading one for another.
The Real Blocker: Justifying the Switch
If SLMs are this good, why isn't every team already using them? Because a model swap is only as good as your ability to prove it works.
There's a deeper benefit to evals here than catching bugs. Without evals, switching models is risky and slow, because you can't trust that a new model will perform. A comprehensive eval suite works like a unit-test harness for model changes: when you swap something in, you can see that your evals still pass and that performance has improved. That confidence is what shortens the path from interest to decision.
Without that harness, a model change is a leap of faith. You might save money and speed up responses, but you have no objective signal that quality holds up, and no way to catch a regression before your users do. So the change either stalls or never happens.
Arthur Quantifies the Improvement
This is where Arthur comes in. Arthur is the agent evaluation platform that measures whether a change, including a ScaleDown model swap, actually makes your agent better, and keeps it reliable once it's live.
Instead of guessing, you get an objective before-and-after picture on the metrics that matter: accuracy, cost, and speed. A few things make that measurement trustworthy:
- Compare across many models, not just one-versus-one. Rather than testing only your current model against ScaleDown, you can evaluate across several options at once, for example Gemini, Haiku, and Nano alongside ScaleDown, so you see the full landscape and pick the best fit for each task.
- Evaluate real production workflows, not demo environments. The point isn't a polished one-off comparison. It's understanding how a model behaves on the actual work your agent does in production.
- Binary, specific evals anchored to real requirements. Following Arthur's best practices for building agents, each eval targets a concrete failure mode with a clear pass/fail decision, so a result means something instead of leaving a human to interpret a fuzzy score.
Get Started Fast With Dataset Generation
One of Arthur's features makes the first step easier: synthetic dataset generation. From a single sample, Arthur can generate a full, representative dataset to evaluate against, so you don't need a large hand-built test set before you can measure anything. As your agent runs, that dataset can grow over time using real production traces, so your evals keep reflecting how your agent behaves in the real world.
Better Together: What ScaleDown and Arthur Unlock as a Pair
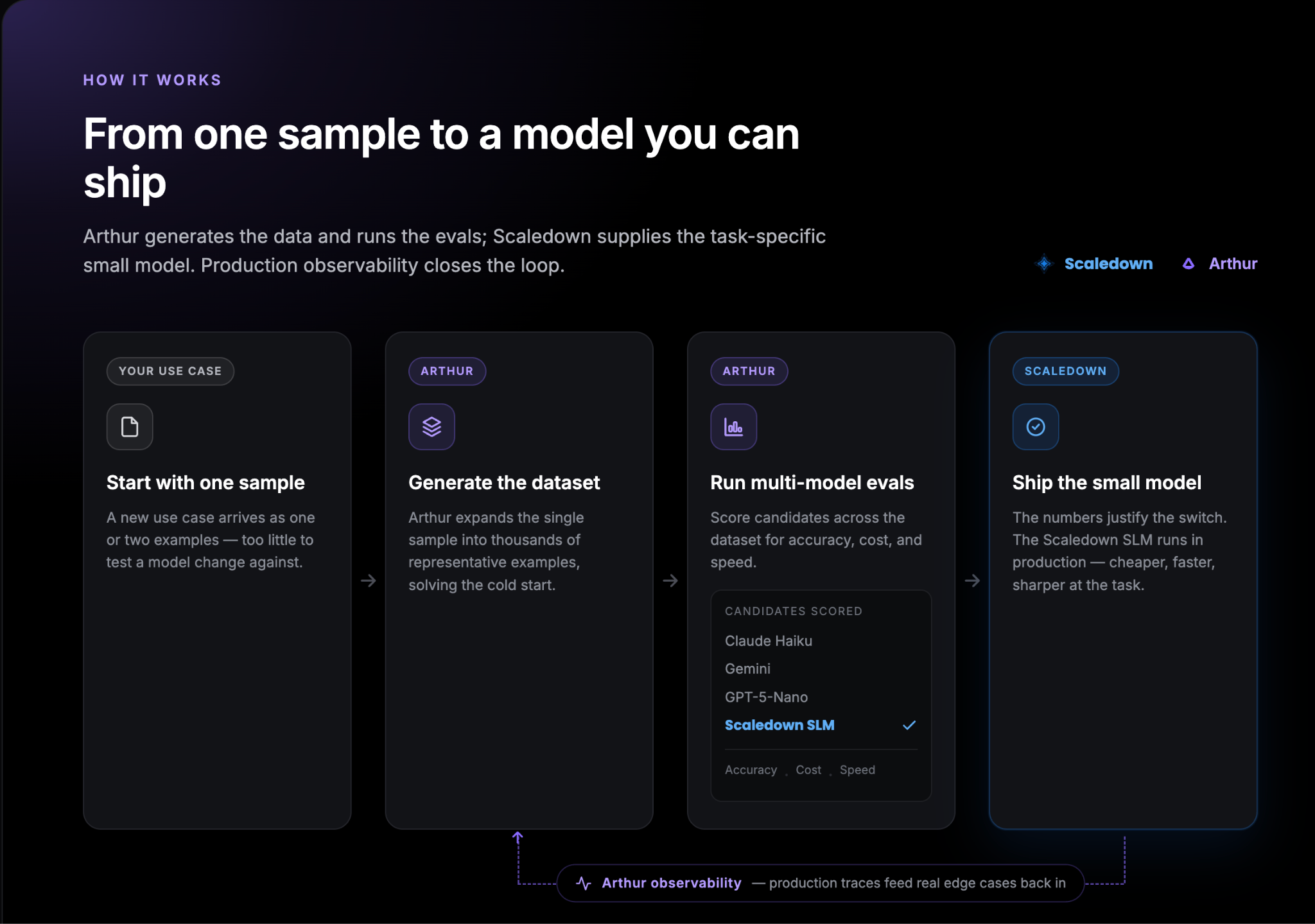
ScaleDown makes your agent leaner and faster. Arthur makes the improvement measurable and trustworthy. Together they close the loop between shipping an efficient model and proving it works.
The combined workflow is simple: adopt a task-specific small model with ScaleDown, then use Arthur's evals and observability to confirm the swap improved cost, speed, and accuracy, and to keep monitoring it in production. You move from "this model is probably cheaper" to "this model is cheaper, faster, and holds quality, and here's the evidence."
Any team adopting specialized models runs into the same need to justify the change. This pairing closes that gap. Lean teams get to move fast and swap models with confidence instead of guesswork, which is exactly what it takes to ship reliable agents that production environments can trust.
Get Started
Explore ScaleDown's task-specific small language models at scaledown.ai and learn about Arthur's startup partner program.
SHARE



