When Tokenmaxxing Backfires: Bringing AI Spend Under Control

The "Year of Agents" Met Its First Big Bill
For the last year, the message to enterprises was simple: adopt AI aggressively or get left behind. CEOs, boards, and investors pushed hard, and engineering teams responded by wiring agents and coding assistants into nearly every workflow they could find.
Now the bills are arriving.
According to Fortune, Uber burned through its entire 2026 AI coding tools budget in just four months after incentivizing employees to adopt the technology through an internal leaderboard. On a recent podcast, Uber COO Andrew Macdonald admitted he struggles to connect rising token spend to real outcomes: "If you're not actually able to draw a direct line to how many useful features and functionality you're shipping to your users, that trade becomes harder to justify".
Uber is not alone. Microsoft reportedly began canceling most of its direct Claude Code licenses, steering engineers toward its own tooling, with cost cited as a primary driver (The Verge). Meta quietly took down its internal "tokenmaxxing leaderboard," the very tool built to encourage employees to use AI more (TechFlow).
Across these companies, the question has shifted from "How powerful is our AI?" to "Is this spend actually worth it?"
What "Tokenmaxxing" Actually Is, and Why It Backfired
"Tokenmaxxing" is internal corporate slang for a management logic that took hold across the industry: since the company is paying for AI tools, employees should use them as much as possible. To push adoption, companies rolled out usage quotas, leaderboards, and even performance metrics tied to AI usage. Earlier this year, Nvidia CEO Jensen Huang famously suggested engineers should consume AI tokens worth at least half their annual salary each year to be fully productive.
The predictable happened. Employees leaned on high-effort, large language models for everything from trivial requests to large context coding tasks, with little regard for whether the task justified the cost. Usage numbers climbed, but the link back to real business value stayed thin.
The Hidden Math: Cheaper Tokens, Higher Bills
Even as the price per token falls, total spend keeps climbing. This is a typical case of the Jevons Paradox: when a resource gets more efficient and cheaper, people consume far more of it, not less.
Agentic AI compounds the problem because a single agent can consume up to 1,000 times more tokens than a one-shot LLM query. Multiply this across thousands of agents running across your organization, that per-task overhead scales into spend that no one budgeted for.
The spend does not stop at the token meter. Much of what coding agents produce still needs to be fixed, rewritten, or reviewed before it ships, and that overhead rarely shows up in the original budget. Meanwhile, the tools driving this usage are moving toward usage-based pricing, where costs scale directly with consumption. GitHub Copilot's shift to token-based billing left some developers watching their bills climb sharply overnight (TechCrunch), and Anthropic, similarly, has moved Claude Code toward charging per token of extra usage (Fortune).
Meanwhile, only 14% of CFOs say they can see clear, measurable returns on their AI investments (Forbes). Spend is rising, but few organizations can say where it goes or whether it is well spent.
The Governance Gap Behind the Cost Crisis
The underlying issue is not the technology. It is the lack of visibility and control.
Individual productivity gains do not automatically become business revenue. An employee may draft reports three times faster, while company revenue stays flat. Most enterprises have no real picture of what their employees are doing with AI, which models they are calling, or whether those tasks were meaningfully improved at all.
The problem gets worse when AI usage escapes sanctioned channels entirely. Consider a project like "Chipotlai Max," a meme coding agent that reverse-engineers a corporate customer-support chatbot to siphon free LLM access for coding tasks. It is a stark illustration of how AI usage can spin up outside any governance framework, consuming compute that no one approved and no one is watching.
This is the same pattern Arthur has been warning about with the rise of shadow agents. Agents now enter the enterprise from every direction: new applications built in-house, third-party SaaS products quietly adding agents under the hood, personal agent assistants, and standalone AI solutions adopted team by team. Without an inventory of what is running and a policy framework to govern it, cost and risk both compound silently.
You cannot govern what you cannot see, and most enterprises cannot see their agents, let alone control how much they spend.
How Arthur's ADG Platform Brings Token Usage Under Control
Arthur's Agent Discovery & Governance (ADG) platform was built to close this gap. Instead of treating cost as a finance problem to clean up after the fact, ADG gives teams the visibility and controls to manage usage at the source, across every environment where agents run.
Track Usage and spend. Arthur tracks token usage and spend across every model running in your organization, giving teams a clear view of which models, agents, and applications are consuming what. That same end-to-end observability into prompts, tool calls, decisions, and outcomes lets teams tie behavior to business-aligned reliability metrics and catch the loops, retries, and runaway sequences that quietly burn tokens.
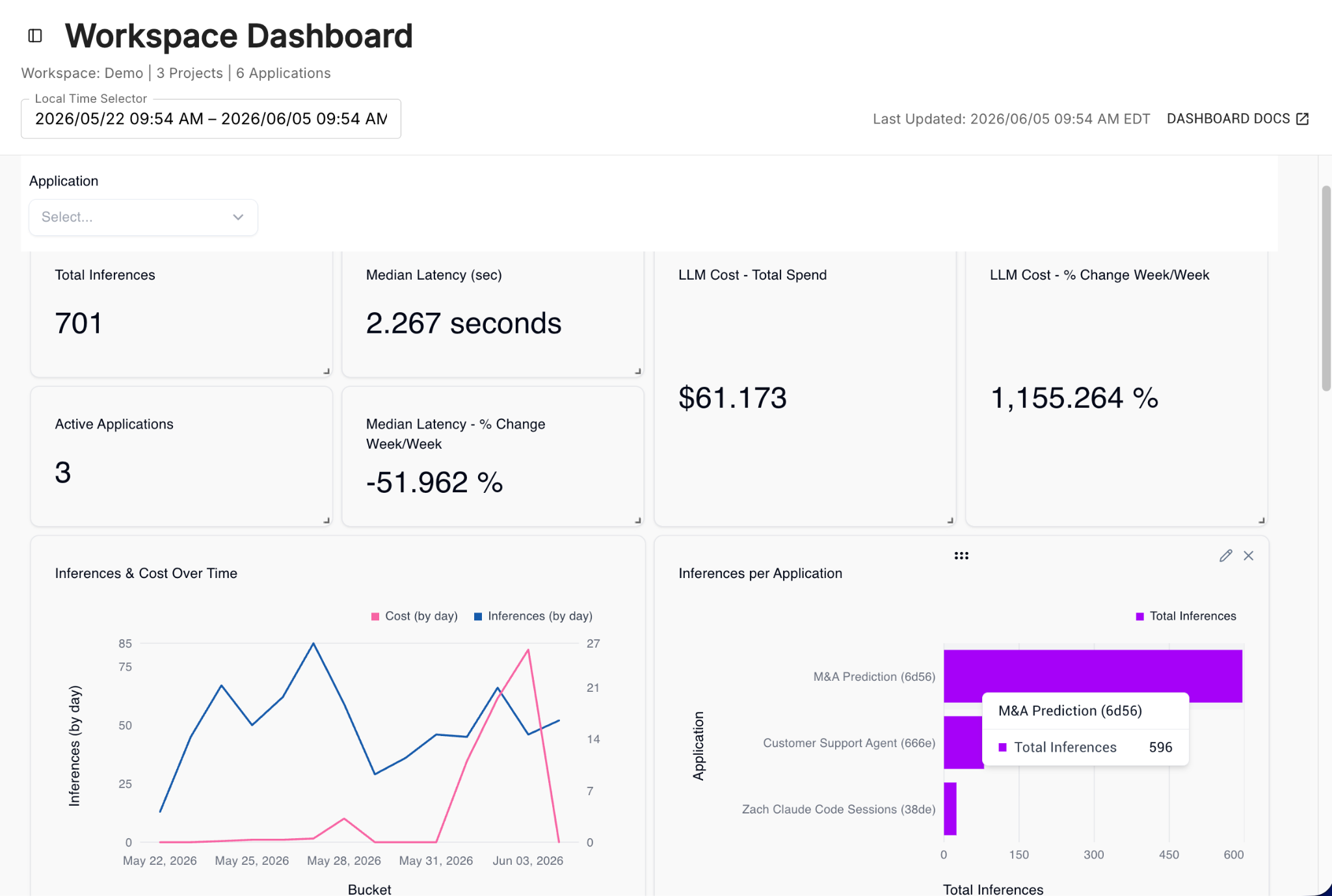
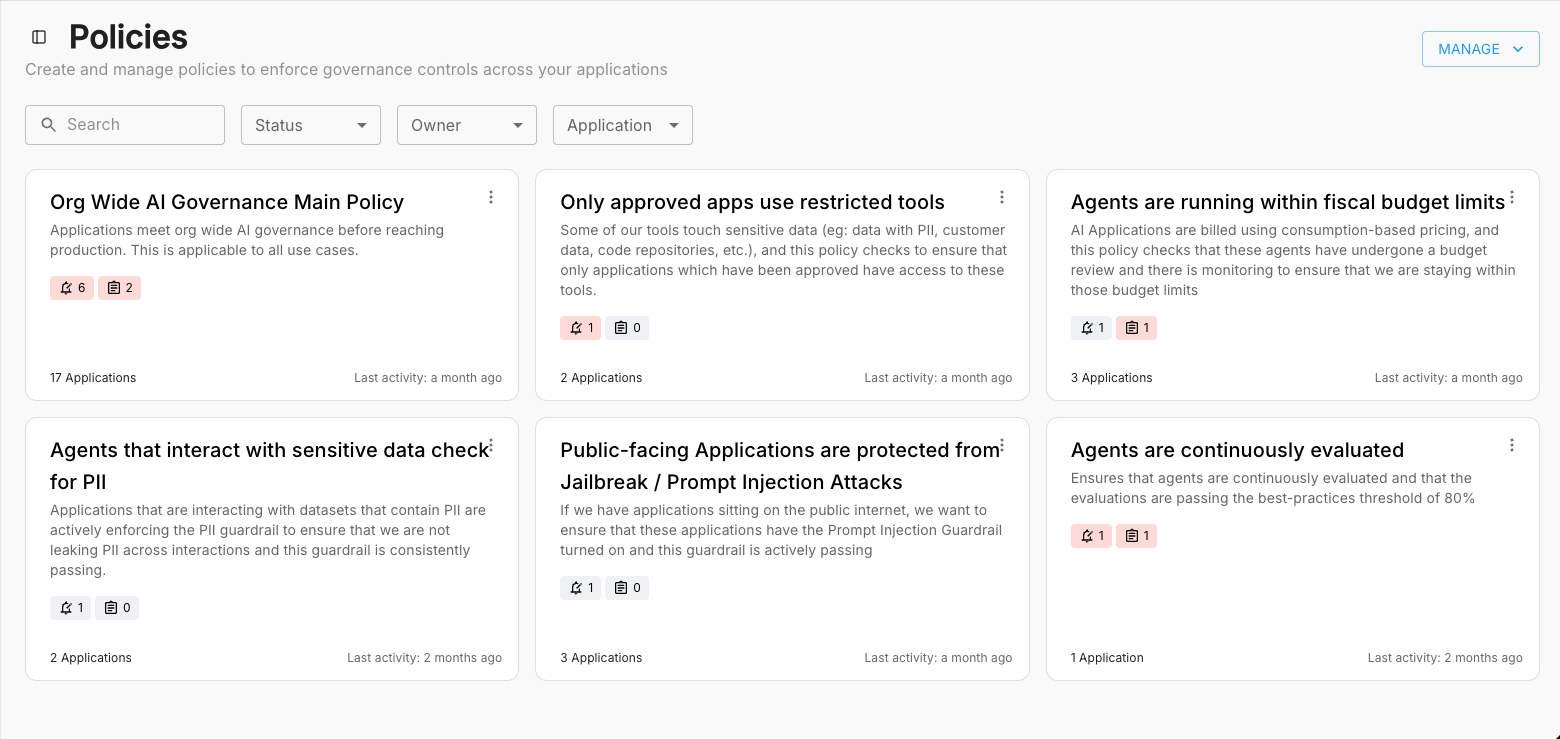
Policy enforcement. You can set financial caps on LLM spend, restrict which models and tools a given team or application is allowed to call, and trigger real-time alerts when usage turns inefficient or unauthorized. The result is a way to govern not just how agents interact with models, tools, and sensitive data, but how much they are allowed to spend doing it.
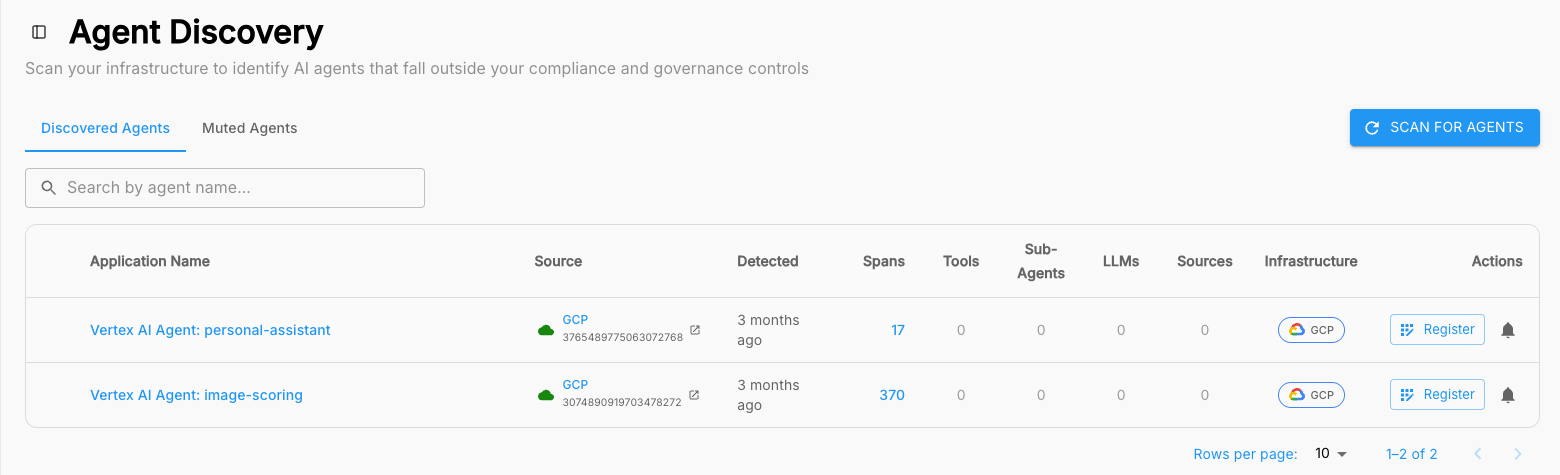
Automated discovery. Arthur automatically scans your compute environments to find and catalog every agent and AI application as it appears, no manual spreadsheets required. It uses a multilayered approach: listening to OpenTelemetry streams, monitoring MCP servers, analyzing network traffic for LLM signatures, and tapping the APIs of platforms like Vertex AI and Bedrock. That is how shadow agents and unsanctioned tools get surfaced before they become a budget line no one can explain.
Customizable, agnostic governance. One size never fits all. A customer-support agent needs different guardrails than an inventory or healthcare agent, and a Vertex AI deployment needs the same standard as one on Bedrock or LangChain. Arthur delivers a single, unified control plane with customizable, use-case-specific policies that work across providers and frameworks.
From Tokenmaxxing to Governed AI Spend
The lesson from Uber, Microsoft, and Meta is not that AI spend is bad. It is that ungoverned spend is impossible to justify.
Arthur's ADG platform gives engineering and product teams a way to keep innovating without the cost-and-risk hangover. Discover every agent, see exactly how it uses tokens, models, and tools, and enforce the policies that keep spend tied to outcomes.
Want to see how Arthur brings governance and visibility to your agentic ecosystem? Book time with an AI expert