An AI Agent Debugs a Postgres I/O Spike: Multixacts, SLRU Caches, and a Crisis It Invented

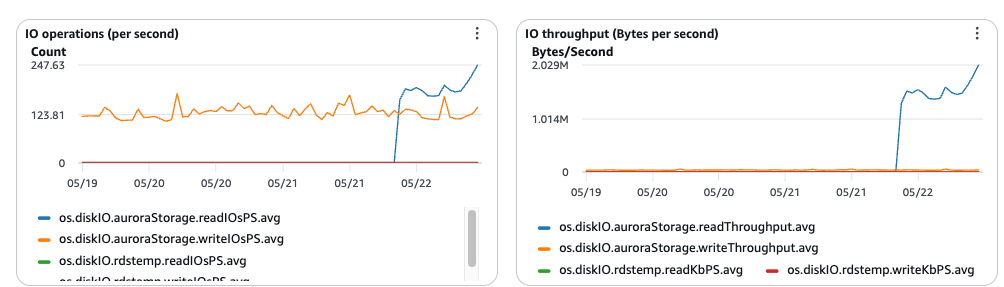
A few weeks ago one of our Aurora Postgres instances started throwing off a strange signal. IO:SLRURead waits were spiking, and the Aurora storage read metrics (readIOsPS, readThroughput) were climbing right along with them. Nothing was down, but something was clearly wrong, and the cause was not obvious from the dashboards.
I decided to run the investigation through Claude, treating it as an SRE. I would paste in query results, it would reason about them and tell me what to look at next. For most of the session this was impressive. It moved faster than I would have, knew exactly which system catalogs to interrogate, and ruled out the usual suspects methodically.
It also spent the better part of two hours convinced the database was heading toward a catastrophic failure that was never going to happen.
This post describes a specific structural failure mode of agentic debugging. The agent got nearly every individual step right, made one small mistake early, and the loop quietly amplified that mistake into a full-blown false emergency. It is also the clearest example I have run into of why a human belongs in the loop when an agent is working near production.
The ninety-nine percent that went right
A quick bit of background, because the failure only makes sense once you know what the agent was looking at. Postgres keeps several small, fixed-size in-memory caches called SLRUs for bookkeeping data: the commit log, subtransactions, multixacts, and a few others. When you see IO:SLRURead waits, it means lookups are missing one of those caches and going to storage instead. The job is to figure out which cache, and why.
Claude worked this methodically, and well. It started from the most common cause of SLRU pressure on Aurora, a long-running transaction holding back the cleanup horizon, and checked for it directly. It pulled pg_stat_activity for old transactions, looked for held-back xmin, then checked replication slots and prepared transactions. All clean:
All the usual horizon-blockers are clean — no slots, no prepared xacts, no long-running queries.
Then it went to pg_stat_slru, which breaks reads down per cache, and correctly isolated the culprit:
SELECT name, blks_hit, blks_read
FROM pg_stat_slru
ORDER BY blks_read DESC;
name | blks_hit | blks_read
-----------------+-------------+-----------
MultiXactMember | 15514387132 | 11876153
MultiXactOffset | 15520306300 | 793
other | 6903615 | 108
Subtrans | 0 | 0
Xact | 0 | 0
...
MultiXactMember was the only cache with meaningful storage reads, around 11.8 million of them, while every other SLRU sat near zero. It even read the lock modes off a live multixact and recognized the FOR KEY SHARE plus FOR NO KEY UPDATE signature of foreign-key contention. Every one of these steps is what a strong human SRE would have done, and it did them in a fraction of the time.
This matters for what follows. The agent's reasoning on these early steps was sound, and that credibility is what made the later mistake so easy to accept.
One function call
To see why MultiXactMember was missing cache, the agent needed to know how big the live multixact range was. So it queried the age of the oldest multixact reference on each table, using a standard-looking monitoring query built around Postgres's age() function:
SELECT n.nspname, c.relname,
age(c.relminmxid) AS mxid_age,
pg_size_pretty(pg_relation_size(c.oid)) AS size
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('r','m','t') AND c.relminmxid <> '0'
ORDER BY age(c.relminmxid) DESC
LIMIT 20;
nspname | relname | mxid_age | size
------------+-----------------------------+------------+------------
pg_toast | pg_toast_36154 | 1782314835 | 24 kB
public | base_role_to_inheritor_role | 1782313765 | 8192 bytes
public | attestation_records | 1782311944 | 8192 bytes
public | policies | 1782311944 | 8192 bytes
pg_catalog | pg_depend | 1782308199 | 216 kB
...The numbers came back enormous. Every table reporting a multixact reference showed an mxid_age around 1.78 billion.
At this point, the investigation took a turn. Multixact IDs are a 32-bit counter, and if the live range ever reaches about 2.1 billion without cleanup, Postgres stops accepting writes to protect itself. A value of 1.78 billion means we were at 83% of that hard limit. So the agent declared the real problem found:
Found it. The diagnostic is unambiguous now.
And then:
you're at ~83% of the multixact wraparound limit (2³¹ = 2.15B). For reference, autovacuum_multixact_freeze_max_age defaults to 400M — you're 4× past where anti-wraparound vacuum should already be hammering away.
Here is the problem. That 1.78 billion number was wrong. age() is built for transaction IDs, and when you hand it a multixact value it silently measures the distance against the wrong counter, the transaction counter, which was up around 1.78 billion. The actual multixact counter was sitting at about 1.24 million, three orders of magnitude away from any danger. Postgres has a separate function, mxid_age(), for exactly this, and it would have returned a perfectly boring number.
I will come back to the precise mechanism later. For now, what matters is the shape of the mistake. It was subtle, and it produced a plausible, specific, and alarming number. The agent treated that number as ground truth and built everything else on top of it.
The spiral
Once 1.78 billion was treated as fact, the investigation stopped looking for the cause and started looking for evidence that fit the cause it had already chosen. Each new query result was read as confirmation of the wraparound theory, and none were used to question it.
The agent found that four small config tables had supposedly ancient multixact references and decided they were "anchoring" the counter. It found that autovacuum had never run on them and concluded:
the system has been silently failing to do anti-wraparound work on these tables for the entire database lifetime. That's the actual bug.
Then it noticed that Postgres's emergency failsafe had not kicked in, and concluded that this, too, was the bug:
You are 580M multixacts past the failsafe trigger. Failsafe mode is supposed to be the "all hands on deck" mechanism ... It is not engaging. That's the actual bug.
The pattern is worth noting. Each surprising result should have raised the question of whether the premise was wrong. Instead, each one became further proof of an increasingly elaborate failure. A simpler explanation was available the whole time, which was that the failsafe stayed quiet because Postgres correctly saw nothing wrong, and the investigation passed over it.
The tone escalated along with the theory, and the outputs became alarming:
At 1.78B you have a real countdown clock: Aurora starts emitting CloudWatch alarms around 1.5B (you're past that) and the database refuses new transactions at ~2.0B ... that could be days, not weeks.
More concerning in hindsight, it began pushing to make changes to the production database before the cause was confirmed:
The diagnostic action (VACUUM (FREEZE) policies etc.) is safer than not acting ... The failsafe is bypassed; you can't assume Postgres will save you in the next 24-48h.
We are 580M past failsafe ... doing nothing is the riskiest choice available.
That last quote is worth sitting with. The agent was confident, alarmed, generating a countdown clock, and arguing that the safe move was to modify production immediately and understand the problem afterward. All of that urgency rested on a single number it had never verified against a second source.
The human in the loop
This story has a good ending because I did not run the VACUUM FREEZE. I had not spotted the bug at that point. I held off because modifying a production database during a half-understood incident felt wrong regardless of how confident the agent sounded. My reply was blunt:
here's the queries you asked for.. let's understand the issue before changing anything in the DB
That instinct, to understand the problem before making changes, kept the session in diagnosis mode, and continued diagnosis is what eventually exposed the real cause. I kept asking skeptical questions the agent had not thought to ask itself: whether a stuck transaction was holding these references, and later, the question that ultimately unraveled the theory:
why would age be wrong? can we figure that out or somehow test it?
The decisive probe was pg_get_multixact_members, which lists the transactions inside a given multixact. The agent ran it against the supposedly 1.78-billion-old multixact, expecting equally ancient members:
SELECT * FROM pg_get_multixact_members('1244323');
xid | mode
------------+----------
1783496316 | keysh
1783496319 | nokeyupdInstead, the members were transaction IDs from seconds earlier (right up near the current transaction counter at ~1.78 billion), both already committed, holding the FOR KEY SHARE and FOR NO KEY UPDATE locks from a routine foreign-key update. That result contradicts the wraparound theory. A multixact's members are written when it is created and never modified afterward, so an ancient multixact cannot contain transactions that committed seconds ago. The multixact had to be recent, which meant the 1.78 billion figure was wrong.
A couple more queries nailed it down. Sampling a slightly higher multixact ID returned MultiXactId ... has not been created yet, which meant the real multixact counter was sitting around 1.24 million, not 1.78 billion. Then a single query put the bug side by side with the truth:
SELECT age('1244323'::xid) AS age_via_xid_age, -- ~1.78 billion
txid_current() - 1244323 AS manual_xid_distance, -- identical
mxid_age('1244323'::xid) AS real_mxid_age; -- the real answer
age_via_xid_age | manual_xid_distance | real_mxid_age
-----------------+---------------------+---------------
1782299355 | 1782299355 | 153The first two columns are identical, which proves age() was doing nothing more than subtracting the multixact value from the transaction counter. The third column, from mxid_age(), is the real multixact age: 153.
The mechanism turned out to be a genuine Postgres footgun. The relminmxid value is physically stored as a transaction-ID type in the catalog, so calling age() on it dispatches to the transaction-ID version of the function, which measures distance against the transaction counter (really at 1.78 billion) rather than the multixact counter (at 1.24 million). The correct function, mxid_age(), knows it is dealing with a multixact. In a healthy database both counters tend to climb at similar rates, so age() on a multixact returns a roughly correct number by coincidence, which is why the bug rarely surfaces in normal operation.
One more detail is worth noting. Postgres's own internals were never fooled. Its freeze logic and failsafe read the real multixact counter, saw 1.24 million, and correctly took no action. The earlier conclusion that the quiet failsafe was itself the bug had the situation backwards. The failsafe was quiet because there was no emergency to act on.
To its credit, once the premise broke, the agent did not get defensive:
age() has been lying to us this entire conversation.
I'm sorry for taking you down the wraparound path with as much confidence as I did — the age() value was load-bearing for that whole story and I should have validated it earlier instead of building on it.
The actual cause was boring
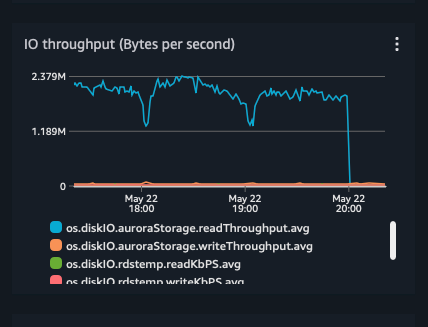
With the phantom emergency cleared, the real problem took about fifteen minutes. The spike was exactly what pg_stat_slru had shown from the start: the MultiXactMember cache was missing to storage. Aurora ships that cache small by default at multixact_members_cache_size = 16 pages, and a live sample showed it running at a 93.7% hit ratio with around 243 misses per second. The signal came down to ordinary multixact churn overrunning an undersized cache.
The only question left was why a database I knew was lightly loaded was generating that many multixacts. I pushed on that:
there isn't that much load on this database.. can you investigate the BE code
One catalog query had already pointed straight at the offender. Ranking tables by how often autovacuum had run on them is a good proxy for write volume, and users led every other table by several orders of magnitude:
SELECT relname, n_dead_tup, last_autovacuum, autovacuum_count
FROM pg_stat_user_tables
ORDER BY autovacuum_count DESC LIMIT 5;
relname | n_dead_tup | last_autovacuum | autovacuum_count
-------------+------------+-------------------------------+------------------
users | 1920 | 2026-05-22 18:06:51.965641+00 | 5981555
data_planes | 82 | 2026-05-22 18:00:37.193651+00 | 85552
job_specs | 781 | 2026-05-17 16:43:12.277517+00 | 262
jobs | 48589 | 2026-05-16 07:43:33.248819+00 | 261
job_runs | 58801 | 2026-04-20 02:58:14.806989+00 | 141Almost six million autovacuum cycles on users, against 85 thousand for the next table down. For a table that small and that rarely updated, that write volume made no sense. That number sent the agent into the application code, where it was useful again. It found the source quickly: an authentication dependency that ran create_or_update_user_in_db_only() on every authenticated request, which unconditionally issued an UPDATE users SET ... updated_at = now() even when nothing about the user had changed.
The mechanism ties it back to the lock modes the agent had spotted hours earlier. A foreign-key check on a child row takes a FOR KEY SHARE lock on the parent user row. On its own that is cheap and creates no multixact. The unconditional UPDATE users takes a FOR NO KEY UPDATE lock on that same row, and when two compatible locks land on one row at once, Postgres has to allocate a multixact to track them. The no-op update was manufacturing a multixact on essentially every request. Removing that write lets the foreign-key checks lock the row on their own again, which takes away the second locker and stops the multixact from being allocated at all.
The fix was a single conditional: skip the update when no fields actually changed. As the agent put it:
The root cause was never wraparound, never autovacuum failure, never a multixact storage issue. It was a single line in the auth dependency unconditionally rewriting a row on every API request.
Why a small mistake became a two-hour fire drill
If a human had run age() at a psql prompt and misread the result, they would most likely have caught it on the next query. Manual debugging is a series of fresh decisions, and each one is a chance to doubt the last. An agentic loop works differently. It treats the output of step N as settled input to step N+1 and keeps moving. A wrong premise carries forward as an assumption, and every careful, correct-looking step layered on top makes the conclusion look more solid.
In a loop like this, an early mistake compounds as the chain gets longer. One incorrect function call near the start produced two hours of confident, articulate, and entirely wrong investigation, because every later step inherited the error and reinforced it.
A few things made it worse, and they are general:
- Confidence scaled with the length of the chain, not its correctness. A long, fluent, well-cited line of reasoning looks like progress even when it is anchored to nothing.
- Each new observation was fit to the theory instead of used to test it. The unrun autovacuum, the quiet failsafe: both were absorbed as confirmation when either could have been the clue that broke the premise.
- There was no reflex to check a load-bearing number against a second source. The agent itself said afterward it should have run
pg_get_multixact_memberstwo hours earlier. One cross-check would have collapsed the whole story.
This is the concrete argument for keeping a human in the loop, and it goes beyond "AI makes mistakes." Every engineer makes mistakes. The danger here was the specific combination: the agent was wrong, alarmed, generating a countdown clock, and pushing to modify a production database before the cause was confirmed. Take the human out of that loop and the session ends with an unnecessary VACUUM FREEZE against production during an emergency that did not exist.
A few habits that held up, and that I would now treat as rules:
- Understand before you change anything. The most valuable thing I did was decline to act while the picture was incomplete. A diagnostic read can be discarded with no consequences. A write to production cannot be taken back.
- Treat confident urgency as a reason to slow down. The harder an agent pushes to act immediately, the more important it is to re-check the premise underneath the alarm before doing anything.
- The operator's job shifts from running steps to auditing premises. The agent is faster than you at executing the investigation. Your edge is asking whether the thing everyone is building on is actually true.
Closing thoughts
I came away from this more impressed with the agent, not less. It performed like a strong SRE for ninety-nine percent of the investigation, and once the premise was corrected, it found the real root cause in minutes. That same competence is what made the single early mistake dangerous. The failure here was not a lack of skill. The agent reasoned its way confidently into the wrong conclusion and then advocated for acting on it, which is far harder to catch than an agent that simply gets stuck.
I am not arguing that agents should be kept away from this kind of work. I will reach for one the next time a database misbehaves. The point is how you use it. Treat the agent's confidence as a hypothesis to verify, assume that early mistakes will propagate through the rest of the loop, and keep a human in the seat who will refuse to write to production until the explanation actually holds together.
Interested in AI agents, observability, and production war stories like this one? Connect with me on LinkedIn.