
AI agents are running in production. They're making decisions, calling tools, handling sensitive data, and operating across organizational boundaries. But for most teams, the visibility into what's actually happening is thin. You can see outputs. Sometimes you can see latency. What you usually can't see is: which guardrail fired, why a trace looks wrong, whether a prompt injection slipped through, or whether one tenant's data touched another tenant's workflow.
That's not a monitoring gap. It's a trust gap.
This month, Arthur closed a lot of it. Across the Engine and Platform, June was defined by one theme: making your AI systems observable, governable, and trustworthy — from the guardrail that blocks a bad prompt to the compliance view that spans every workspace in your organization.
Here's what shipped.
A New Onboarding Experience
New users hitting a complex platform cold is a real problem. The guided tour system that shipped this month is the answer.
- Config-driven tour engine with persistence and analytics. Interactive overlays, progress tracking, and analytics instrumentation to guide users through platform workflows — and let them pick up where they left off.
- "Evals 101" task tour. A step-by-step walkthrough of experiment creation, dataset review, prompt engineering, and evaluation workflows.
- Auto-scroll for tour targets and checklist steps. Action elements automatically scroll into view during tours, accounting for side panel width, so users never lose their place.
- Onboarding checklist side panel with persistent collapsed state. Refactored into a clean side panel layout with draggable positioning; collapsed state is stored in local storage so it doesn't re-expand unexpectedly between tour sections.
- Demo completion certificates. Users who finish the introductory walkthrough get a permanent, shareable certificate link — persisted in Postgres and served via two new API endpoints — ready to post on LinkedIn or X.
- Onboarding form validation on blur. Text fields now validate as users complete each field, surfacing errors in the moment rather than all at once on submission.
- Onboarding tour moved to shared components. Tour engine, intro dialog, side panel, and spotlight widgets are now a shared library, enabling consistent onboarding experiences across all Arthur applications.
Check out the new onboarding experience →
Guardrails Go End-to-End
You've been able to configure guardrails. What you couldn't do was manage them from a single place, see them fire in trace context, or understand their performance over time. Guardrails were a setting, not a system.
That changes now.
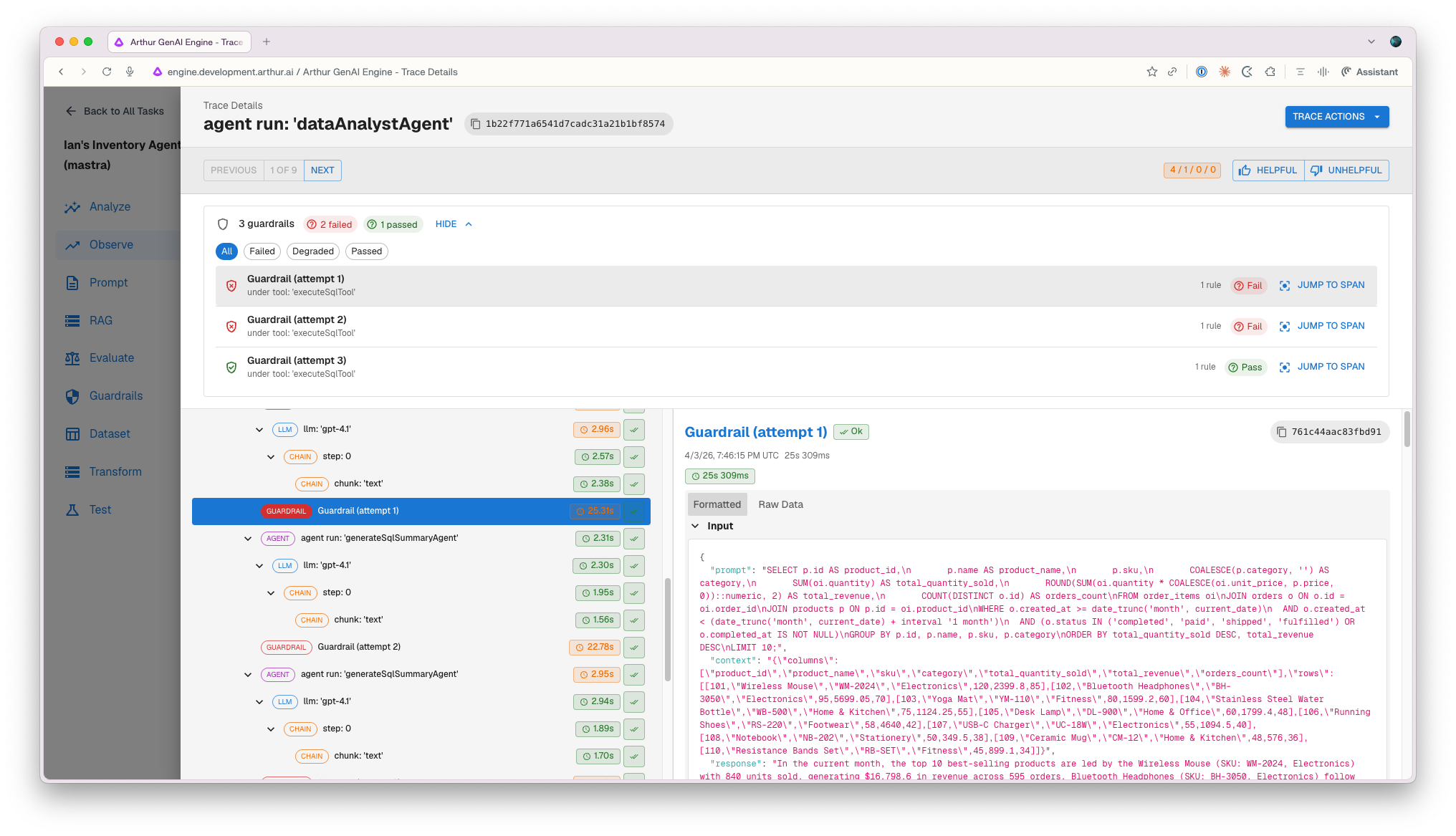
Guardrail management is now a first-class UI experience in Arthur Engine. You can create rules, view rule cards, test prompts against guardrail behavior, and carry saved configurations across sessions. And when a guardrail fires during a live interaction, you'll see exactly what happened — in the trace viewer, where it belongs.
- Full guardrails UI. Create rules, browse rule cards, list all active guardrails, and test prompts directly against guardrail behavior — no API required.
- Persistent guardrail state on tasks. Saved guardrail configurations now persist and carry across sessions in the Arthur Engine, in addition to being available within the Arthur Platform, ensuring your progress is maintained regardless of where you are working.
- Guardrail trace spans. Every guardrail execution now emits a trace span capturing timing and outcome for both prompt and response validation flows.
- Guardrail invocation visualization in the trace viewer. A new summary bar and per-invocation rows appear inside the trace drawer, giving you clear insight into which guardrails fired, what they returned, and when — without leaving the trace view.
- Standalone validation endpoint. A new /validate endpoint lets you test guardrail configurations against any prompt independently, without standing up a full pipeline.
- Improved PII detection accuracy. PERSON entity detections containing digits are now correctly dropped in V1, and V2 name validation has been tightened to reduce false positives.
- Consistent passport entity classification. PII V1 passport entities now route through GLiNER for model preparation, aligning with the shield implementation for seamless continuity during migration.
Organization-Level Governance Across the Platform
Compliance at the workspace level has always been possible. But the moment you have more than a handful of workspaces, navigating them one by one to understand your overall policy posture becomes unsustainable.
June introduced cross-workspace governance views in Arthur Platform.
- Organization-scoped policy assignments. A new endpoint aggregates policy assignment data across all workspaces in a single request, eliminating workspace-by-workspace navigation for admins.
- Organization-scoped compliance status. A unified read of compliance posture across the entire organization, gated by org-level permissions.
- Organization-level agent tools and LLM model governance. New endpoints sweep across all workspaces to surface agent-attached tools and models in a single request, with full org-level permission gating and row-level filters.
- Per-action RBAC gating across governance workflows. Create, edit, delete, assign, run compliance checks, and attest — all individually gated against a resource-level permissions matrix.
- Role-based governance personas. Governance Admin, Workspace Policy Manager, Policy Viewer, and Workspace Policy Assignment Manager each see only the actions appropriate to their role.
- Granular permissions gating on alert rules and attestation. Users without sufficient permissions no longer see action buttons they can't use.
- Configurable compliance time-window picker. Replace the previously hardcoded 30-day lookback with six relative presets (Month to date, Last 7 days, Last 90 days, and more) or a custom start date.
Alert Infrastructure That Tells You What Happened
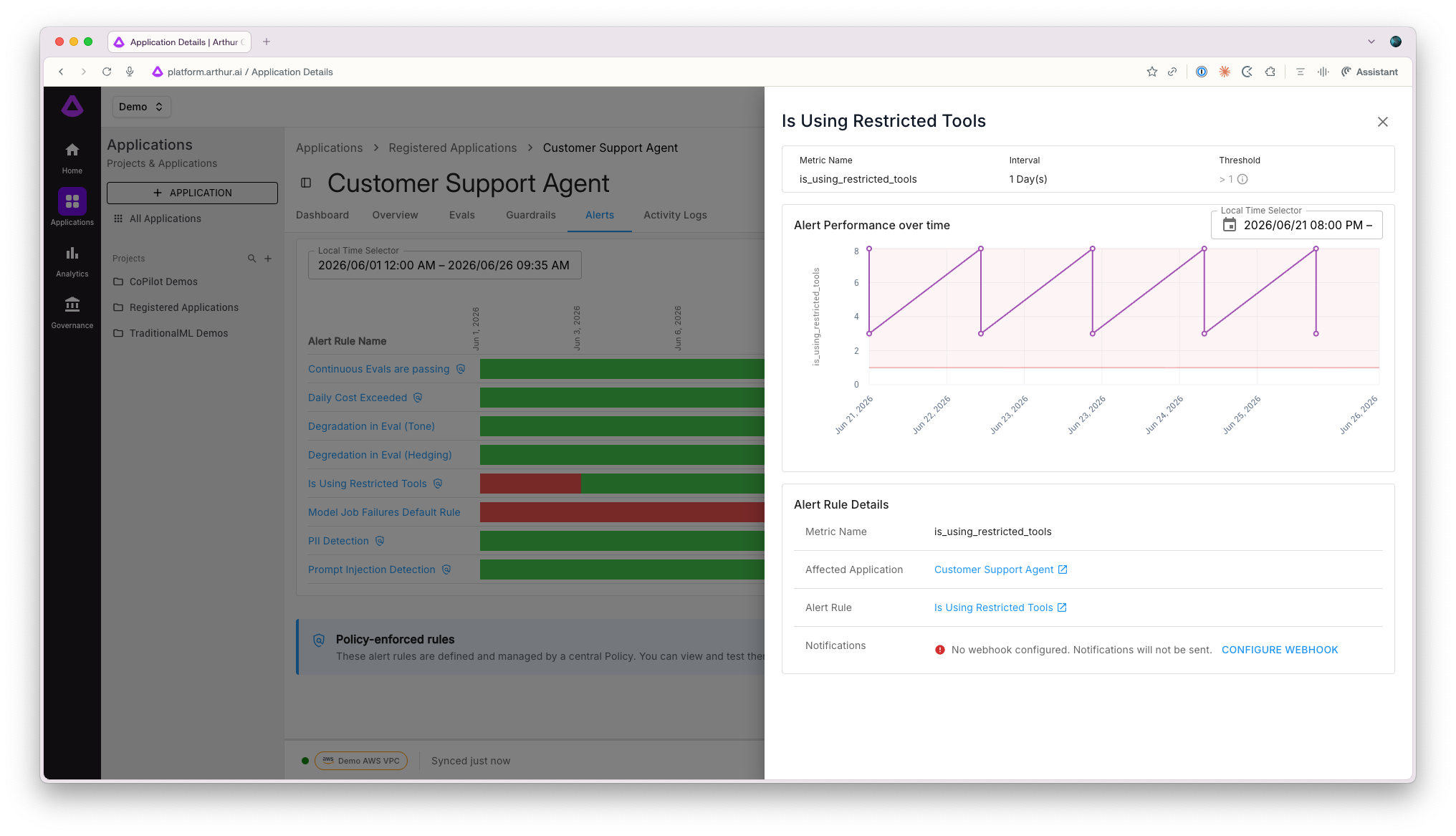
An alert firing is not enough information. You need to know: was this rule working last week? Has it been firing too often, or not at all? Is this a signal or noise?
June built the infrastructure to answer those questions.
- Alert rule logging infrastructure. New alert logs table and dedicated API routes for posting and retrieving alert log records, enabling historical audit trails of rule executions.
- Alert rule status logging in the Engine. Check results (okay, fired, or no data) are now recorded at regular intervals per model and rule, enabling trend analysis over time.
- Alert rule drawer. Click any alert in the timeline to open a dedicated side panel with rule details, performance metrics, and alert history — without navigating away.
- Navigate to alert rules directly from violations. The alert rule drawer is now accessible from the Current Violations tab, keeping context intact as you investigate.
- Dashboard performance fix for large alert datasets. Lazy-loading for the AlertsTimeline component and a new useInViewOnce hook eliminate tab crashes and UI freezes when rendering models with high alert volumes.
ML Evaluators, GCS/S3 Images, and Richer Datasets
Evaluation infrastructure is only as good as the data going into it and the scorers coming out. June made both more capable.
- First-class ML evaluator support. Built-in model-based scorers for PII detection (GLiNER + Presidio), toxicity classification, and prompt injection detection — unified alongside LLM evaluators with CRUD management, version control, and continuous eval integration.
- GCS image support for datasets. Automatically extract and convert Google Cloud Storage image URIs to base64 for display alongside other image formats in your datasets.
- S3 image support for datasets. Feature parity with GCS — reference and visualize images stored in S3 buckets when uploading datasets to the platform.
- Negative indexing for span value lookups and transform attribute paths. Access the last item in a collection with -1 without needing to know list lengths — works in both trace utilities and transform paths like .values.-1.content.
- Correct trace-to-dataset column schema display. When a transform is selected, the extraction preview now accurately reflects the dataset's columns with clear warnings about unmatched transform variables.
- Backend aggregation for task analytics. Task overview and analyze pages now compute metrics at the database layer — success rates use CE pass rate for accuracy, and time bucketing correctly uses start_time for historical graphs.
Azure, TLS, and Enterprise Connectivity
- Azure Blob Storage connector. Direct data ingestion and artifact storage from Azure environments, enabling Azure-native workflows in the Arthur Engine.
- Azure provider icon. Clear visual identification of Azure-backed models in the model providers UI.
- TLS private-cert support for LLM endpoints. Connect to HTTPS endpoints secured with private CA or self-signed certificates. Supply a cert bundle via download URL or optionally disable SSL verification — the certificate is downloaded at startup and threaded into all four LLM client constructors.
- Dashboard import/export. Export dashboards and import them into other workspaces, enabling template-based workflows and cross-environment consistency.
- TimescaleDB automated upgrade path. Automated migration support for the 2.14.2 → 2.27.2 upgrade path with lock-safe mechanisms, safety checks, and supervised reconciliation.
Bug Fixes and Quality-of-Life Improvements
A few important fixes that don't fit neatly into the larger narratives above:
- Workspace homepage permissions bug resolved. Removed a stale WorkspaceListAlertRules enum reference that was triggering a 422 retry storm on page load, causing the workspace homepage to freeze.
- Workspace model listing permissions corrected. Readers, policy managers, and engine workspace users can now access the list models endpoint without requiring governance admin privileges.
- Claude Code sub-agent span hierarchy fixed. Nested agent invocations are now correctly represented in trace views, with expanded test coverage.
- Tool execution spans restored in demo agent traces. Full visibility into tool invocations within trace visualizations is back.
- Prompts playground now shows assistant and tool messages correctly. Formatted display with tool call support and agentic workflow simulation via updated demo data.
- Validated user and chat user access restored. A regression from the multitenancy refactor that broke application-integration keys relying on VALIDATION-USER and CHAT-USER roles has been fixed.
- Dashboard edit isolation fixed. Editing cloned or template-based dashboards no longer inadvertently modifies the original.
- Upsolve export timezone handling corrected. All upsolve export dashboard timezones are now set to GMT/UTC, resolving timestamp-based filtering breakage.
- Span error panel added to trace UI. Parsed error messages from trace spans are now presented in a structured, dedicated panel — no more hunting through raw data.
June was a month about earning trust. Not through promises, but through isolation proofs, audit trails, and permission matrices. When you deploy AI in a regulated environment or share infrastructure across customers, "probably fine" isn't good enough.
P.S. — This one took some time to write because there was genuinely a lot to cover. The guardrails-to-trace-span pipeline and the multi-tenant isolation test suite were the two things I kept coming back to — not because they're flashy, but because they're the kind of unglamorous infrastructure work that makes everything else trustworthy. If you're building on Arthur right now and have thoughts on what we shipped (or what you wish we'd shipped), reply and tell us. We read everything.
See the full platform release notes for June 2026 here: https://docs.arthur.ai/changelog
— Arthur Team (team@arthur.ai)
SHARE



