Arthur vs Braintrust: A Detailed Feature Comparison for Production AI Agents

If you are building AI agents headed for production, you have probably evaluated at least one observability or eval platform. Two names that come up often are Arthur and Braintrust. Both help teams ship more reliable LLM applications, but they take meaningfully different approaches to the problem.
Braintrust is a focused LLM engineering platform built around observability, prompt management, and evaluation. Arthur is a full agent development lifecycle (ADLC) toolkit that adds opinionated continuous evals, multi-level experiments, runtime guardrails, and enterprise governance on top of the same foundation.
This post walks through a side-by-side comparison across the best practices we consider fundamental to building production-ready AI agents: observability, prompt management, continuous evaluations, experiments, guardrails, and governance, and deployment architecture.
| Arthur | Braintrust | |
|---|---|---|
| Best for | Production agents needing integrated evals, guardrails, and governance | Teams wanting a focused observability and evaluation platform |
| Tracing | OpenInference-native with first-class retriever, agent, and chain spans | OTel-native via the OpenTelemetry GenAI semantic conventions and OpenLLMetry standards |
| Prompt templating | Versioning, environment tagging, Jinja2 conditional logic | Versioning, environment tagging (Pro/Enterprise only), mustache variables |
| Continuous evals | Opinionated binary pass/fail with explanations and built-in eval templates | Flexible LLM-as-a-judge scorers; numeric, boolean, or categorical |
| Experiment levels | Explicit prompt, RAG, and end-to-end agent experiments | Single unified experiment abstraction; user-defined task function |
| Runtime guardrails | Native pre- and post-LLM guardrails with self-correction loop | No native guardrails; supports third-party guardrail integrations instead |
| Governance | Built-in agent inventory, ownership, and governance tools | No agent governance tools |
| Architecture | Federated with separate data plane and control plane | Federated with separate data plane and control plane |
Both platforms can help your team ship more reliable LLM applications. The right choice depends on how much of the agent lifecycle you want covered out of the box, and how strict your compliance posture is.
Platform Overview at a Glance
Arthur ships the Agent Development Toolkit, anchored by Arthur Engine. It covers the full ADLC: tracing, prompt management, supervised and unsupervised evaluations, multi-level experiments, real-time guardrails, and governance. Arthur Engine is open source and can be self-hosted or run as a managed service, with the data plane deployed inside your VPC.
Braintrust is an open-source LLM engineering platform focused on observability, prompt management, and evaluation. It is built around an experiments-and-scorers model, integrates with most major LLM frameworks, and offers a hybrid self-hosting option where the data plane runs in your cloud and the control plane is operated by Braintrust as SaaS.
Observability and Tracing
Both platforms support OpenTelemetry ingestion, sessions, user tracking, environment separation, and cost tracking. The difference is in the underlying data model and how much LLM-specific detail you get without extra work.
Braintrust implements the OpenTelemetry GenAI semantic conventions, so traces sent with gen_ai.* attributes are automatically mapped to its internal fields (input, output, metrics, metadata). It integrates with OpenLLMetry, and any OTLP exporter via the BraintrustSpanProcessor, @braintrust/otel, or BraintrustExporter. Internally, spans are typed as llm, task, tool, function, score, or eval. There is no first-class retriever or agent span type, so retrieval logic and agent loops are captured under generic function or tool spans.
Arthur is built natively on the OpenInference semantic conventions, which were designed specifically for LLM workloads. In practice that means:
- Richer LLM call detail (prompts, completions, tokens, cost, model parameters) captured by default
- First-class retrieval and re-ranking spans, important for RAG-heavy agents
- Explicit span types for LLM, TOOL, AGENT, CHAIN, RETRIEVER, with message, document, and tool-call sub-types
Both platforms support out-of-the-box auto-instrumentation for LangChain, LlamaIndex, OpenAI, Google ADK, Mastra, AWS Strands, CrewAI, and many other popular frameworks
If you compare traces from the same agent side by side, OpenInference produces more expressive, debuggable traces today. That depth also feeds downstream into evals, experiments, and governance views without extra plumbing. Every retrieval call, tool invocation, and agent decision is already structured in a way the rest of the platform understands.
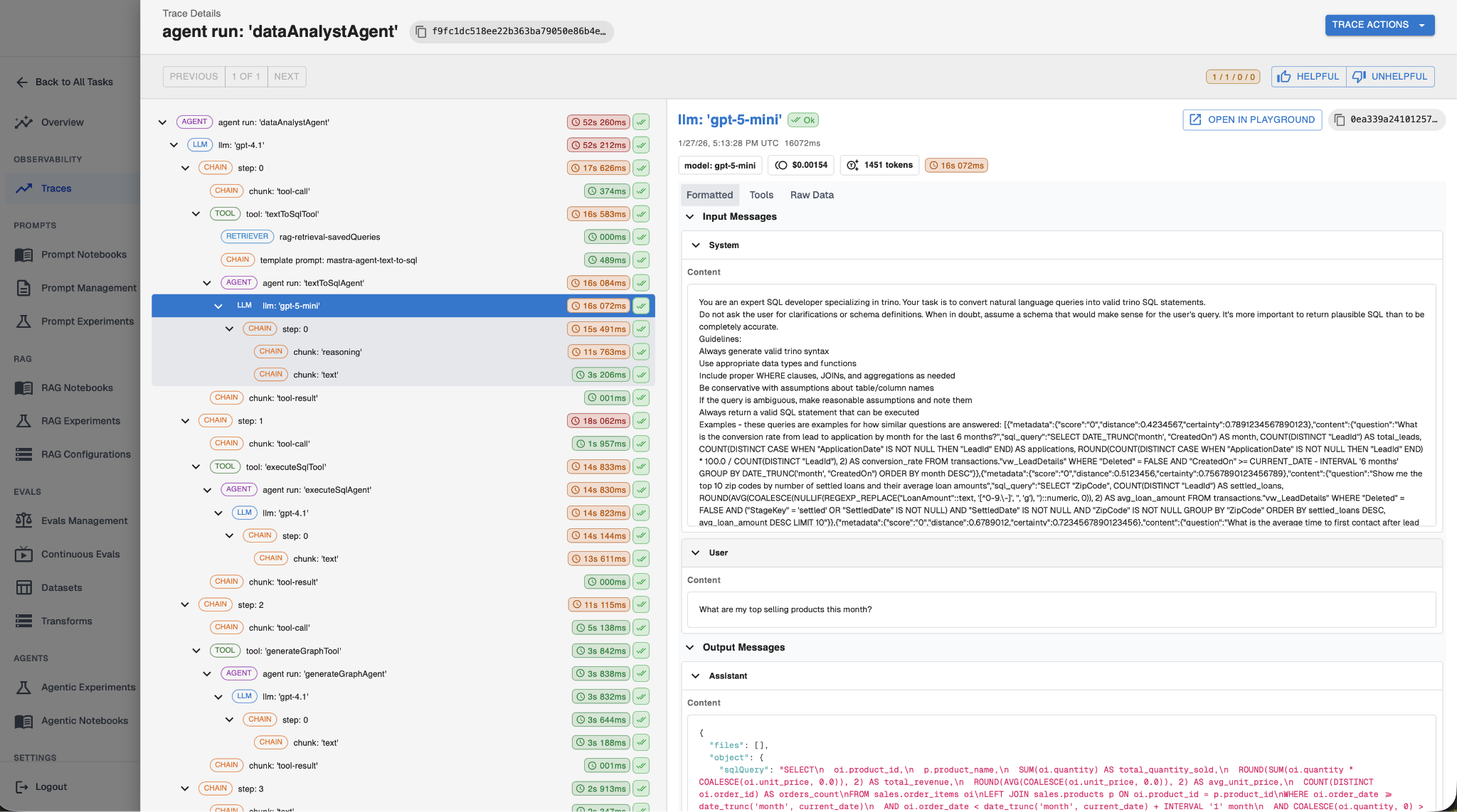
Prompt Management
Both platforms agree on the fundamentals: prompts belong outside your application code, every prompt needs versioning and rollback, and non-engineering teammates should be able to iterate without a redeploy.
Braintrust offers a clean labels-based deployment model (production, latest, custom labels), prompt composability so you can reference one prompt inside another, an interactive playground, and client-side caching so prompt fetches add no latency. Templating uses mustache-style {{var}} placeholders. Environment support (dev, staging, prod) is gated to Pro and Enterprise plans.
Arthur covers the same ground with versioning, environment tagging (dev, staging, prod), and a prompt library that lives outside the codebase. The differentiator is templating with conditional logic. Arthur prompts support Jinja2 syntax, so you can branch on request context instead of stuffing every possible instruction into one monolithic prompt:
{% if tier == 'enterprise' %}
run enterprise prompt instruction
{% else %}
run the free tier instruction
{% endif %}Both platforms can handle conditional templating. The practical difference is that Arthur supports conditionals out of the box, while Braintrust requires additional configuration to enable them.
Why this matters in practice: without conditional templating, you either maintain a separate hardcoded prompt for every variant or pile every instruction into one massive prompt. The first explodes in maintenance cost. The second bloats context, increases latency and spend, and often degrades model accuracy as token counts grow.
A real Arthur customer building a SQL-generating agent uses this pattern to support dozens of database dialects, dynamically including only the dialect-specific instructions relevant to each request. The result is smaller prompts, more precise outputs, and lower per-request cost than a monolithic prompt would produce.
Continuous Evaluations
This is where the two platforms diverge in philosophy.
Braintrust provides online scoring rules that run LLM-as-a-judge scorers asynchronously on production traces. Scoring is flexible: numeric (0 to 1), boolean, or categorical via choice scores. A __pass_threshold setting lets teams treat scores as binary pass/fail, but the underlying scorer still emits a continuous value. You write each judge prompt yourself, or use presets from the autoevals library like Factuality, NumericDiff, ClosedQA, Battle, and Summary.
Arthur takes an opinionated stance: continuous evals should be unsupervised (no ground truth required), binary pass/fail (no ranges or scores), and specific (each eval targets one concrete failure mode). Arthur provides ready-to-use templates for common evals that include answer groundedness, answer completeness, topic adherence, and goal accuracy. Every eval returns both a pass/fail decision and a natural-language explanation, which makes identifying a failure mode much faster.
Two patterns Arthur supports out of the box:
- Alerting on failure: When evals are high-confidence, failures fire alerts so the team can investigate before more users are affected.
- Human review filtering: For earlier-stage agents, failures queue interactions for human review so the team can analyze clusters and prioritize improvements.
The practical difference: range-based scoring pushes the judgment burden onto a human who has to decide what threshold matters, and LLMs compound this by being inconsistent scorers — the same interaction might return a 4 on one run and a 6 on another. Binary scoring with an explanation removes that ambiguity. When an Arthur eval fires, it means something requires attention, and the explanation tells you what.
Experiments and Supervised Evaluations
Braintrust has a single unified experiment abstraction. You define a dataset, write a task function, attach scorers, and run. Whether you are testing a prompt, a retrieval configuration, or a full agent, you use the same Eval abstraction with a different task function.
Arthur takes the same idea and separates experiments into three explicit levels, each chosen to match the change you are testing:
- Prompt experiments run a prompt in isolation against a dataset of known inputs and outputs. Fastest iteration loop, ideal for prompt tuning.
- RAG experiments test whether your retrieval system returns the right context for known queries. Useful for catching the silent failures where bad context produces confidently wrong answers. You can compare chunking strategies, embedding models, and hybrid vs near-text search as a first-class product surface.
- Agent experiments run the full agent end-to-end with known inputs, evaluating both the final output and the intermediate traces. The most expensive level, but closest to production reality.
Supervised evals in Arthur follow the same best practices as unsupervised ones (binary, specific, examples in the prompt), with the added advantage of access to a ground truth. That enables checks like SQL semantic equivalence, tool-sequence matching, and factual correctness against an expected answer.
The general guidance: start narrow with prompt or RAG experiments to find the right change, then validate end-to-end with an agent experiment before promoting. Braintrust can be manually wired up to support similar workflows, but Arthur brings all types of experimentation out of the box.
Guardrails
This is the clearest architectural difference between the two platforms.
Braintrust does not ship a native runtime guardrails feature. For runtime enforcement, Braintrust's recommended path is to integrate a third-party library (LLM Guard, NeMo Guardrails, Lakera, and others) and use Braintrust to monitor it. The enforcement itself lives in whichever library you choose.
Arthur ships native, in-line guardrails as part of the platform, with no third-party library required. Arthur supports two types:
Pre-LLM guardrails run before the user's input and assembled context are sent to the model:
- PII detection and redaction
- Sensitive data blocking (credentials, credit card numbers, proprietary data)
- Prompt injection detection
Post-LLM guardrails run after the model returns, before the response reaches the user:
- Hallucination detection
- Toxicity detection
- Tool and action validation
- Output format compliance
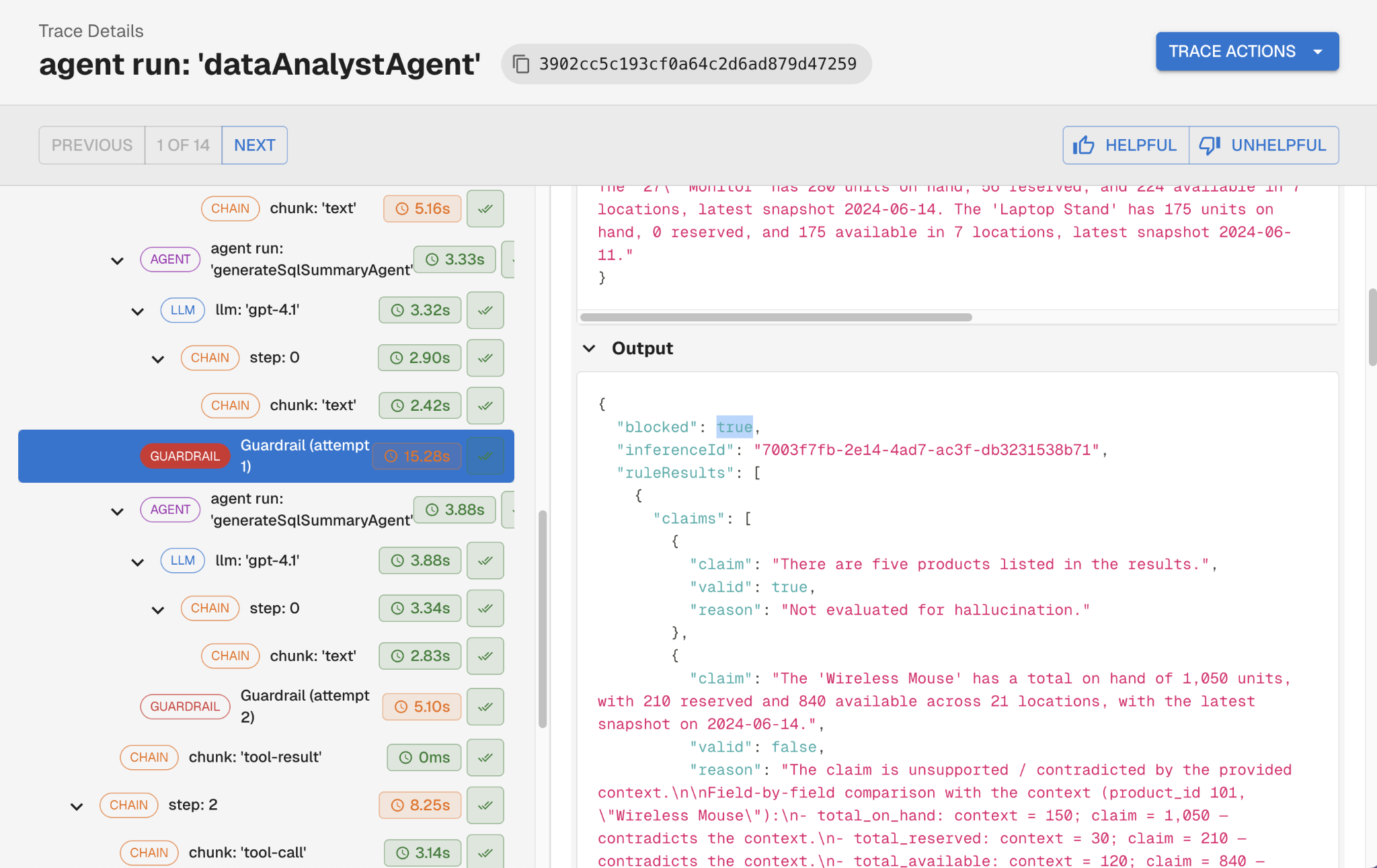
The more powerful pattern is using post-LLM guardrail failures as a self-correction loop. When a hallucination check finds an unsupported claim, instead of surfacing an error to the user, Arthur feeds the flagged content back to the LLM with a targeted correction prompt. The agent retries, the corrected output runs through the guardrail again, and the loop continues until the response passes or a retry limit is hit. The user only sees responses where every factual claim is grounded.
Two examples from Arthur customers: a major airline running a customer-facing support agent uses pre-LLM PII redaction so sensitive customer data never reaches an external model provider. Another customer uses the hallucination self-correction loop to catch unsupported claims and revise them mid-execution, turning what would otherwise be user-facing errors into a quality guarantee baked into the agent loop.
If real-time interception matters to your use case, and for any agent handling regulated data, Arthur provides this as a built-in capability.

Discovery and Governance
Braintrust does not provide any level of agent governance, policy management, and oversight over the large set of agents across your enterprise.
Arthur is designed with enterprise governance review in mind. Governance views surface, for each agent:
- Tools the agent can call
- Models and LLM providers it uses
- Data sources and retrievers it touches
- Subagents it delegates to
- Named owner accountable for compliance
Arthur also includes agent discovery that automatically finds agents emitting telemetry to centralized locations, so unregistered agents running outside governance controls are surfaced rather than going unnoticed.
This matters because shipping an agent into an enterprise environment means passing compliance review. Builders who instrument thoroughly, send traces to a centralized location, run continuous evals and guardrails, and assign clear ownership have a much smoother path to production approval. Arthur's governance layer is built around making that evidence easy to produce and inspect, which makes it a natural fit for regulated industries with strict compliance requirements.
Deployment, Architecture, and Ecosystem
Both platforms are open source, self-hostable, and integrate broadly across the LLM ecosystem (LangChain, LlamaIndex, OpenAI, and most major SDKs).
They both ship with a federated architecture separating the data plane from the control plane, making both a great option to deploy in a regulated environment.
When to Choose Which
Choose Braintrust if you want a focused, LLM observability and basic prompt management, you are comfortable assembling evaluation and guardrail logic from third-party libraries, and your primary needs are tracing, prompt versioning, and flexible scoring across datasets and production traces.
Choose Arthur if you are building agents headed for production and want an integrated toolkit that covers the full lifecycle in one place: OpenInference-native tracing, prompt templating with conditional logic, opinionated continuous evals, multi-level experiments (prompt, RAG, full agent), native pre- and post-LLM guardrails with self-correction, and built-in governance views. Arthur's federated data-plane / control-plane architecture also matters if your compliance posture requires that production inference data stay inside your VPC.
Interested in seeing Arthur in action? Book a demo with an AI expert